CVPR2019 | 旷视提出Meta-SR:单一模型实现超分辨率任意缩放因子
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
CVPR2019 accepted list ID已经公布,极市已将目前收集到的公开论文总结到github上(目前已收集292篇),后续会不断更新,欢迎关注,也欢迎大家提交自己的论文:
https://github.com/extreme-assistant/cvpr2019
今天为大家推荐一篇旷视的CVPR2019论文,论文提出一种全新方法,称之为 Meta-SR,首次通过单一模型解决了超分辨率的任意缩放因子问题(包括非整数因子)

论文名称:Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
论文链接:https://arxiv.org/abs/1903.00875
本文来源:旷视MEGVII
导语
简介
方法
Meta-Upscale
Location Projection
Weight Prediction
Feature Mapping
实验
单一模型任意缩放因子
推理时间
对比SOTA方法
可视化结果
结论
参考文献
往期解读
导语
随着深度卷积神经网络(DCNNs)技术的推进,超分辨率(super resolution/SR)的新近研究取得重大突破,但是关于任意缩放因子(arbitrary scalefactor)的研究一直未回到超分辨率社区的视野之中。
先前绝大多数 SOTA 方法把不同的超分辨率缩放因子看作独立的任务:即针对每个缩放因子分别训练一个模型(计算效率低),并且只考虑了若干个整数缩放因子。
在本文中,旷视研究院提出一种全新方法,称之为 Meta-SR,首次通过单一模型解决了超分辨率的任意缩放因子问题(包括非整数因子)。Meta-SR 包含一种新的模块——Meta-Upscale Module,以代替传统的放大模块(upscale module)。
针对任意缩放因子,这一新模块可通过输入缩放因子动态地预测放大滤波器的权重,进而使用这些权重生成任意大小的 HR 图像。对于一张低分辨率图像,只需一个模型,Meta-SR 就可对其进行任意倍数的放大。大量详实的实验数据证明了 Meta-Upscale 的优越性。
简介
单一图像超分辨率(single image super-resolution/SISR)旨在把一张较低分辨率(low-resolution/LR)的图像重建为一张自然而逼真的高分辨率(high-resolution/HR)图像,这项技术在城市管理、医疗影像、卫星及航空成像方面有着广泛应用。实际生活中,用户使用 SISR 技术把一张 LR 图像放大为自定义的大小也是一种刚需。正如借助于图像浏览器,用户拖动鼠标可任意缩放一张图像,以查看特定细节。
理论上讲,SR 的缩放因子可以是任意大小,而不应局限于特定的整数。因此,解决 SR 的任意缩放因子问题对于其进一步落地有着重大意义。但并不是针对每个因子训练一个模型,而是一个模型适用所有因子。
众所周知,大多数现有 SISR 方法只考虑一些特定的整数因子(X2, X3, X4),鲜有工作讨论任意缩放因子的问题。一些 SOTA 方法,比如 ESPCNN、EDSR、RDN、RCAN,是借助子像素卷积在网络的最后放大特征图;不幸的是,上述方法不得不针对每个因子设计专门的放大模块;另外,子像素卷积只适用于整数缩放因子。这些不足限制了 SISR 的实际落地。
尽管适当放大输入图像也可实现超分辨率的非整数缩放,但是重复的计算以及放大的输入使得这些方法很是耗时,难以投入实用。有鉴于此,一个解决任意缩放因子的单一模型是必需的,一组针对每一缩放因子的放大滤波器的权重也是必需的。
在元学习的启发下,旷视研究院提出一个动态预测每一缩放因子的滤波器权重的新网络,从而无需为每一缩放因子存储权重,取而代之,存储小的权重预测网络更为方便。旷视研究院将这种方法称之为 Meta-SR,它包含两个模块:特征学习模块和 Meta-Upscale 模块,后者的提出用于替代传统的放大模块。
对于待预测 SR 图像上的每个像素点(i, j),本文基于缩放因子 r 将其投射到 LR 图像上,Meta-Upscale 模块把与坐标和缩放因子相关的向量作为输入,并预测得到滤波器权重。对于待预测 SR 图像上的每个像素点(i, j), LR 图像上相应投影点上的特征和预测得到的权重卷积相乘就能预测出(i, j)的像素值。
Meta-Upscale 模块通过输入一系列与缩放因子及坐标相关的向量,可动态地预测不同数量的卷积滤波器权重。由此,只使用一个模型,Meta-Upscale 模块即可将特征图放大任意缩放因子。该模块可以替代传统放大模块(upscale module)而整合进绝大数现有方法之中。
方法
本节将介绍 Meta-SR 模型架构,如图 1 所示,在 Meta-SR 中,特征学习模块提取低分辨率图像的特征,Meta-Upscale 按照任意缩放因子放大特征图。本文首先介绍 Meta-Upscale,然后再描述 Meta-SR 的细节。
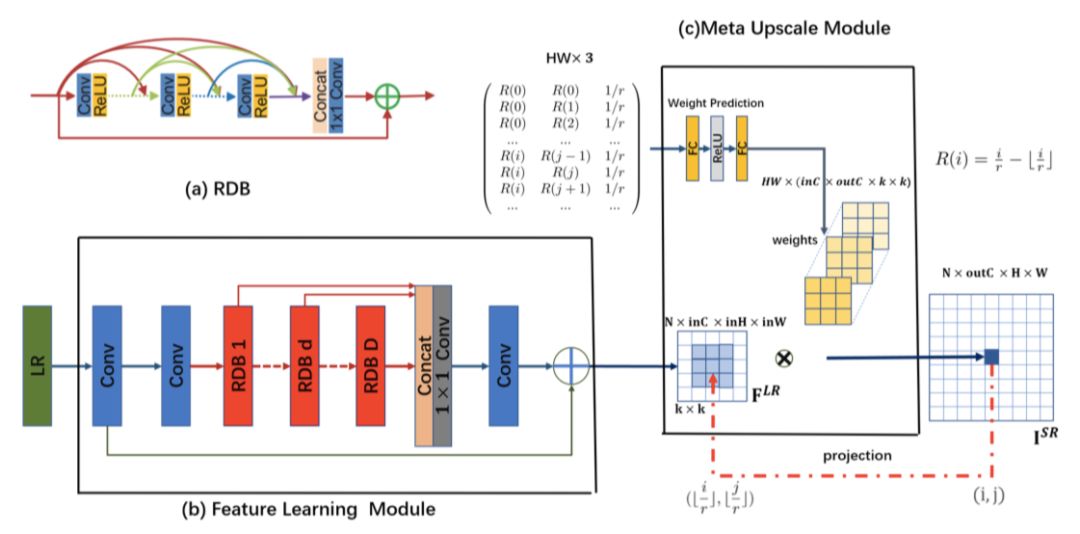
图 1:基于 RDN 的 Meta-SR 实例
Meta-Upscale
给定一张由高分辨(HR)图像I^HR缩小得到的低分辨(LR) 的图像I^LR,SISR 的任务即是生成一张 HR 图像 I^SR,其 groundtruth 是 I^HR。
本文选用 RDN 作为特征学习模块,如图 1(b)所示。这里,本文聚焦于 Meta-Upscale 的公式化建模。
令 F^LR 表示由特征学习模块提取的特征,并假定缩放因子是 r。对于 SR 图像上的每个像素(i,j),本文认为它由 LR 图像上像素(i′, j′)的特征与一组相应卷积滤波器的权重所共同决定。从这一角度看,放大模块可视为从 F^LR 到 I^SR 的映射函数。
首先,放大模块应该找到与像素(i, j)对应的像素(i′,j′)。接着,放大模块需要一组特定的滤波器来映射像素(i′,j′)的特征以生成这一像素(i, j)的值。以上可公式化表示为:
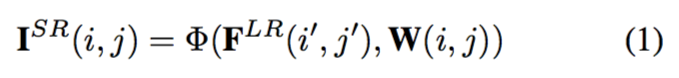
由于 SR 图像上的每一像素都对应一个滤波器,对于不同的缩放因子,其卷积滤波器的数量和权重也不同。为解决超分辨率任意缩放因子问题,本文基于坐标信息和缩放因子提出 Meta-Upscale 模块以动态地预测权重 W(i, j)。
本文提出的 Meta-Upscale 模块有三个重要的函数,即 Location Projection、Weight Prediction、Feature Mapping。如图 2 所示,Location Projection 把像素投射到 LR 图像上,即找到与像素(i, j)对应的像素(i′, j′),WeightPrediction 模块为 SR 图像上每个像素预测 对应滤波器的权重,最后,Feature Mapping 函数利用预测得到的权重将 LR 图像的特征映射回 SR 图像空间以计算其像素值。
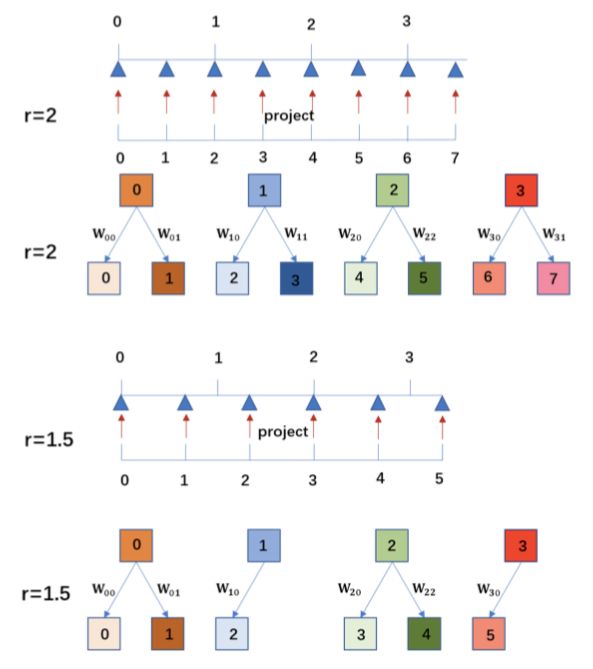
图 2:当非整数缩放因子 r=1.5 时,如何放大特征图的示意图
LocationProjection。对于 SR 图像上的每个像素(i,j),Location Projection 的作用是找到与像素(i, j)对应的 LR 图像上的像素(i′,j′)。本文认为,像素(i, j)的值是由像素(i′, j′)的特征所决定。下面的投影算子可映射这两个像素:
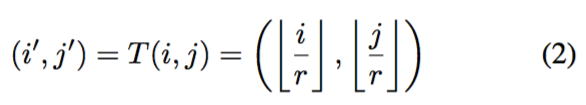
Location Projection 本质上是一种variable fractional stride 机制,这一机制使得基于卷积可以使用任意缩放因子(而不仅限于整数缩放因子)来放大特征图。
WeightPrediction。传统的放大模块会为每个缩放因子预定义相应数量的滤波器,并从训练集中学习 W。不同于传统放大模块,Meta-Upscale 借助单一网络为任意缩放因子预测相应数量滤波器的权重,这可表示为:
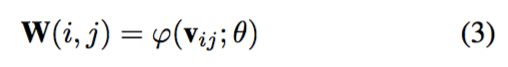
其中 v_ij 是与 i, j 相关联的向量,也是权重预测网络的输入,其可表示为:
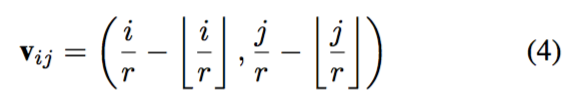
为了同时训练多个缩放因子,最好是将缩放因子添加进 v_ij 以区分不同缩放因子的权重。因此,v_ij 可更好地表示为:
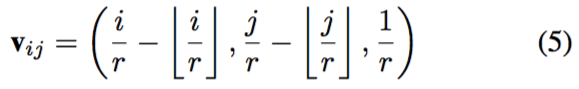
FeatureMapping。Location Projection 和 Weight Prediction 之后要做的就是把特征映射到 SR 图像上的像素值。本文选择矩阵乘积作为特征映射函数,表示如下:
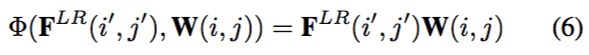
Meta-Upscale 模块的算法细节如下图所示:

实验
单一模型任意缩放因子
由于先前不存在类似于 Meta-SR 的方法,本文需要设计若干个 baselines(见图3),以作对比证明 Meta-SR 的优越性。
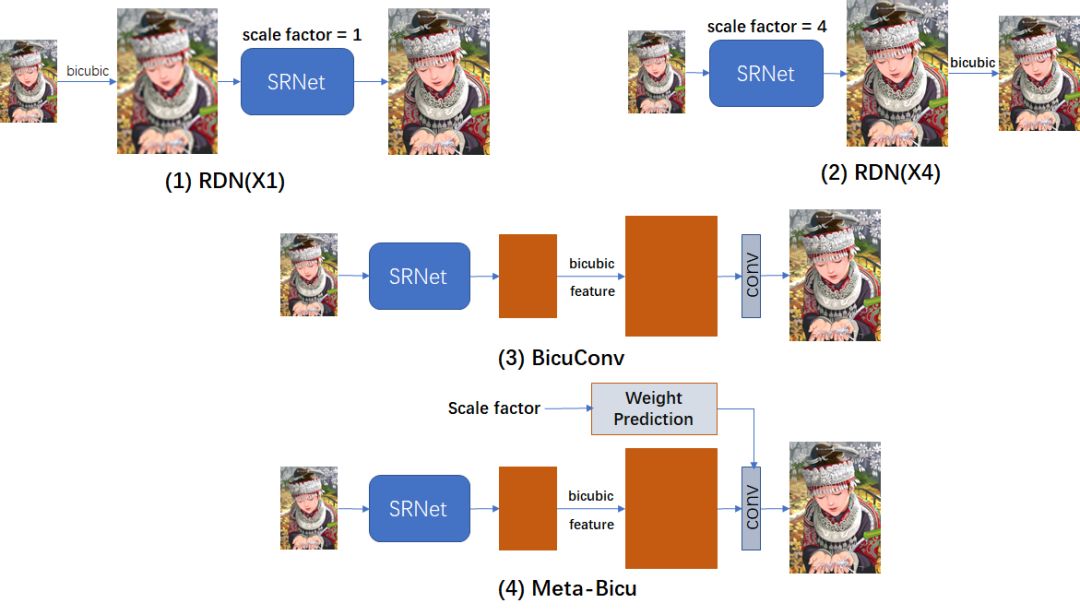
图 3 : 本文设计的 baselines
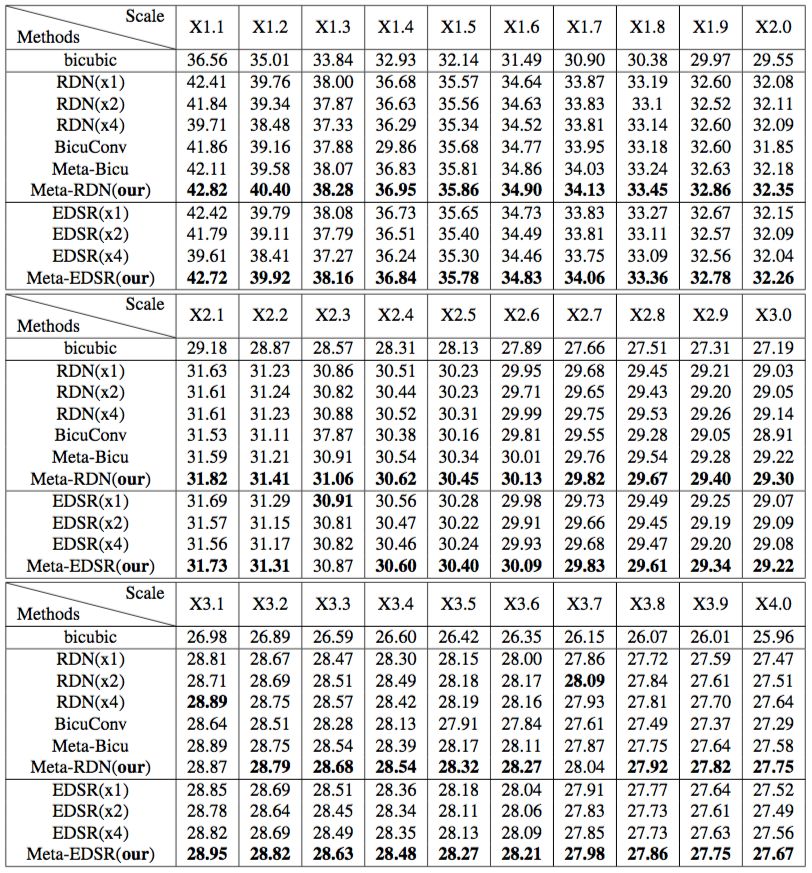
表 1:不同方法的任意放大模块的结果对比
实验结果如表 1 所示。对于双三次插值 baseline,简单地放大 LR 图像并不会给 HR 图像带来纹理或细节。对于 RDN(x1) 和 EDSR(x1),它们在较大的缩放因子上表现欠佳,而且需要提前放大输入,这使得该方法很费时。
对于 RDN(x4) 和 EDSR(x4),当缩放因子接近 1 时,Meta-RDN 与 RDN(x4) (或者Meta-EDSR 与 EDSR(x4)之间) 存在着巨大的性能差距。此外,当 r>k 时,EDSR(x4) 和 RDN(x4) 不得不在将其输入网络之前放大 LR 图像。
通过权重预测, Meta-Bicu 和Meta-SR 可为每个缩放因子学习到最佳滤波器权重,而 BicuConv 则是所有缩放因子共享同一的滤波器权重。实验结果表明 Meta-Bicu 显著优于 BicuConv,从而印证了权重预测模块的优越性。
同时,Meta-RDN 也由于Meta-Bicu, 这是因为对于在特征图插值,缩放因子越大,有效的 FOV 越小,性能下降越多。但是,在 Meta-SR 中,每个缩放因子具有相同的 FOV。受益于 Meta-Upscale,相较于其他 baselines,Meta-RDN 几乎在所有缩放因子上取得了更优性能。
推理时间
SISR 技术要实现落地,一个重要的因素是推理时间快。本文通过实验计算了 Meta-SR 的每一模块及 baselines 的运行时间,如表 2 所示。
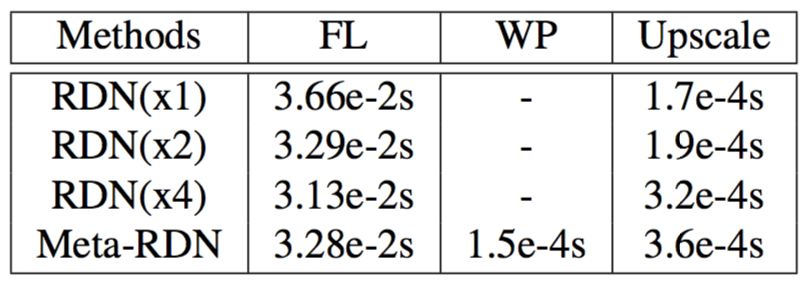
表 2:运行时间对比结果
在表 2 中,FL 表示 Feature Learning 模块,WP 表示 Meta-SR 的 Weight Prediction 模块,Upscale 是 Upscale 模块。测试是跑在 B100 上,测试的缩放因子是 2。
对比 SOTA 方法
本文把新提出的 Meta-Upscale 模块用于替代RDN 中的传统放大模块,获得 Meta-RDN,并将其与baseline RDN 进行对比。
值得注意的是,RDN 为每个缩放因子(X2, X3,X4)分别训练了一个特定的模型。本文按照 PSNR、SSIM 指标将 Meta-RDN 与 RDN 在 4 个数据库上作了对比,结果如表 3 所示:

表 3:当缩放因子为X2, X3, X4,Meta-RDN与 RDN 的对比结果
可视化结果
图 4 和图 5 分别给出了一些可视化结果。

图 4:Meta-RDN 方法按照不同缩放因子放大同一张图像的可视化对比结果

图 5:与 4 个 baselines 的可视化对比结果,Meta-RDN 表现最优
结论
旷视研究院提出一个全新的放大模块,称之为 Meta-Upscale,它可通过单一模型解决任意缩放因子的超分辨率问题。针对每个缩放因子,Meta-Upscale 模块可以动态地为放大模块生成一组相应权重。借助特征图与滤波器之间的卷积运算,研究员生成了任意大小的 HR 图像;加之权重预测,进而实现了单一模型解决任意缩放因子的超分辨率问题。值得一提的是,Meta-SR 还可以按照任意缩放因子快速地持续放大同一张图像。
参考文献
1. B. Lim, S. Son, H. Kim, S. Nah, and K. M.Lee. Enhanced deep residual networks for single image super-resolution. In TheIEEE conference on computer vision and pattern recog- nition (CVPR) workshops,2017. 1, 2, 5
2. W. Shi, J. Caballero, F. Husza ́r, J. Totz,A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang. Real-time single im- age andvideo super-resolution using an efficient sub-pixel convolutional neuralnetwork. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition, 2016. 1, 2, 5
3. K. Zhang, W. Zuo, and L. Zhang. Learning asingle convo- lutional super-resolution network for multiple degradations. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June2018. 1, 5
4. Y.Zhang,K.Li,K.Li,L.Wang,B.Zhong,andY.Fu.Imagesuper-resolution using very deep residual channel attention networks. arXivpreprint arXiv:1807.02758, 2018. 2, 5
5. Y. Zhang, Y. Tian, Y. Kong, B. Zhong, andY. Fu. Resid- ual dense network for image super-resolution. In The IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2018. 1, 2, 3, 5,7
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

\]HYU觉得有用麻烦给个好看啦~



