FastBERT-CPU推理加速10倍

论文标题《FastBERT: a Self-distilling BERT with Adaptive Inference Time》。
关于这个论文已经有不错的解读了,所以我写的侧重点可能和别人的不太一样,具体的往下看吧,欢迎讨论。
这个论文从两个方面去掌握:
-
样本自适应推断:使用不确定性指标(a normalized entropy)去过滤样本;
-
模型自蒸馏:分支网络分类器学习主干网络分类器,并使用KL散度进行度量;
然后我们聊一聊 FastBert 究竟在做什么事情?
Bert本身有12层,模型在进行推理的时候, 每一个样本都会完整的走过12层。而 FastBert 做到了让简单的样本的不必走过12层,只需要走过3层或者4层(这个数字并不确定)就可以。
仔细想一下这个过程,简单来讲,就是杀鸡不要用牛刀,一件很简单的样本,不值得我们调用12层去搞定它,3层transformer学的参数就可以消灭掉这个样本。
1. 整体过程
整个过程分为三步:
-
微调主干网络:使用自己下游数据微调主干网络。 -
自蒸馏:可以使用无监督数据,用KL散度度量每一层和最后一层分布距离,并使用和作为损失。交叉熵也没差,H(p)不变,两者等价。 -
自适应推理:自己设定速度(阈值),大于这个的往后走,小于这个的输出结果。
2. 需不需要自蒸馏
但是,看到这里,我们肯定会有一个疑问。
基于“杀鸡不用牛刀”的想法,我可以简单改造 Bert 模型,在每一层都加一个分类器,使用我自己的下游数据训练模型就可以了,损失函数直接使用每一层的交叉熵损失之和就可以了,为什么需要用到自蒸馏呢?
简单来说,就是我完全可以不需要使用自蒸馏就可以达到同样的目的。
基于这一点,作者有做一个实验对比,得出的结论就是没有自蒸馏,会导致精读的降低。
具体看这个图:
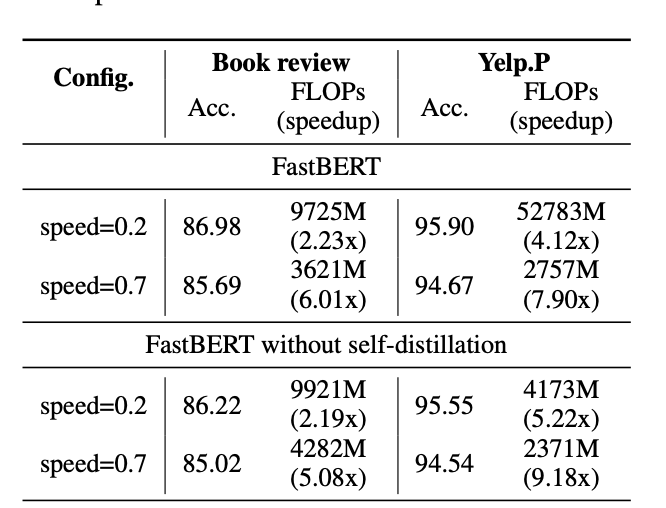
其实从这个图可以看到,如果没有自蒸馏,确实会有精度的下降。
论文中在自蒸馏的时候,使用的是无监督的数据。
我们一般可以会有大量的无监督数据,所以这个方法真的很适合少样本的情况的冷启动问题。
不过,如果有监督数据,使用 labeled data应该会取得更好的效果,也就是不用去学习soft,而是去学习Hard。
3. LUHA假设证明
这个论文其实我自己更感兴趣的是文中针对假设:“不确定性越低,分类的准确度越高”的证明。
作者分析了一个 FastBert 模型的三层:Student-Classifier0, StudentClassifier5, Teacher-Classifier 的分类结果,并在不同的不确定度区间评判分类准确度。
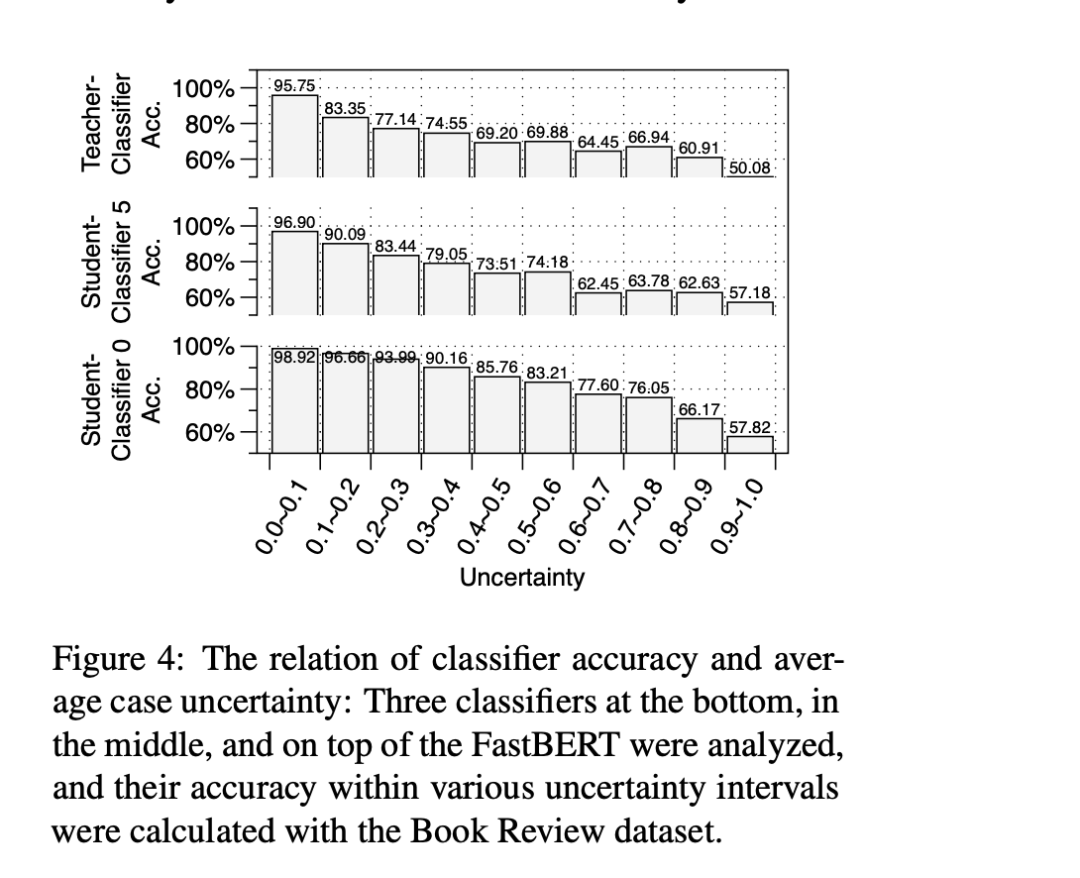
我自己的理解哈,在这里是没有进行speed的筛选的,而是计算所有的样本,不然对于第一层,大于speed的地方准确度应该是0(因为直接就往后走了,并没有使用它的分类结果),不应该出现在图中。
从这个图中,我们可以得到一个结论,就是不论是是针对分支网络的哪一层,还是针对主干网络,不确定性越高,分类的准确度越低。
换过来讲,不确定性越低(图中横坐标越靠左),分类的准确度越高。
当然作者是使用画图的方式来证明的,我自己当时理解的时候是这么想的:
作者对不确定性的定义就是熵(在类别维度上做了normalized)。
熵越低,说明分布的越集中,也就是说在做类别判定的时候,出现在某个类别的地方的概率越大,这样当然可以说明分类的准确度越高。
我这个思路可能并不严谨,不过我觉得还是挺好理解的。
4. 每层样本分布问题
从这个图,还有一个问题需要注意:
就是学生网络的分类层在每个不确定区间内的准确度都是高于主干网络分类层的(看最下面一个和最上面一个对比)。
这一点真是非常的奇怪,如果按照这个理解,那么完全可以使用第一层替代主干网络。
当然作者这里也给出了解释,就是每层的样本分布其实是不一样的,越靠近后面的层,样本的不确定度越低,越靠近左边,所以样本走完12层之后使用主干网络整体准确度肯定是比直接使用第一层的要好。
具体可以看下面这个图(a):
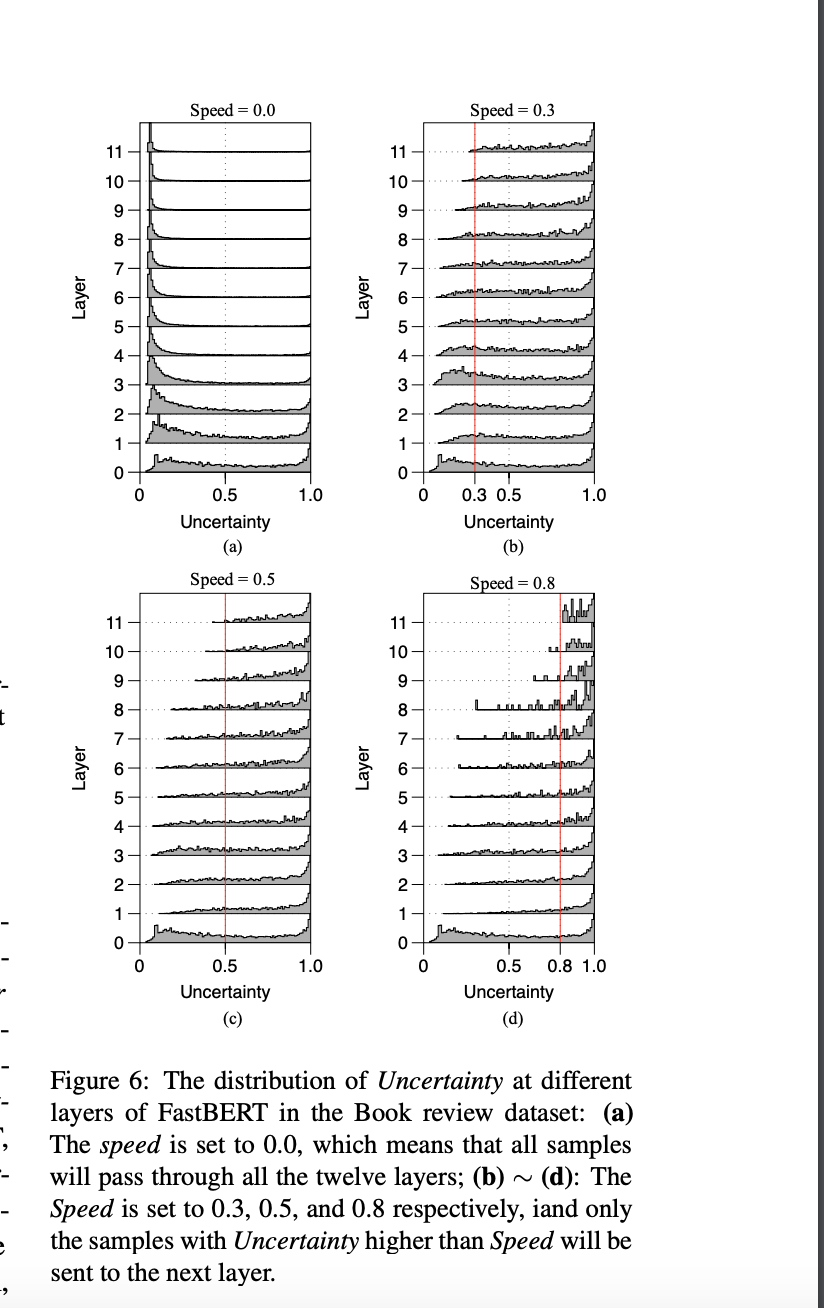
对于上面这个图,我们还可以仔细去看一看里面的内容。
需要明确一点,同一个样本,每经过一层计算一次它的不确定度(熵),都是在变化的,而且会逐渐靠近不确定度低的地方。
也就是这个样本被分出类别的可能性越来越大。
这一点其实很容易理解,就是Bert抽取能力随着层数越来越强,那么文本被正确分类的可能性当然越来越大,不确定度当然越来越大。
你的Speed越高,筛选出来的样本越多,留给后面的就越是不确定高的样本,那么分布越高近图中的右侧。
其他细节李如(她原来是个女生...)有个文章讲的挺好的,在这里:
FastBERT:又快又稳的推理提速方法 - 李rumor的文章 - 知乎 https://zhuanlan.zhihu.com/p/127869267
代码地址在这里:
https://github.com/autoliuweijie/FastBERT
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



