DeepMind最新力作:分布式强化学习框架Acme,智能体并行性加强
深度强化学习实验室报道
来源:机器之心
近日,DeepMind 发布了一种新型分布式强化学习框架「Acme」,通过促使 AI 驱动的智能体在不同规模的环境中运行,该框架可以简化强化学习算法开发进程。此外,与先前方法相比,研究人员可以使用该框架创建并行性更强的智能体。

近年来,在深度学习技术和算力提升的双重加持下,强化学习已经在众多复杂的 AI 挑战中取得了辉煌战绩。无论是象棋、围棋、麻将,还是王者荣耀以及各类雅达利经典游戏,强化学习的表现都足以令人叹服。
但深度强化学习在带来开创性进展的同时,也带来了一些「挑战」:这些进步常常以底层强化学习算法的规模及复杂性为代价,复杂性的增加反过来又使得已公开的强化学习算法或者 idea 变得难以复现。
为了解决强化学习算法由单进程原型到分布式系统扩展过程中智能体的重新部署问题,DeepMind 推出了一种新的分布式强化学习框架「Acme」。
目前,由研究者和工程人员共同完成的论文也已正式公布。

项目地址:https://github.com/deepmind/acme
论文地址:https://arxiv.org/abs/2006.00979
Acme 是一款用于构建可读、高效、研究型强化学习算法的框架,核心理念在于实现对强化学习智能体的简单描述,使得智能体在各种规模下运行,包括分布式智能体。研究者在设计 Acme 的过程中也充分考虑到了不同规模智能体之间的差异,并弥合了大中小型实验之间的差别。
DeepMind 研究者表示:「我们的目标是使得学界和工业界开发的各种强化学习算法更轻松地复制和推广到整个机器学习社区。」
Acme 框架具体是怎样的
从最高层次来说的话,我们可以将 Acme 视为一个经典的强化学习接口(在任何入门级的强化学习文本中都可以找到),它的作用是将 actor(比如一个动作选择智能体)连接到环境。
actor 是一个具有动作选择能力、观察能力和自我更新能力的简单接口。在内部,学习智能体可以拆分为「执行」和「从数据中学习」两部分。从表面上看,这使得在很多不同智能体之间重复使用 acting portion。
但更重要的是,这提供了一个让学习过程可划分和并行化的关键边界:使用者甚至可以在此处按比例缩小规模,并无缝地攻击不存在环境且只有固定数据集的批强化学习设置(batch RL setting)。
下图展示了不同级别复杂度的情况:
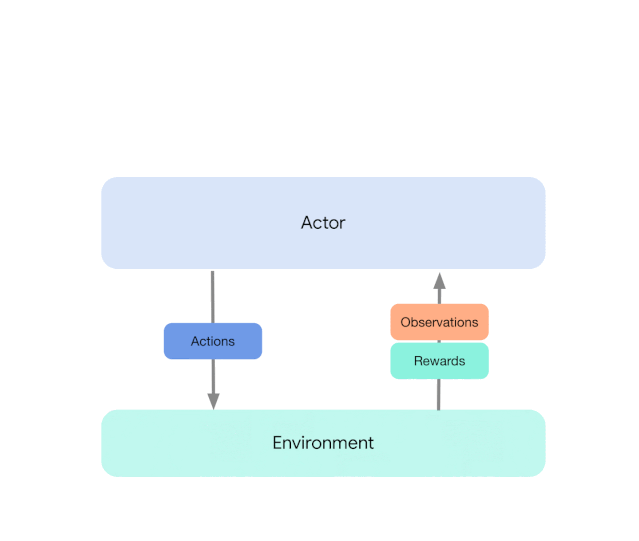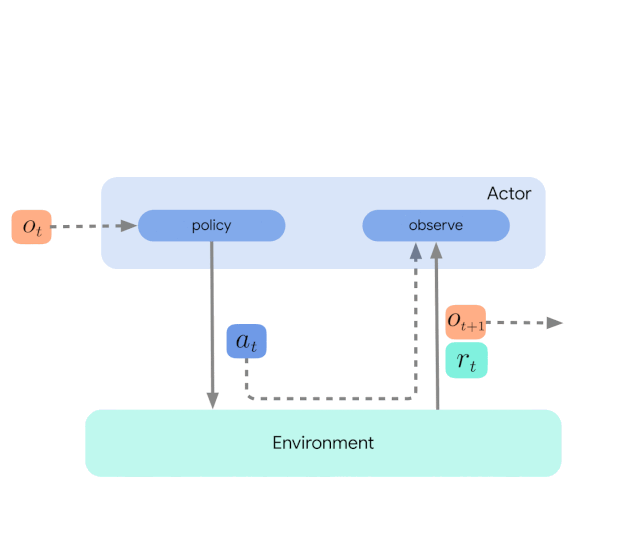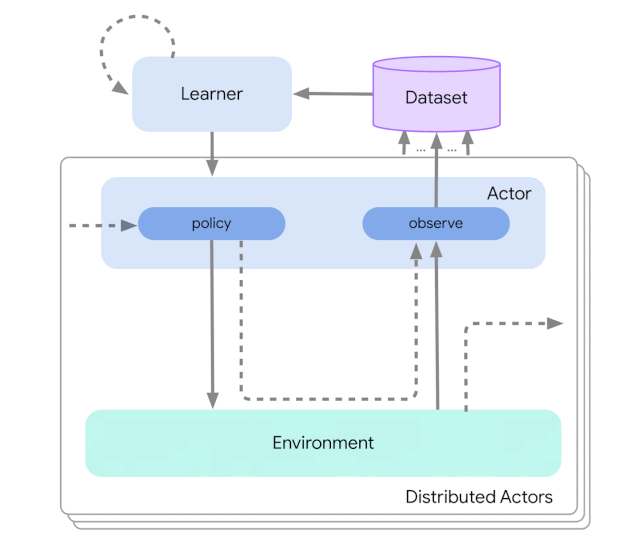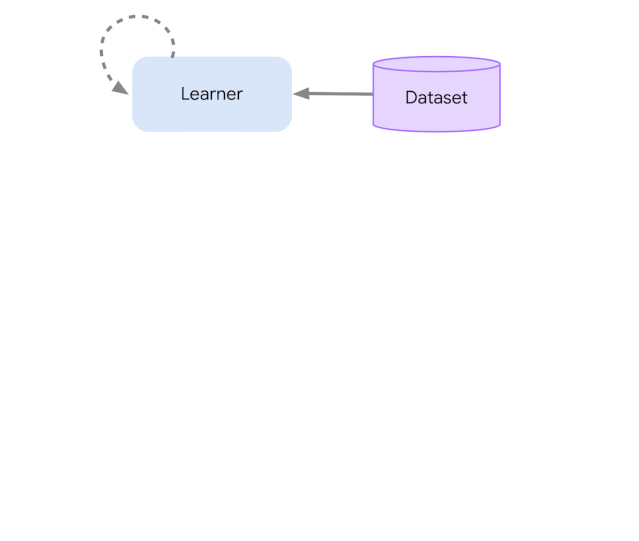
这种设计使得研究者在扩展之前可以轻松地在小规模场景中创建、测试和调试新型智能体,并且所有这些都使用相同的动作和学习代码。从检查点技术到快照技术,Acme 框架还为低水平计算机辅助提供大量有用的实用工具。这些工具常常在强化学习算法中发挥不可或缺的重要作用,在 Acme 框架,DeepMind 力图使它们更简单且更易理解。
为了实现这种设计,Acme 框架还使用了「Reverb」,一种针对机器学习(包括强化学习)数据创建的新型高效数据存储系统。Reverb 在分布式强化学习算法中主要用作经验回放(experience replay)系统,但也支持 FIFO 和优先级队列等其他数据结构表示,这样可以无缝地用于在线和离线策略算法(on-and off-policy algorithm)。
Acme 框架下智能体的性能变化
除了基础架构之外,DeepMind 还发布了使用 Acme 框架所创建的大量智能体的单进程实例化,它们可以运行连续控制(如 D4PG 和 MPO)、离散 Q 学习(DQN 和 R2D2)以及更多其他强化学习算法。此外,通过跨动作 / 学习边界分割这样的小改变,我们即可以分布式地运行这些智能体。Acme 框架首个版本主要针对学生和研究人员使用最多的单进程智能体。
研究者在 control suite、Atari 和 bsuite 等环境中对这些智能体进行了基准测试,下面动图 Demo 为利用 Acme 框架的智能体训练示例:

如下图所示,DeepMind 展示了单个智能体(D4PG)的性能比较,其中所采用的度量指标是连续控制任务的 actor step 和时钟时间。可以看到,当对智能体收到的奖励与其环境交互次数进行比较时,性能大致相同。但是,随着智能体进一步并行化,智能体的学习速度加快。在相对较小的域内,观察结果被限制在小的特征空间中,这时即使并行化程度适度增加,则智能体学习最优策略的时间会降至不到一半。
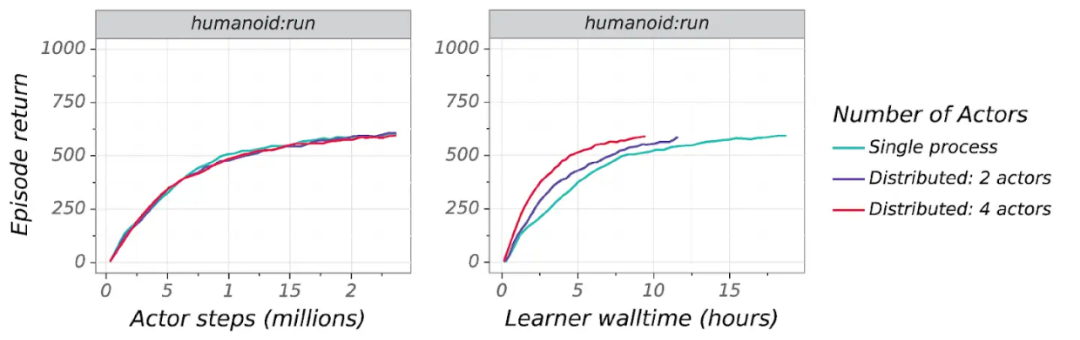
但对于更复杂的域,图像生成成本相对较高,我们可以看到更广泛的增益:
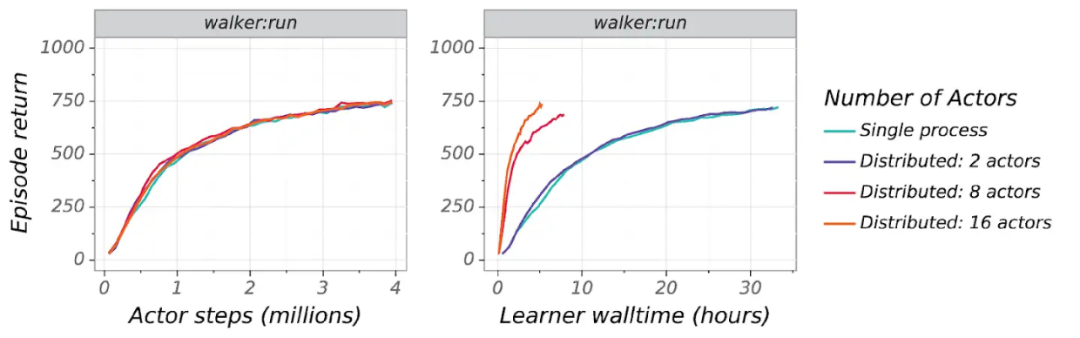
对于雅达利游戏等数据收集成本更高且学习过程通常更长的域说,增益会更大。但需要注意的是,这些结果在分布式和非分布式设置下共享相同的动作和学习代码,因此对这些智能体和结果进行小规模实验完全可行。
原文链接:https://deepmind.com/research/publications/Acme

总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)


