AAAI 2020 | 滴滴&东北大学提出自动结构化剪枝压缩算法框架,性能提升高达120倍
机器之心发布
机器之心编辑部
2020 年 2 月 7 日-2 月 12 日,AAAI 2020 将于美国纽约举办。不久之前,大会官方公布了今年的论文收录信息:收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。本文介绍了滴滴 AI Labs 与美国东北大学合作的一篇论文《AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates》

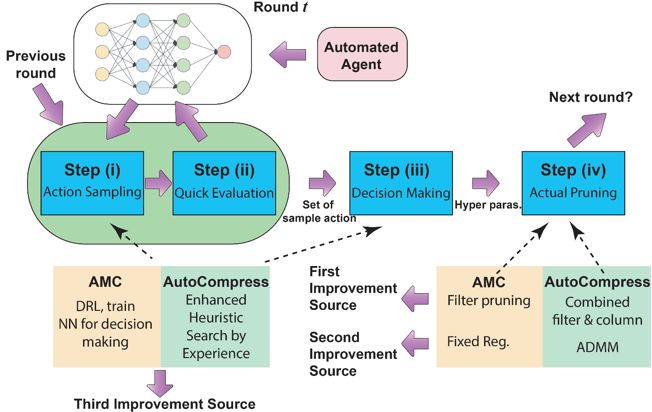
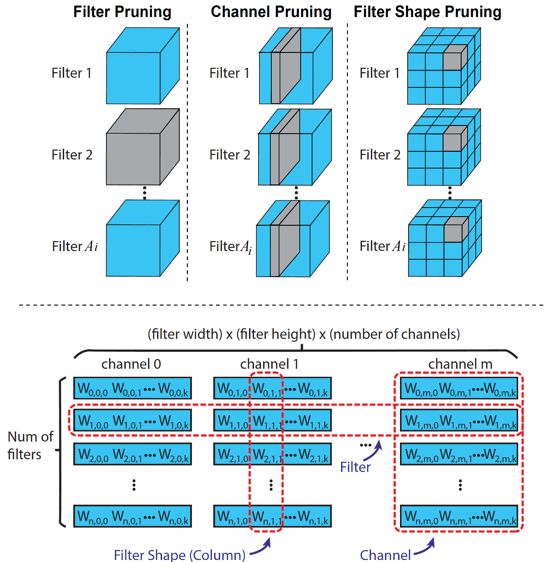
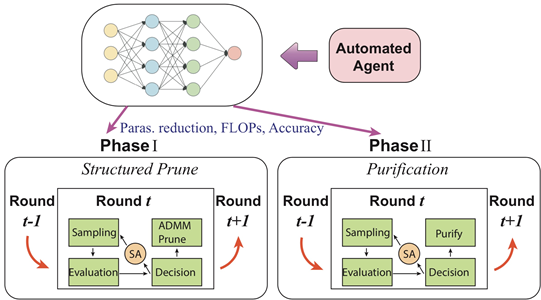
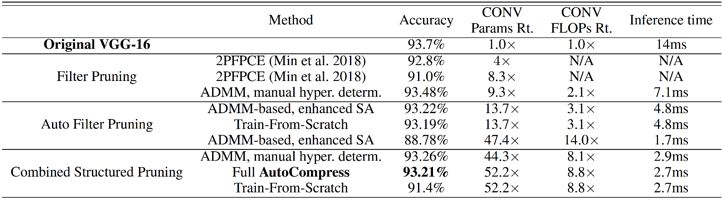



登录查看更多
相关内容

专知会员服务
36+阅读 · 2019年11月15日
Arxiv
4+阅读 · 2018年3月30日
Arxiv
4+阅读 · 2018年1月11日


相关VIP内容
专知会员服务
36+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年3月30日
Arxiv
4+阅读 · 2018年1月11日