知识库问答的复杂问题研究回顾

©PaperWeekly 原创 · 作者|舒意恒
学校|南京大学硕士生
研究方向|知识图谱
本文尝试回顾近年来知识库问答(Question Answering over Knowledge Bases, KBQA)领域中对于一种特殊的问题类型,即复杂问题(complex questions)的相关研究。复杂问题相比简单问题而言,一般涉及多个知识库事实,并可能包含多个各类约束。相关论文常使用 WebQuestionsSP、ComplexWebQuestions 等数据集进行实验。
本文将从以下方面介绍关于复杂问题的一些研究:
-
问题分解方法 -
基于依赖的方法 -
查询图编码与相似度计算 -
查询图生成与排序

问题分解方法

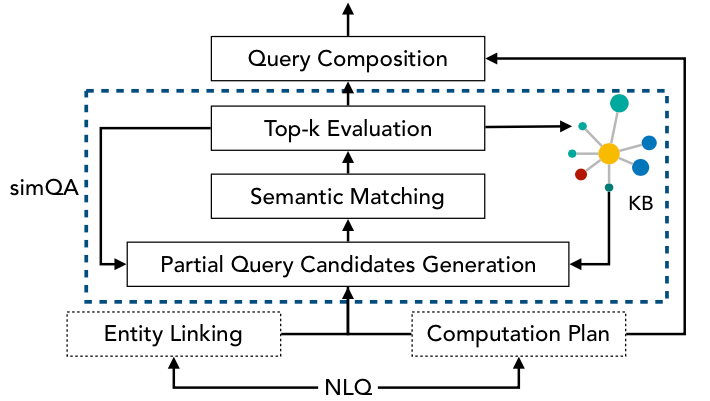
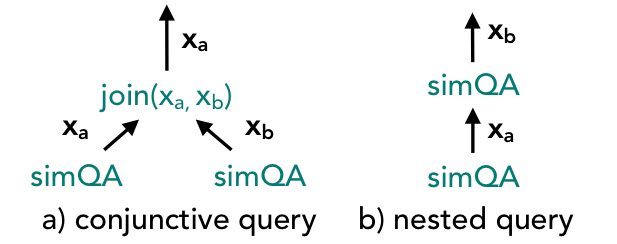
该系统需要一个用于计算部分查询候选项的语义相似性的模型。可以使用一组问题-答案对来离线学习模型。学习从一组候选查询中猜测一个较好的候选查询需要一组(问题 - 部分查询)对的正例和负例。

论文标题:Complex Question Decomposition for Semantic Parsing
论文来源:ACL 2019
论文链接:https://www.aclweb.org/anthology/P19-1440.pdf
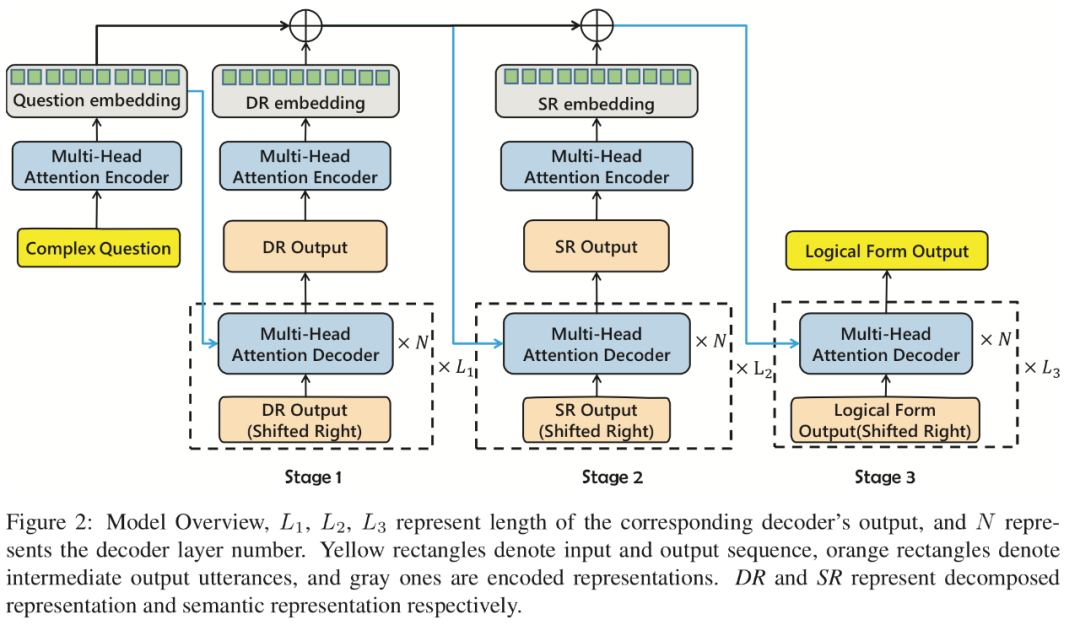
在该工作中,作者提出一种新颖的分层语义解析(Hierarchical Semantic Parsing, HSP)方法,该方法利用复杂问题的可分解性进行语义解析。该模型是基于分解-集成的思想,以三阶段的解析架构设计。
在第一阶段,作者提出了一个问题分解器,可以将一个复杂的问题分解为一系列子问题。在第二阶段,作者设计了一个信息提取器来导出这些问题的类型和谓词信息。在第三阶段,作者将先前阶段生成的信息进行整合,并为复杂问题生成逻辑形式。
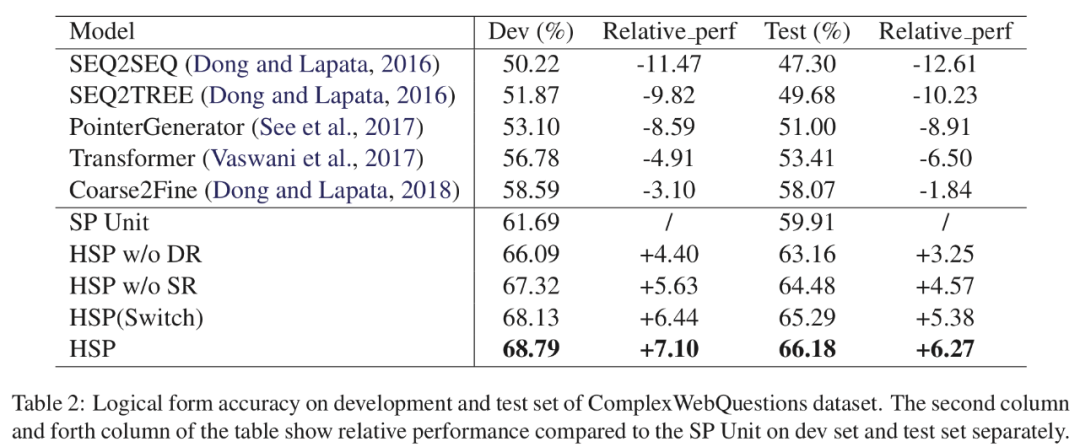
为了更好地建模和泛化逻辑形式,该模型使用两种类型的中间表示:分解表示(decomposed representation, DR)和语义表示(semantic representation, SP)。
DR 包含分解后的简单问题
SR 包含原始复杂问题的关键信息,包括问题类型和问题中的谓词
两种表示的示例如下表,其中子问题中的 #entity 表示占位符,真实的单词是通过另一个子问题的答案填充的。

分层语义解析


论文标题:Automated Template Generation for Question Answering over Knowledge Graphs
论文来源:WWW 2017
论文链接:https://dl.acm.org/doi/10.1145/3038912.3052583
词汇
模板
下图展示了学习和后续使用模板并利用知识库回答自然语言问题的过程。模板是在训练时生成的(下图左侧),在测试时被使用(下图右侧)。训练阶段的输入是问答对,即问答对是用于学习构建模板的。
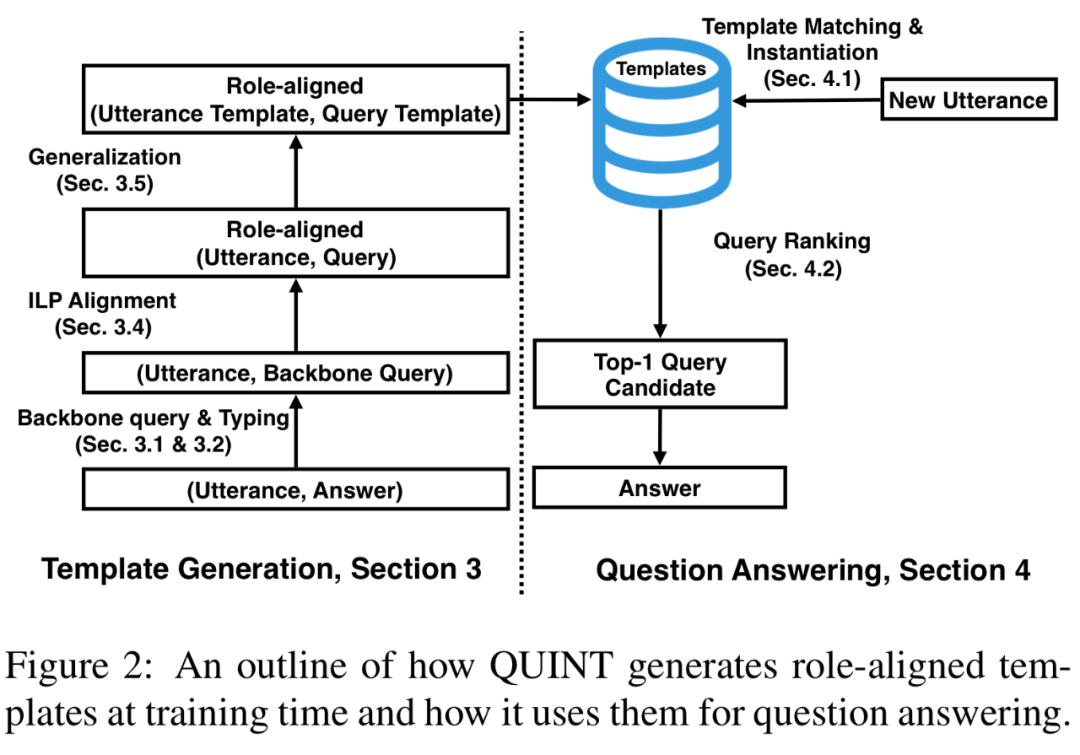
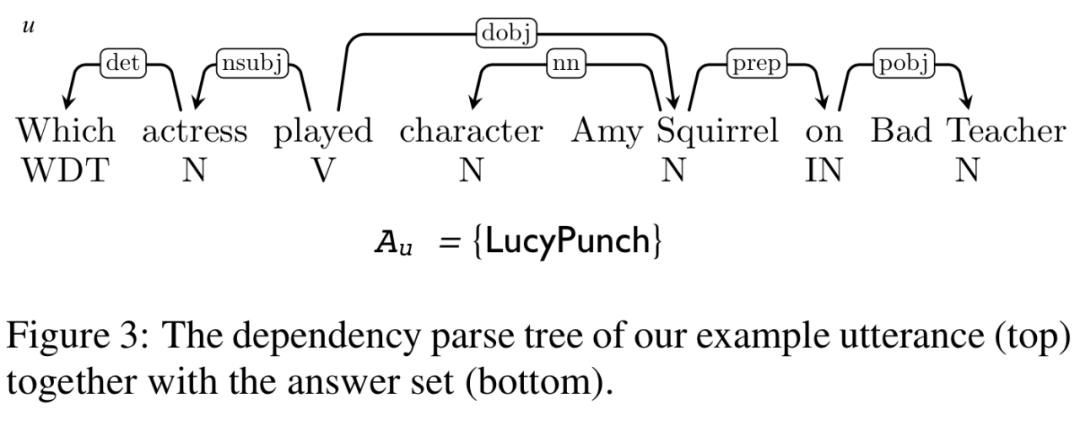
具体而言,模板是如何构建的?简言之,QUINT 首先用 NER 方法识别和消岐语句中的实体,QUINT 从在 KG 中找到的包含答案和所识别实体的最小子图生成查询,保留 F1 最高的查询。
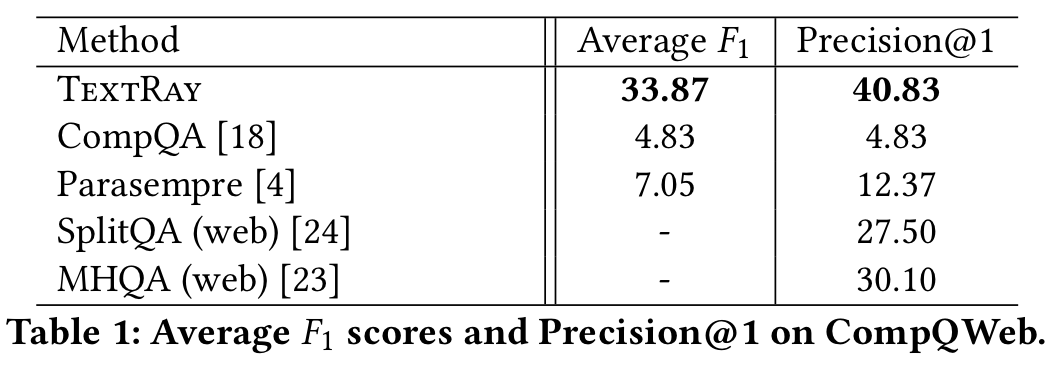
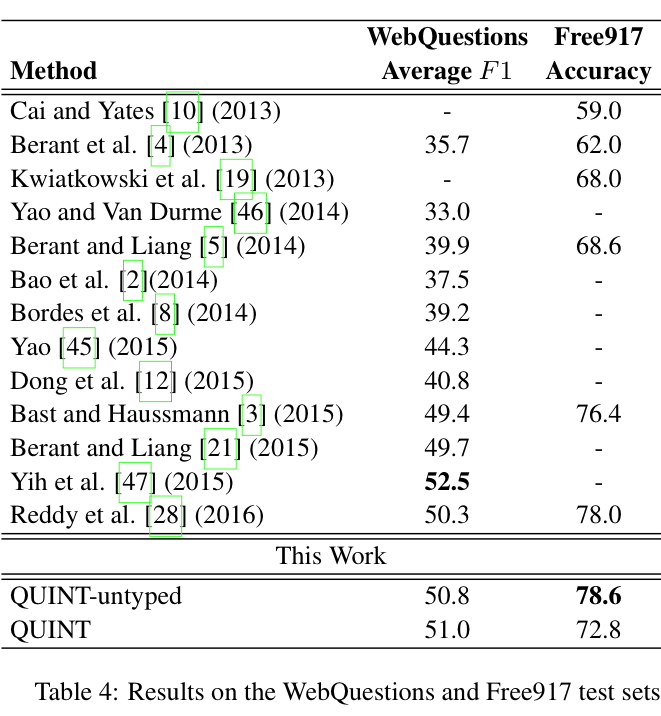
作者在 WebQuestions、Free917、ComplexQuestions 三个数据集上进行实验。在 WebQuesitions 上直接使用 F1 作为评价指标,没有达到 SOTA 效果。Free917 上的评价指标是正确回答的准确率,进行标准答案集进行评价。


论文标题:SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases
论文来源:AAAI 2020
论文链接:https://arxiv.org/abs/2003.13956
代码链接:https://github.com/nju-websoft/SPARQA
作者认为,许多现有方法都利用类似于依赖的语法解析。但是,产生这样的形式化表达的准确性不能满足足够长的复杂问题。在本文中,作者提出了一种新颖的骨架语法来表示一个复杂问题的高级结构。
这种专用的基于 BERT 的解析算法的粗粒度形式化表达有助于提高下游细粒度语义解析的准确性。此外,为了使问题的结构与知识库的结构保持一致,文中提出一种多策略方法结合句子级和单词级语义。
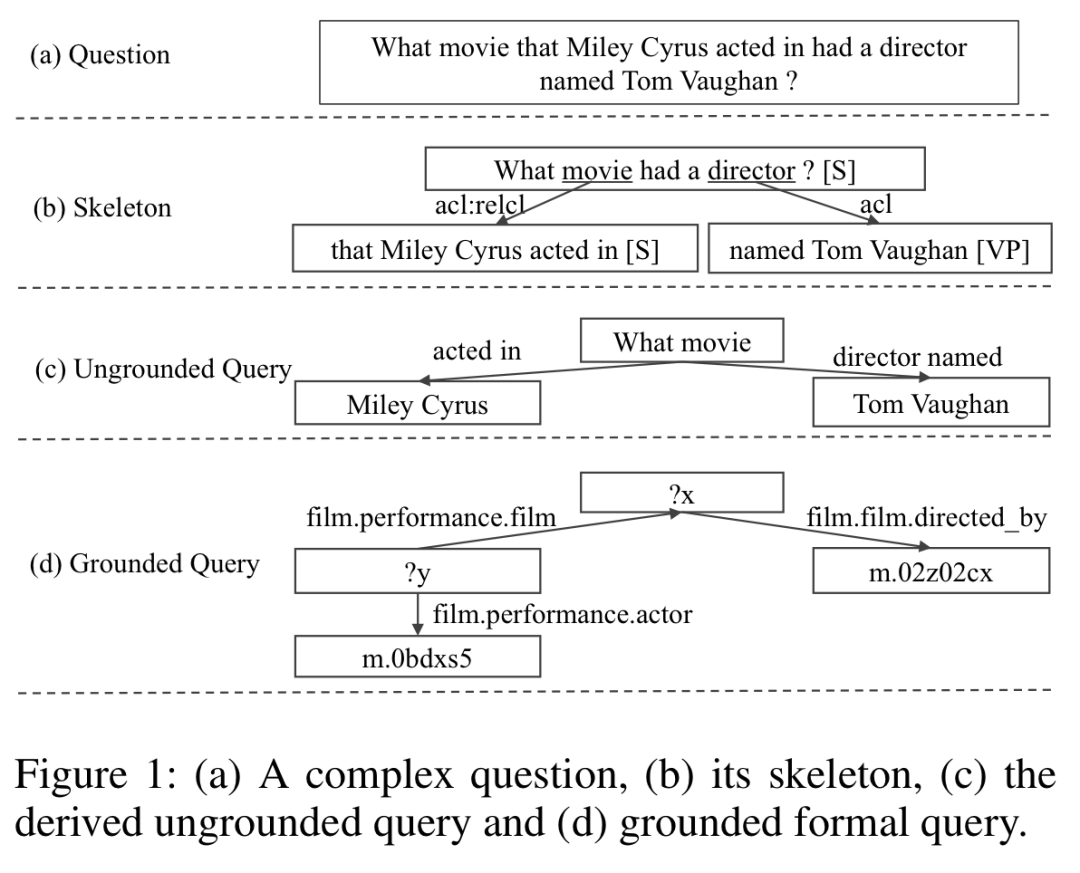
骨架语法本质上是依赖语法的一个选定子集,用于专门表示复杂问题的高级结构。这种专用的粗粒度表示形式由于其简单性而可能具有准确的解析算法,有助于提高下游细粒度语义解析的准确性。
一个问题句子的骨架是一个有向树,其中的结点是句子中的文本片段,边表示文本之间的关系。具体来说,文本片段是从另一个判断中的关键字(headword)附加的。
文本片段表示短语级别的语义单元。作者在短语结构语法中考虑四种类型的文本片段:从句,名词短语,动词短语和介词短语。但这种类型划分只是为了读者理解,框架解析器并不需要标记文本片段的类型。
附属关系表示文本片段之间的依赖。作者考虑了标准依赖语法中的七种常见关系:形容词从句,其子类型相对从句修饰符,名词修饰符,其子类型所有格替代,连词,开放式补语,以及状语从句修饰符。
骨架具有树结构。当确定骨架语法的粒度并定义文本片段和附属关系的类型时,我们要提供的这种树结构的关键特征是:通过迭代地删除其叶节点,每次迭代中剩余的文本片段始终包含一个格式最完善的句子,直到达到一个简单句子为止,这样就不可能进一步拆分。这种高级结构有助于将复杂问题的主干与其他部分区别开来。
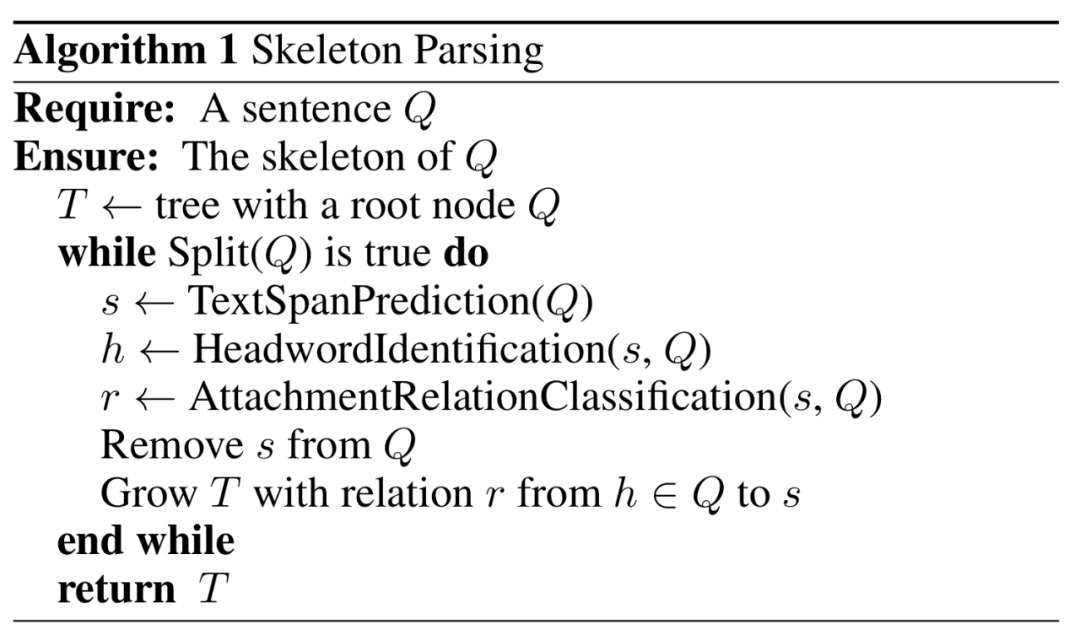
其中包含四个过程可简述如下。
-
Split:决定一个自然语言问题 是否需要进一步拆分。 -
TextSpanPrediction:预测下一个从 中拆分出来的文本片段,输出的文本片段称为 。 -
HeadwordIdentification:从 附属的剩余的 中识别关键词(headword),这一步从剩余的 中得到文本片段 。 -
AttachmentRelationClassification:该过程确定从剩余 中的 到 的附属关系 。作者将 和剩余的 视为馈入模型的两个句子,该模型将七个预定义的附属关系之一输出为 。
句子级评分器通过挖掘和匹配句子/查询模式来利用从问题到形式化查询的已知映射。通过将实体提及替换为虚拟 token 来获得问题的模式。
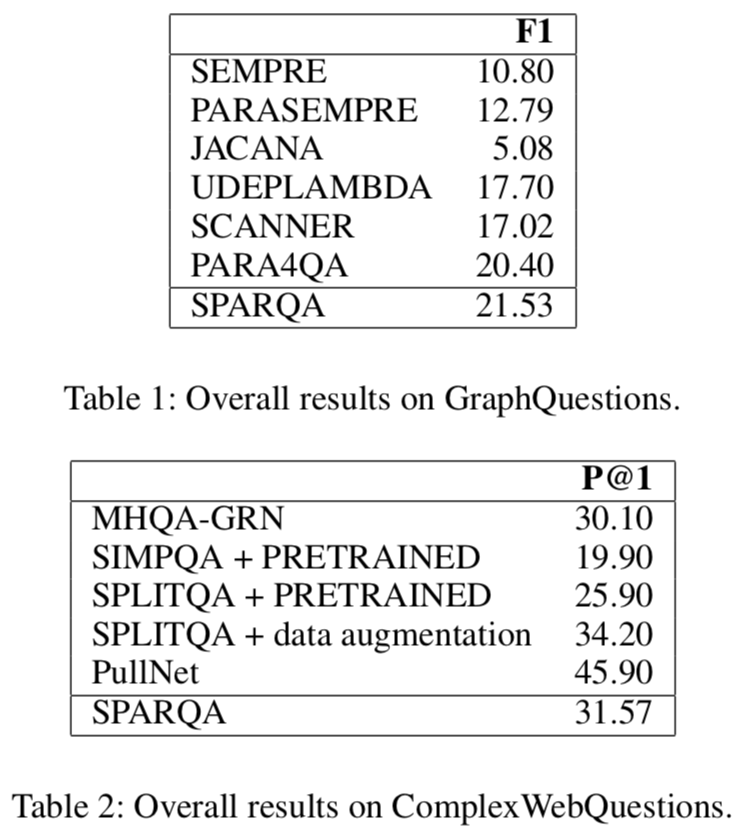
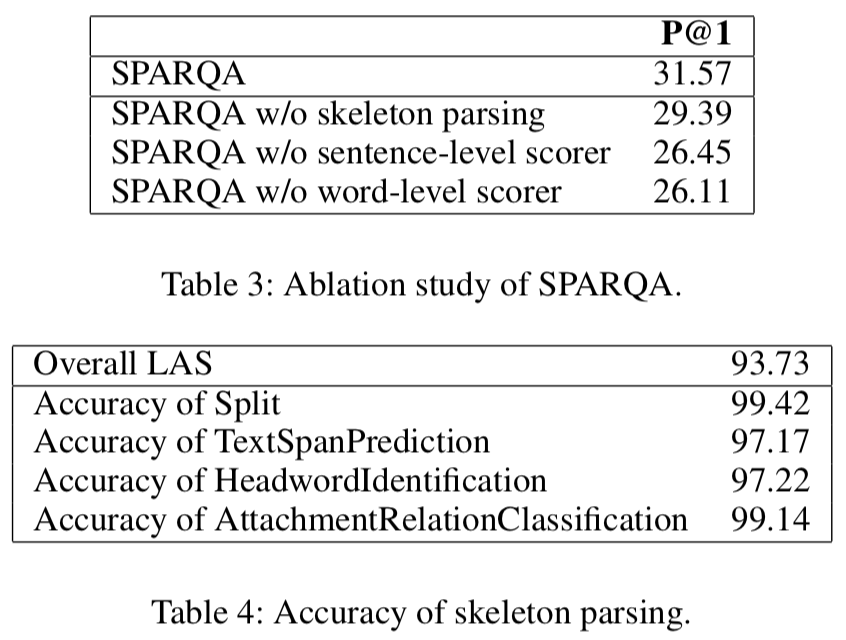
作者在 GraphQuestions 和 ComplexWebQuestions 两个数据集上进行实验。

查询图编码的相关工作,并不关注于查询图的生成过程。其基本思路是对问题和查询图进行编码,以向量表示二者,并设计语义相似度模型以向量表示计算问题和查询图的相似度。

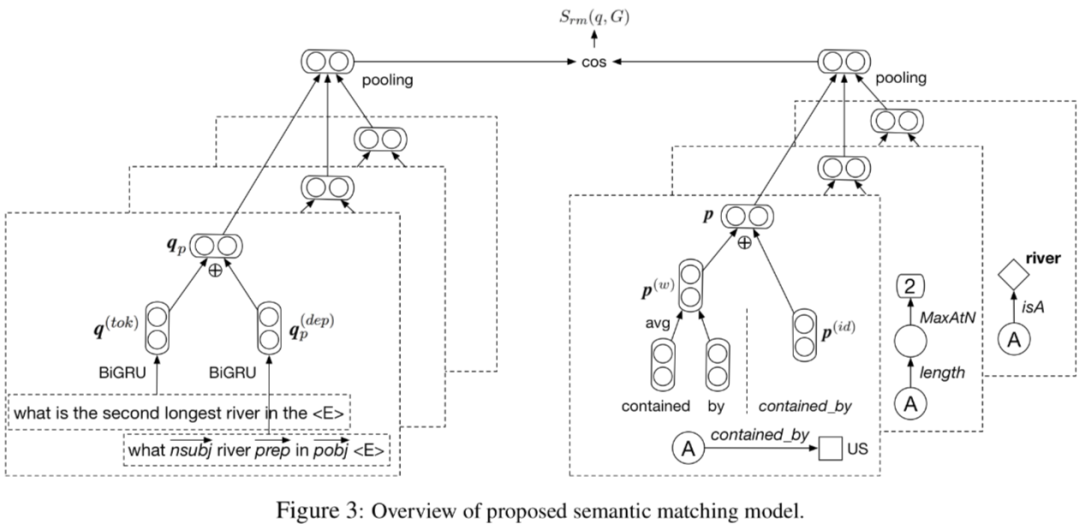
为了对语义成分进行编码,我们要考虑谓词 id 和谓词名称的顺序。如上图所示,第一个语义成分的 id 序列是 {contained_by},谓词名称序列是每个谓词的规范名称的串联,即 {“ contained”,“ by”}.
给定一个单词序列,首先使用词嵌入矩阵将原始序列转换为词嵌入。然后通过单词表示的平均,得到单词序列的表示。
给定一个 id 序列,作者直接将它作为一个整体单元,并使用嵌入矩阵在路径层面直接将它翻译为一个向量表示。使用路径层面嵌入的原因是:1)id 序列的长度不超过 2,这是由生成方法决定的;2)不同的谓词序列的数量大致等同于不同谓词的数量。
对问题的编码是在全局和局部两个层面上,以捕捉每个组件的语义信息。
全局信息的获取将整个 token 序列作为输入。使用同样的词嵌入矩阵,将 token 序列转换为向量的序列。然后通过双向 GRU 编码 token 序列。前向和后向的最终隐藏状态拼接起来,以表示全局信息。
问题的局部信息编码,是利用依赖解析表示答案和焦点结点之间长距离的依赖。问题中是没有直接的答案的,答案是用问题中的 wh-单词表示的,作者提取了从答案节点到问题中焦点结点的依赖路径。作者使用了另一个双向 GRU 层来产生依赖层次的向量表示,同时捕捉语法特征和局部的语义特征。
语义相似度计算
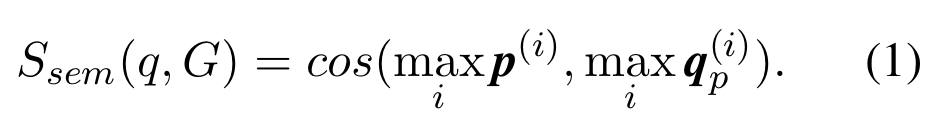

该文同样关注于复杂问题的语义分析。作者探索使用门控图神经网络对语义解析的图结构进行编码。
问题句子的表示是通过词嵌入与深度卷积神经网络学习得到,如下图左侧所示。
对于查询图,门控图神经网络(Gated Graph Neural Networks, GGNN)通过基于相邻节点和关系迭代更新图节点的表示来处理查询图。作者采用 GGNN 进行语义解析,以学习语义图的矢量表示。作者表示该文应该是首个将 GGNN 应用于语义解析和 KBQA 的工作。
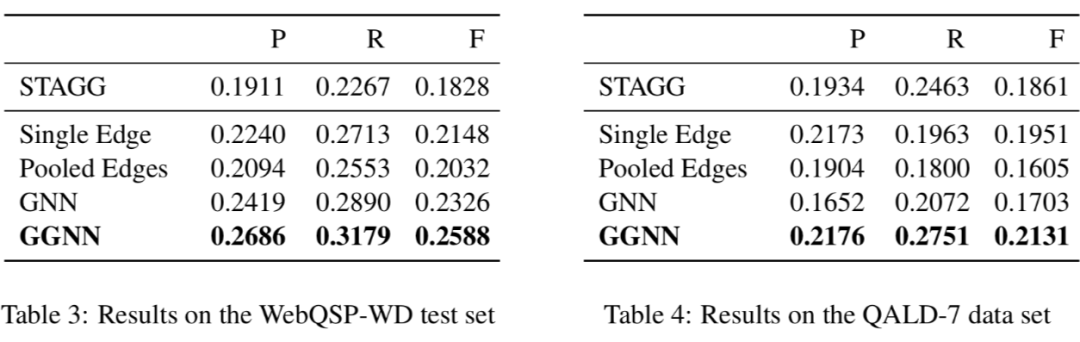
作者在 WebQuestionsSP-WD 和 QALD-7 两个数据集上进行实验,相比现有模型获得一定提升。

查询图生成与排序

槽位匹配模型
作者使用了多个模型进行实验,在此主要介绍作者提出的新颖的槽位匹配模型。作者认为现有的方法将问题和查询的核心链(core chain)都编码为各自的向量表示形式,这迫使两个序列进行复杂的转换,可能会阻碍获得最佳性能。
为了减缓这个问题,作者提出一个更结构化的编码方式,将核心链分为跳,并根据每一跳创建问题的多个表示称为槽位(slot),然后分别比较这些槽位。也就是说,问题的表示和核心链的表示不是两项分离的表示。
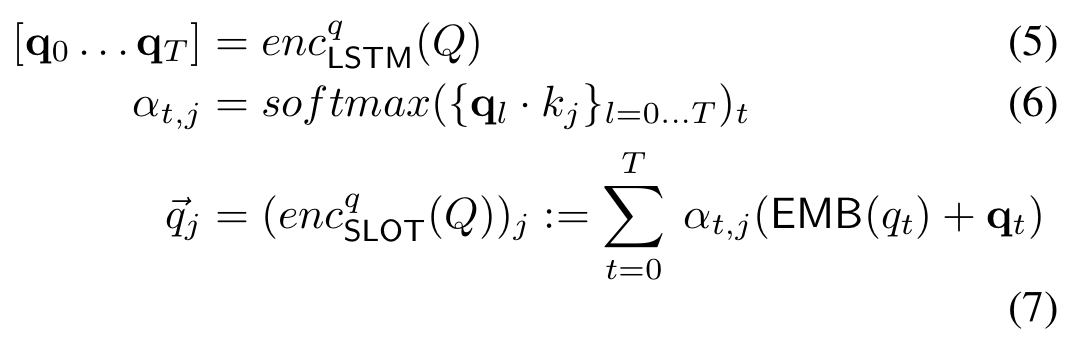
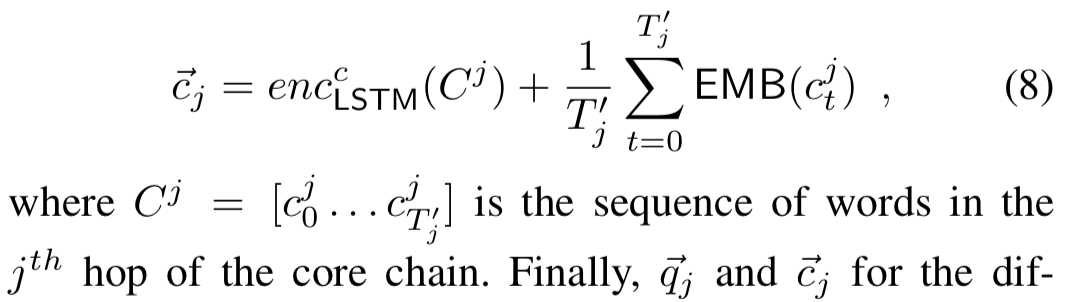
这样得到了不同槽位的问题表示和核心链的表示,将它们拼接。
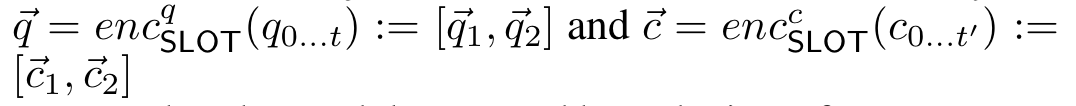
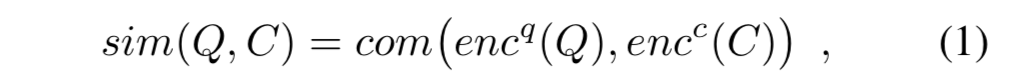
而关于比较函数 com(·),作者使用了两种实现:
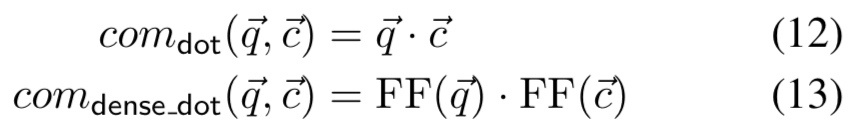
实验
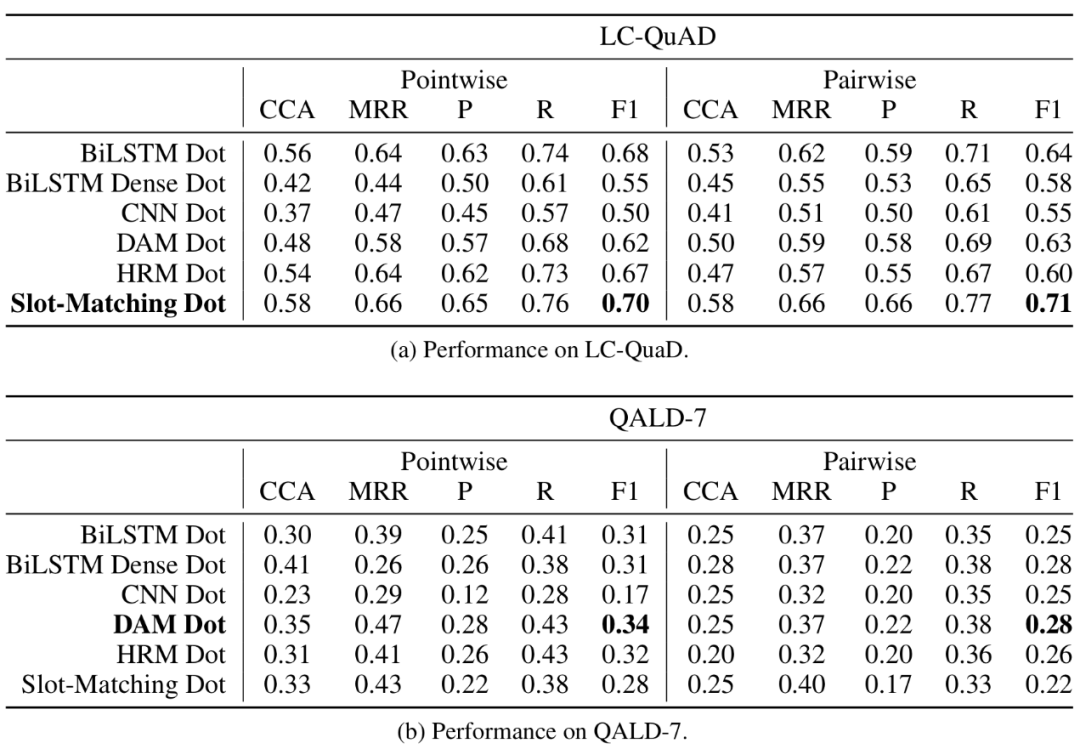

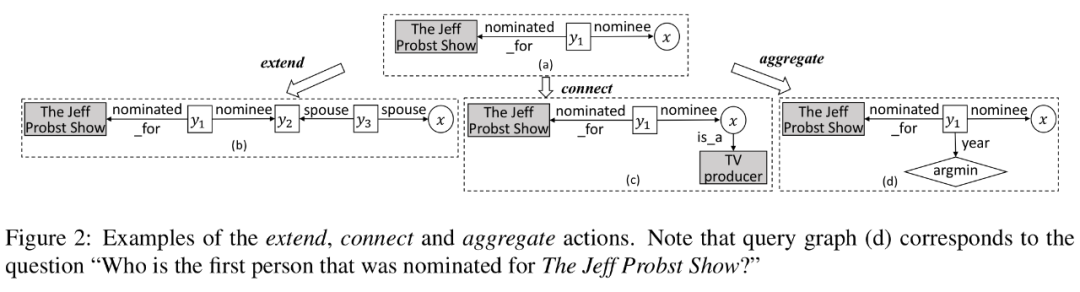
该文尝试分别处理两种类型的复杂性:具有约束的问题和具有多跳关系的问题。作者通过观察发现,尽早将约束合并到查询图中可以更有效地修剪搜索空间,作者提出了一种改进的分阶段查询图生成方法,该方法具有更灵活的生成查询图的方式。
在查询图生成的每一步,包含三种预定义的操作:扩展、连接、聚合。
这里我们主要讨论对于候选的查询图,作者使用了七维向量进行排序。对于获得的七维向量,通过 REINFORCE 算法选择出能生成正确答案的查询图。
七维向量的每一维分别是:
基于 BERT 的语义匹配模型;具体而言,通过遵循构造查询图所采取的动作序列并将每个步骤中涉及的实体和关系的文本描述顺序添加到序列中,将查询图转换为 token 序列。
查询图中所有对齐实体的累计实体链接分数。
查询图中已对齐的实体的数量。
查询图中实体类型的数量。
查询图中时间表达式数量。
查询图中最高级数量。
查询图中表示答案的实体数量。
需要注意的是,个人认为查询图并不是一个序列结构,序列化后通过 BERT 计算语义分数是否合理值得研究。

本文从四个思路出发,回顾了 KBQA 中关于复杂问题的部分研究。由于篇幅所限,许多细节尚未展开,且现有的复杂问题研究并非局限于本文所讨论的思路。
对于复杂问题,个人认为如果避开使用语义解析的方法,难以对一个问题有较准确的分析。而语义解析方法主要讨论如何利用形式化查询。
其中我们可以看到,分解的思路是避免直接处理复杂问题,而是可以通过先处理简单的问题处理复杂问题。基于依赖的方法,它对问题有一定理解能力,其目标是直接生成最符合给定问题的查询图。
另外,即使没有依赖解析方法,也可以生成大量候选查询图然后通过合理方式进行排序。此外,独立于查询图的生成方法,一些研究者关注于对查询图进行编码,然后结合设计好的相似度计算方法,找到与问题最相似的查询图。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






