效果惊艳!北大团队提出Attentive GAN去除图像中雨滴


新智元报道
来源:arxiv
编译:肖琴
【新智元导读】北京大学和新加坡国立大学的研究人员提出一种新方法去除图像中的雨滴,通过在生成对抗网络中插入注意力图,去除雨滴的效果相比以往方法大幅提升。这项工作有很大的实际意义,比如用在自动驾驶中。
论文:
https://arxiv.org/pdf/1711.10098.pdf

附着在玻璃窗户、挡风玻璃或镜头上的雨滴会阻碍背景场景的能见度,并降低图像的质量。图像质量降低的主要原因是有雨滴的区域与没有雨滴的区域相比,包含不同的映象。与没有雨滴的区域不同,雨滴区域是由来自更广泛环境的反射光形成的,这是由于雨滴的形状类似于鱼眼镜头。此外,在大多数情况下,相机的焦点都在背景场景上,使得雨滴的外观变得模糊。
在这篇论文中,北京大学计算机科学技术研究所和新加坡国立大学的研究人员解决了这种图像能见度降低(visibility degradation)的问题。由于雨滴降低了图像质量,我们的目标是去除雨滴并产生清晰的背景,如图1所示。

图1:雨滴去除方法的演示。左图:输入的有雨滴的图像。右图:我们的结果,大多数雨滴被去除了,结构细节也被恢复。放大图片可以更好地观察修复质量。
我们的方法是全自动的。该方法将有利于图像处理和计算机视觉应用,特别是哪些需要处理雨滴、灰尘或类似东西的应用。
有几种方法可以解决雨滴的检测和去除问题。但是,一些方法专用于检测雨滴而不能将其去除,一些方法不适用于普通相机拍摄的单个输入图像,或者只能处理小的雨滴,并且产生的输出很模糊。
我们的工作打算处理大量的雨滴,如图1所示。一般来说,去除雨滴的问题是难以解决的。因为首先,被雨滴遮挡的区域不是固定的。其次,被遮挡区域的背景场景的信息大部分是完全丢失的。当雨滴较大,而且密集地分布在输入图像时,问题会变得更糟。
为了解决这个问题,我们使用生成对抗网络(GAN)。在这个网络中,产生的输出将由判别网络(discriminative network)进行评估,以确保输出看起来像真实的图像。为了解决问题的复杂性,生成网络( generative network)首先尝试生成一个注意力图(attention map)。注意力图是这个网络中最重要的部分,因为它将引导生成网络关注雨滴区域。 注意力图由一个循环网络生成,该循环网络由深层残差网络(ResNets)和一个卷积LSTM和几个标准的卷积层组成。我们称之为attentive-recurrent network。
生成网络的第二部分是一个自动编码器(autoencoder),它以输入图像和注意力图作为输入。为了获得更广泛的上下文信息,在自动编码器的解码器侧,我们应用了多尺度损失(multi-scale losses)。每个损失都比较了卷积层的输出和相应的ground truth之间的差异。卷积层的输入是解码器层的特征。除了这些损失之外,对于自动编码器的最终输出,我们应用一个感知损失来获得与ground truth更全面的相似性。最后的输出也是生成网络的输出。
在获得生成图像输出后,判别网络将检查它是否真实。但是,在我们的问题中,尤其是在测试阶段,目标雨滴区域并没有给出。因此,在局部区域上没有判别网络可以关注的信息。为了解决这一问题,我们利用注意力图来引导判别网络指向局部目标区域。
总的来说,除了引入一种新的雨滴去除方法外,我们的另一个主要贡献是将注意力图引入到生成网络和判别网络中,这是一种全新的方法,可以有效地去除雨滴。我们将发布代码和数据集。
我们将有雨滴的图像建模为背景图像与雨滴效果的结合:
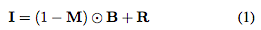
其中I是彩色的输入图像,M是二进制掩码。在掩模中,M(x) = 1表示像素x是雨滴区域的一部分,否则表示它是背景区域的一部分。B表示背景图像,R表示雨滴带来的效果。运算符⊙表示element-wise乘法。
雨滴实际上是透明的。然而,由于雨滴区域的形状和折射率,雨滴区域的像素不仅受到现实世界中一个点的影响,还受到整个环境的影响,使得大部分雨滴似乎都有不同于背景场景的意象。此外,由于我们的相机被假定聚焦在背景场景上,雨滴区域内的图像大多是模糊的。雨滴的某些部分,尤其是外围和透明区域,传达了一些有关背景的信息。我们注意到这些信息可以被我们的网络利用。
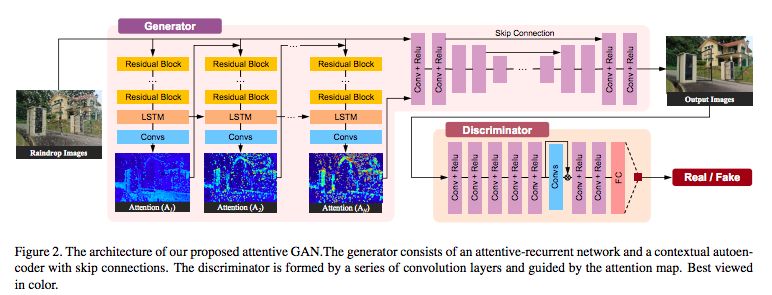
图2:Attentive GAN的架构。生成器由一个 attentive-recurrent网络和autoencoder组成。判别器由一系列的卷积层组成,并由attention map引导。
图2显示了我们提出的网络的总体架构。根据生成对抗网络的思想,Attentive GAN有两个主要部分:生成网络和判别网络。给定一个有雨滴的输入图像,我们的生成网络试图生成一个尽可能真实并且没有雨滴的图像。判别网络将验证生成网络生成的图像是否看起来真实。
Attentive GAN的loss可以表示为:
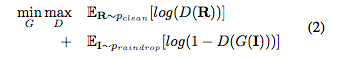
生成网络(Generative Network)
如图2所示,生成网络由两个子网络组成:一个attentive-recurrent network和一个contextual autoencoder。
Attentive-Recurrent Network:视觉注意力模型被应用于定位目标区域的图像,以捕获区域的特征。

图3:attention map学习过程的可视化
Contextual Autoencoder:背景自动编码器的目的是产生一个没有雨滴的图像。自动编码器的输入是输入图像和Attentive-Recurrent网络的最终注意力图的连接。我们的deep autoencoder有16个conv-relu块,并且跳过连接以防止模糊输出。
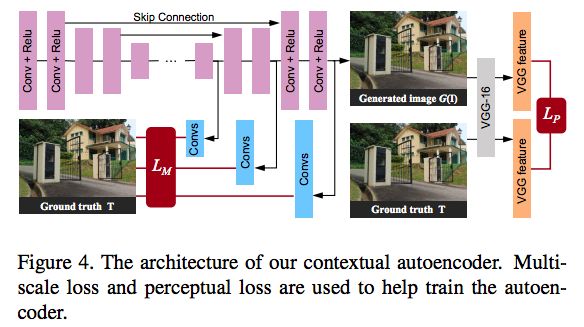
图4:Contextual Autoencoder的结构
判别网络(Discriminative Network)
我们的判别网络包含7个卷积层,核为(3,3),全链接层为1024,以及一个具有sigmoid激活函数的单个神经元。我们从倒数第三个卷积层提取特征,然后进行乘法运算。

图5:数据集的样本。上:有雨滴的图像。下:相应的ground-truth图像。
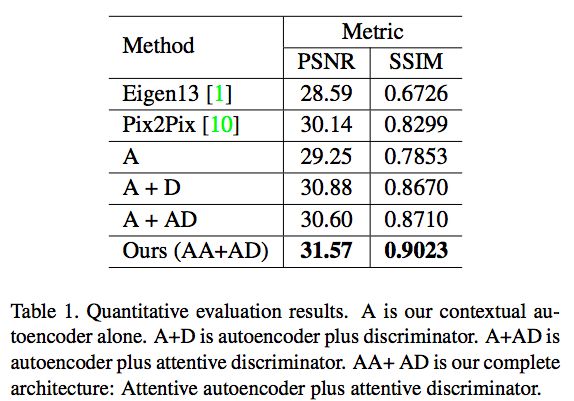
表1:定量评估的结果

图6:比较几种不同方法的结果

图7:比较我们网络架构的一些部分

图8:attentive-recurrent 网络生成的注意力图的可视化

图9:我们的输出和Pix2Pix输出之间的比较。我们的输出具有更少的伪影和更好的复原结构
为了进一步证明我们的可见性增强方法对于计算机视觉应用是有用的,我们使用了谷歌视觉API (https://cloud.google.com/vision/)来测试使用我们的输出是否可以提高识别性能。结果如图10所示。

图10:一个改进谷歌视觉API结果的示例。我们的方法增加了主要对象检测的分数以及识别到的对象数量。
可以看出,使用我们的输出,一般的识别比没有我们的可见性增强过程要好。此外,我们对测试数据集进行评估,如图11的统计数据显示,使用我们的可见性增强输出在识别输入图像中的主要对象的平均得分和识别出的对象标签数方面,显著优于没有可见性 增强的输出。
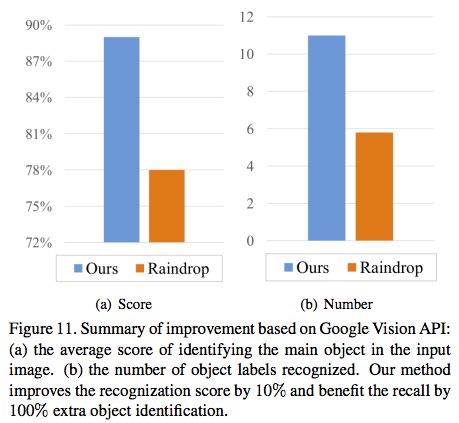
图11:基于Google Vision API的改进
我们提出了一种基于单幅图像的雨滴去除方法。该方法利用生成对抗网络,其中生成网络通过attentive-recurrent网络产生注意力图(attention map),并将该图与输入图像一起通过contextual autoencoder生成无雨滴图像。然后,判别网络评估生成的输出的全局和局部有效性。为了能够局部验证,我们将注意力图注入网络。该方法的创新之处在于在生成网络和判别网络中使用注意力图。我们还认为,我们的方法是第一种可以处理相对严重的雨滴图像的方法,而目前最先进的雨滴去除方法尚没有解决这个问题。
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




