交大ACM班毕业生在Google的新工作:帮你自动写Excel的表格公式,准确率57.4%!

新智元报道
新智元报道
来源:Google AI
编辑:LRS
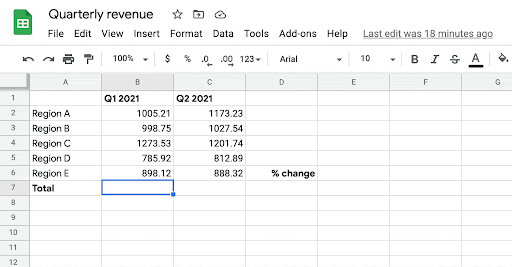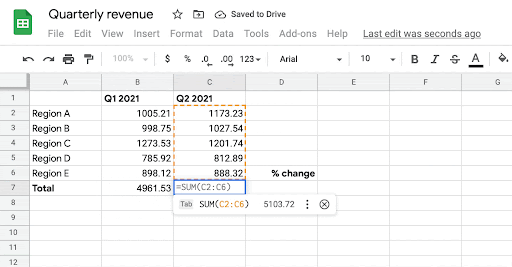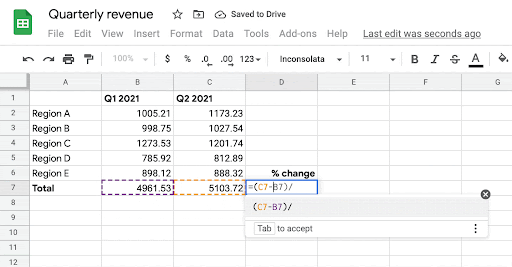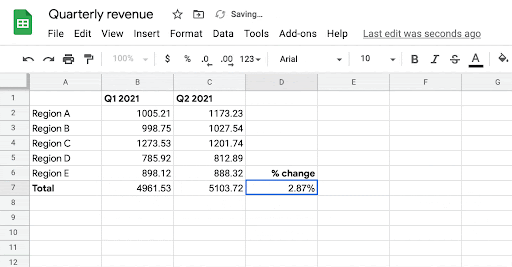
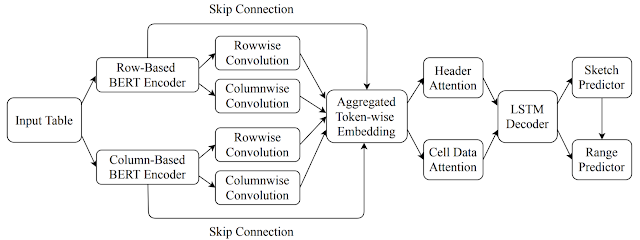
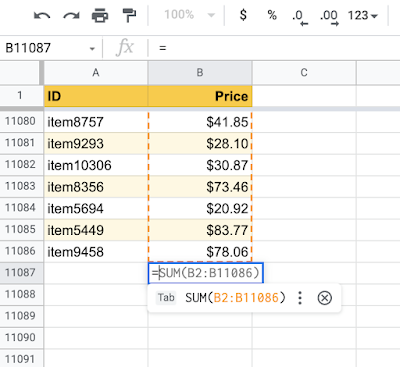
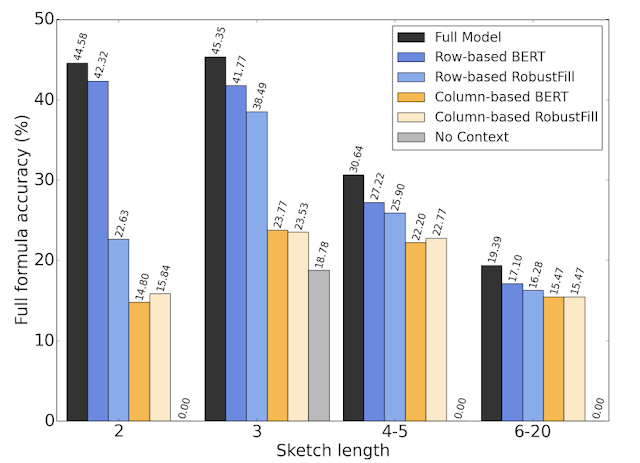
【新智元导读】表格版的公式生成器来了!交大ACM班毕业生,伯克利博士陈昕昀在Google带来了她在ICML 2021的新工作,能够自动帮你补全公式,准确率在测试阶段已达57.4%。目前Google Sheets已上线该功能,快去试用吧!
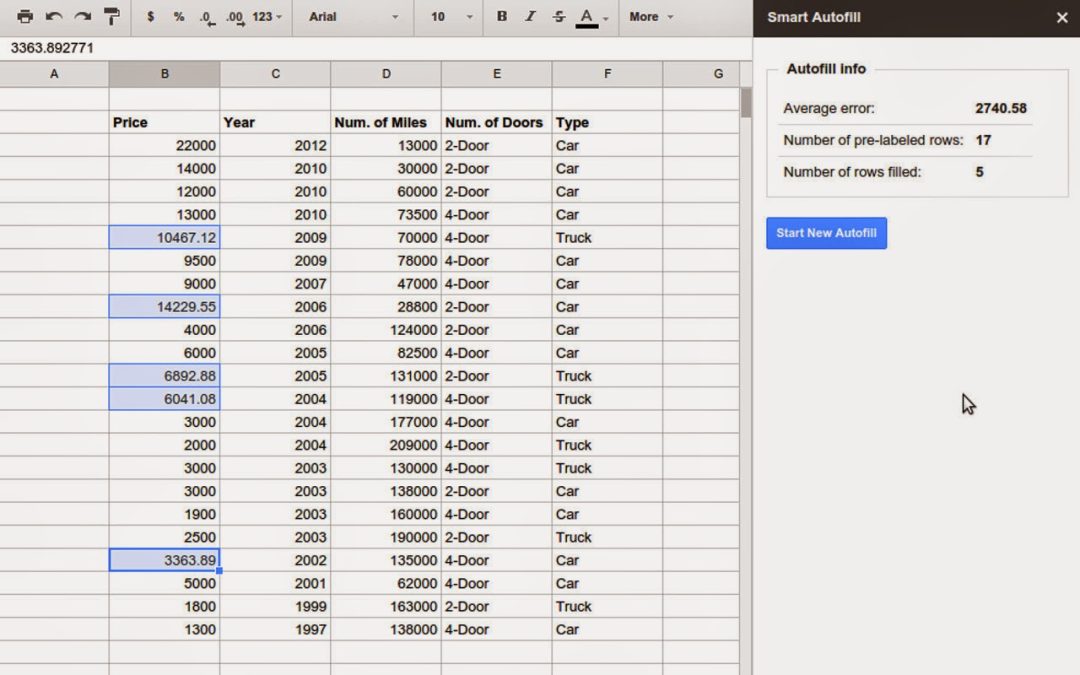


运算符序列(例如,sum、if等);
应用运算符的表格范围(例如A2:A10)。
参考资料:
https://ai.googleblog.com/2021/10/predicting-spreadsheet-formulas-from.html

登录查看更多
相关内容

【AAAI 2022】机器学习模型的解释方法效果如何?MIT、微软学者为你解读,Do Feature Attribution Methods Correctly Attribute Features?
专知会员服务
31+阅读 · 2022年3月12日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月16日
Arxiv
1+阅读 · 2022年4月15日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日


相关VIP内容
【AAAI 2022】机器学习模型的解释方法效果如何?MIT、微软学者为你解读,Do Feature Attribution Methods Correctly Attribute Features?
专知会员服务
31+阅读 · 2022年3月12日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月16日
Arxiv
1+阅读 · 2022年4月15日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日