CVPR 2019 | 针对人脸识别系统的高效黑盒对抗攻击算法

本工作提出了一种高效的基于决策的黑盒对抗攻击算法,在业内第一次以完全黑盒的方式成功地实现对人脸识别系统的对抗攻击。本工作由腾讯 AI Lab 主导,与清华大学,香港科技大学联合完成,发表于 CVPR 2019。


背景
在图 1 示例中,我们用同样的一个人脸识别模型(Arcface [1])对两幅看起来一模一样的人脸图像进行识别,但是得到了完全不同的两个识别结果。这是为什么呢?原因是右图的人脸区域被加上了人眼无法察觉的恶意噪声,专门用于欺骗人脸识别模型。这种现象叫做对抗样本,即针对某种特定的模型(例如图像分类模型 ResNet [2]),在正常样本(例如 2D 图像,3D 点云等)上加入微小的噪声,使得模型原来的结果发生改变。

对抗样本现象揭示了机器学习模型尤其是深度学习模型的安全漏洞,近年来引起了学术界和工业界的广泛关注。研究人员已经开发了针对深度学习模型的诸多对抗攻击算法,最常见的例如 FGSM [3], PGD [4], C&W [5] 等。但是,这些方法都要求获取被攻击模型的全部结构和参数,这种攻击场景被称作白盒攻击。
但是在现实场景下,攻击者是很难获取被攻击模型的参数甚至结构的,只能够获取被攻击模型的输入结果。这种攻击场景被称为黑盒攻击。根据所获取模型输出的类型,又可细分为1)基于分数的黑盒攻击,即能够获取模型输出的后验概率或者分数(例如人脸比对的相似度分数),2)基于决策的黑盒攻击,即只能获取模型输出的离散类别。很显然,离散类别提供的关于模型的信息更少,基于决策的黑盒攻击难度也最大。相对于白盒攻击算法,基于决策的黑盒攻击算法非常少,而且攻击效率不高。
针对这个难题,我们提出了一种新的搜索算法,充分利用了模型决策边界的几何结构和进化算法思想 [6],大大提高了攻击效率。
针对人脸比对模型的攻击问题建模
我们将人脸比对模型表示为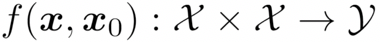
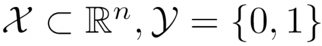
表示参考人脸图像,x 表示目标人脸图像;
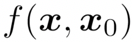
是否为同一个人,如果相同,则返回 1,否则返回 0。
我们的攻击任务是在目标人脸图像 x 的基础上构造一个对抗人脸图像 ,使得其与参考人脸图像
的比对结果发生改变(即
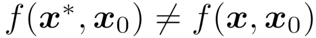
与 x 的视觉差异尽量小。该任务可以建模为以下优化问题:
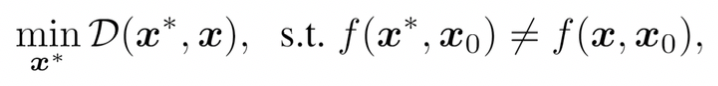
其中,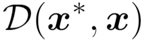
在人脸比对场景中,根据 x 和 是否为同一个人,上述攻击任务还可以细分为以下两种攻击:
1. Dodging 攻击:当 x 和 为同一个人的两张不同人脸图像时,即
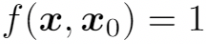
被识别为不同于
的人,即
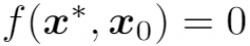
2. Impersonation 攻击:当 x 和 为不同人的人脸图像时,即
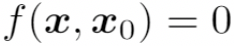
被识别与
是相同的人,即
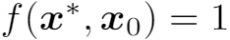

优化算法
在上述优化问题中,由于人脸比对模型 f(·,·) 是未知的,我们无法对其进行求导。因此常用的连续优化算法(比如梯度下降法)都不适用。
我们提出了一种基于进化思想的高效搜索算法。我们以图3作为示意图来说明我们算法的主要思想。其中,黑色圆点表示目标图像 x;蓝色曲线表示决策边界(注意,这条曲线实际是不可见的),曲线的上方是不可行域(即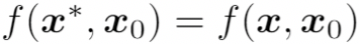
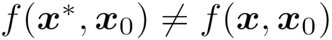
1. 以图 3 左子图为例,为了探索下一个可行解,我们需要进行采样。黑色椭圆表示采样概率分布,其服从高斯分布。该分布的中心点为当前可行解,协方差矩阵是则是根据历史可行解进行估计的,其基本思想是:根据历史探索点,我们可以计算出各个方向的探索成功率;沿着成功率大的方向继续探索,更容易找到下一个可行解。因此,我们根据该分布进行第一步采样,如从绿色圆点出发的第一个橙色箭头,到达初始候选解(第一个橙色圆点)。
2. 经过第一步采样,我们可能找到下一个可行解,但是并不能保证
3. 随后,我们在对第二个候选解进行查询,判断其是否满足约束:如果满足,则将其作为最新可行解,如图 3 右子图所示,并对采样概率分布(即黑色椭圆)进行更新;如果不满足,则保持当前解不变,重新上述采样过程。
在上述搜索算法中,我们将图像的每个像素当作一个维度。整个搜索空间的维度非常高,这往往意味着搜索效率非常低。为此,我们在搜索中嵌入了两种加速策略:
1. 随机坐标采样:即每次采样只在部分维度(即部分像素)进行,而不是所有维度。维度的选取以采样概率分布为依据,方差大的维度被选中的概率也更高。
2. 维度降采样:我们假设对抗噪声在像素坐标系中也是空间平滑的,即相邻像素的对抗噪声相近。因此,我们均匀间隔地选取一部分像素作为我们搜索的子空间;但在子空间中找到一个候选解(即候选对抗噪声)时,我们根据像素的空间坐标进行双线性插值,得到一个全空间的候选解。
上述算法的全部流程总结在图 4 中。
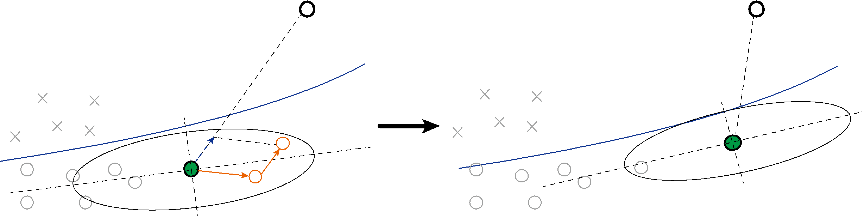
▲ 图3. 算法示意图

实验结果
实验一:我们首先对 ArcFace 人脸识别模型进行了基于决策的黑盒攻击,其攻击效果如图 5 所示。无论是 Dodging 攻击还是 Impersonation 攻击,随机攻击次数的增加,对抗噪声越来越小,直至人眼无法察觉。每幅图下方的数字代表其包含的对抗噪声的 L2 范数。

▲ 图5. 对ArcFace模型的黑盒攻击结果
实验二:对比攻击实验。我们选取了几种最新的基于决策的黑盒攻击算法,包括Boundary [8], Optimization [9] 和 NES-LO [10]。虽然这几种方法都是为攻击一般图像分类模型而设计的,但是也很容易改造为对人脸识别模型的攻击,即替换约束条件。我们对当前最流行的三种人脸识别模型上进行了攻击,包括 SphereFace [11], CosFace [12] 和 ArcFace [1]。
实验结果如表 1 所示,在相同查询次数下,我们所提出的进化攻击算法所得到的对抗噪声明显小于其他对方方法的噪声。在图 6 中,我们还展示了噪声水平随着查询次数的下降曲线,我们方法的下降曲线明显快于其他对比方法。这些对比结果表明,我们的进化攻击算法的效率远远好于已有黑盒攻击算法。
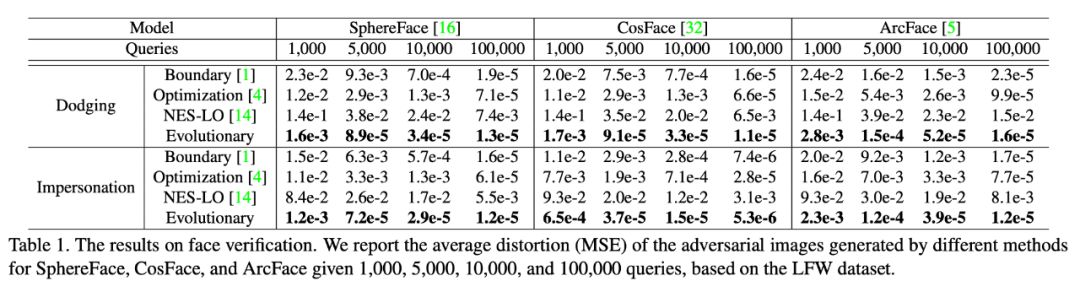
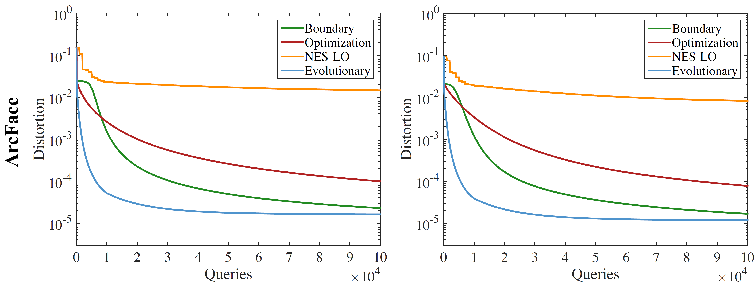
▲ 图6. 对ArcFace模型的黑盒攻击的噪声下降曲线
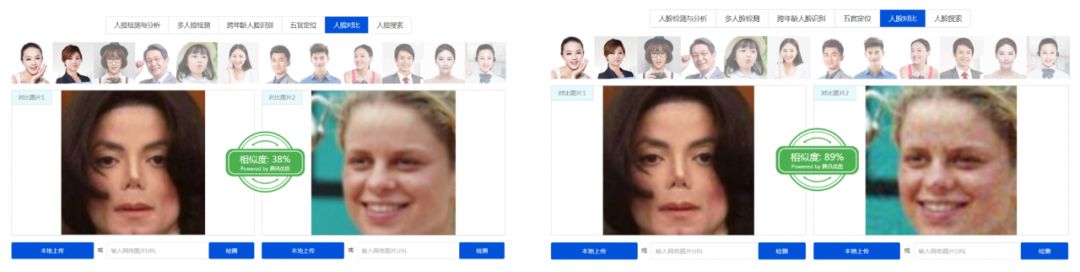
实验三:对人脸识别 API 的黑盒攻击实验。很多人工智能公司都提供了人脸识别接口,可以通过访问 API 的形式获取人脸识别结果。我们选择了腾讯 AI 开放平台上的人脸比对接口(https://ai.qq.com/product/face.shtml#compare)进行了测试。该接口可以返回人脸比对的相似度。但是,我们以 90% 为界限,超过则比对成功,即返回 1,否则返回 0。我们只根据查询返回的 0 或者 1 来优化对抗噪声。
实验结果如图 7 和图 8 所示,我们的算法可以轻松欺骗该人脸比对系统;在同样查询次数下,我们算法得到的噪声图像,比对比方法得到的噪声图像,更加接近于目标图像,即噪声水平更小。

总结与思考
本工作的意义,不仅仅在于第一次成功地以完全黑盒地方式实现了对人脸识别系统的攻击,更是为当前十分火热的人脸识别敲响了警钟。考虑到人脸识别系统的广泛应用场景,比如门禁,海关,支付等,我们应该对人脸识别系统的安全漏洞更加重视。我们不仅要尽可能多地探测人脸识别系统的漏洞,更要及时找到弥补漏洞的方案,不断提高人脸识别系统的安全性,使得人脸识别的应用更加安全可靠。
参考文献

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文

