深度学习图像三维重建:最新技术趋势
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
1.三维人脸重建
基于精细密集图像的人脸三维重建是计算机视觉和计算机图形学中一个长期存在的问题,其目标是恢复人脸的形状、姿态、表情、皮肤反射率和更精细的表面细节。最近,这个问题被描述为一个回归问题,并用卷积神经网络来解决。
在本节中,将回顾一些有代表性的论文。目前的技术大多采用参数化表示,即对三维曲面的流形进行参数化处理。最常用的表示是Blanz和Vetter[1]的3D变形模型(3DMM),该模型从几何和纹理的角度捕捉面部的变化。下面,将主要介绍各种网络架构及其训练过程,还将讨论一些无模型技术。
1.1网络架构
主干结构是一个编码器,它将输入图像映射到参数化模型参数中。它由卷积层和完全连接层构成。一般来说,现有技术使用诸如AlexNet之类的通用网络,或专门针对面部图像训练的网络,例如VGG Face或FaceNet。
Tran[2]使用这种结构来对编码面部特征和纹理的3DMM的198个参数进行回归。它已经通过使用L2不对称损失(有利于远离平均值的三维重建的损失函数)的三维监督进行训练。
Richardson[3]使用了类似的架构,但迭代地执行重构。在每一次迭代中,网络将之前重建的人脸,与输入的图像一起,投影到一个使用前置摄像头的图像上,并对3DMM的参数进行回归,并且用平均人脸初始化重构。结果表明,经过三次迭代,该方法可以成功地处理不同表情和光照条件下的人脸重构。
基于3DMM的方法的一个主要问题是,它们倾向于重建平滑的面部表面,而这些表面缺乏皱纹和酒窝等精细细节。因此,此类别中的方法使用求精模块来恢复细节。例如,Richardson[3]使用来自阴影的形状(SfS)技术优化重建的脸。
1.2训练和监督
训练过程中一个主要的挑战是如何收集足够多的训练图像,并用它们对应的三维人脸进行标记,从而为网络提供信息。Richardson[3]通过从可变形模型中随机抽取样本并渲染生成的面来生成合成训练数据。然而,当面对闭塞、异常光照或没有很好表现的类别时,接受纯合成数据训练的网络可能表现不佳。
Tewari[4]在没有3D监督的情况下,训练编码器-解码器网络,以同时预测面部形状、表情、纹理、姿势和灯光。编码器是一个从图像到可变形模型坐标的回归网络,解码器是一个固定的、可微的渲染层,试图再现输入的照片。
损失测量的是重新制作的照片和输入的照片之间的差异。由于训练损失是基于单个图像像素的,因此网络容易受到相关变量之间混杂变化的影响。例如,它不能轻易区分暗肤色和昏暗的灯光环境。
为了消除使用3D数据进行监督训练的需要和对反向渲染的依赖,Genova[5]提出了一个框架,该框架学习基于面部识别网络产生的面部身份特征来最小化损失。换句话说,人脸识别网络将输入的照片以及从重建的人脸中呈现的图像编码为特征向量,这些特征向量对姿态、表情、光照输入都具有鲁棒性。
然后,该方法应用一个损失来测量这两个特征向量之间的差异,而不是使用渲染图像和输入照片之间的像素级距离。仅使用人脸识别网络、可变形人脸模型和未标记人脸图像数据集训练三维人脸形状和纹理回归网络。这种方法不仅提高了先前作品的准确性,而且还生成了通常可以识别为原始对象的三维重建。
1.3无模型方法
基于可变形模型的技术仅限于建模子空间。因此,在训练数据范围之外,难以置信的重建是可能的。在三维人脸重建的背景下,也探索了其他不受此问题影响的表示方式,如体积网格。例如,Jackson[6]提出了一种体积回归网络(VRN),它将二维图像作为输入,并预测其相应的三维二值体体积,而不是3DMM。
其他技术使用中间表示方法,例如Sela[7]使用基于U-Net的图像到图像转换网络来估计深度图像和面部对应图,然后执行基于迭代变形的配准和几何细化过程来重建细微的面部细节。与3DMM不同,该方法可以处理较大的几何变化。
Feng[8]还研究了无模型方法。首先,设计了一个紧密连接的CNN框架,从水平和垂直的极平面图像中回归出三维人脸曲线。然后,将这些曲线转换为三维点云,并使用网格拟合算法拟合面部曲面。实验结果表明,该方法对不同的姿态、表达式和光照具有较强的鲁棒性。
2.三维场景分析
目前所讨论的方法主要是用于孤立物体的三维重建。具有多个对象的场景在描绘对象、正确处理遮挡、杂波、形状和姿势的不确定性以及估计场景布局方面带来了额外的挑战。解决这个问题的方法包括三维目标检测和识别、姿态估计和三维重建。传统上,这些任务中的许多都是使用手工制作的功能来完成的。在基于深度学习的时代,上诉的几个模块已经被cnn取代。
例如,Izadinia[9]提出了一种方法,该方法基于识别室内场景中的对象、推断房间几何结构、优化房间中的三维对象姿势和大小以使合成渲染与输入照片最佳匹配。该方法检测对象区域,从CAD数据库中找到最相似的形状,然后对其进行变形以适应输入。利用完全卷积网络估计房间几何结构,使用更快的R-CNN执行对象的检测和检索。但是,变形和拟合是通过“渲染和匹配”执行的。
Tulsiani[10]则提出了一种完全基于深度学习的方法。输入由一个RGB图像和对象的边界框组成,用一个四分支网络进行处理。第一个分支是具有跳跃连接的编码器-解码器,它估计场景布局的差异。第二个分支获取整个场景的低分辨率图像,并使用CNN和三个完全连接的层将其映射到一个隐空间。第三个分支与第二个分支具有相同的体系结构,它将原始分辨率的图像映射到卷积特征映射,然后进行ROI池化以获得ROI的特征。最后一层通过完全连接的层映射边界框位置。
然后将这三个特征串联起来,并用完全连接的层进行进一步的处理,接着是解码器,解码器生成ROI中对象的323个体素网格,并以位置、方向和比例的形式显示其姿势。该方法利用合成渲染图像及其相关的真实三维场景进行训练。
3.数据集
下表列出并总结了最常用数据集的属性,与传统技术不同,基于深度学习的三维重建算法的成功与否取决于大型训练数据集的可用性。有监督的技术要求图像及其相应的三维标注,其形式为以体积网格、三角形网格或点云表示的完整三维模型,也可以是密集或稀疏的深度图。另一方面,弱监督和无监督技术依赖于额外的监督信号,如外部和内部摄像机参数以及分割掩码。
为基于深度学习的三维重建收集训练数据集的主要挑战是两方面的。首先,虽然人们可以很容易地收集到二维图像,但获取它们相应的三维真实数据是一项挑战。因此,在许多数据集,如IKEA、PASCAL 3D+和ObjectNet3D中,只有相对较小的图像子集使用其相应的3D模型进行了注释。其次,ShapeNet和ModelNet等数据集是目前可用的最大的三维数据集,它们包含的三维CAD模型没有相应的自然图像,因为它们最初用于基准三维形状检索算法。
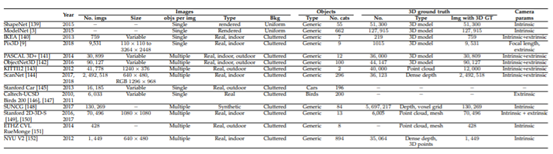
这一问题已通过数据扩充得到解决,即用综合生成的数据扩充原始集合的过程。例如,可以通过对现有图像应用几何变换(例如平移、旋转和缩放)来生成新图像和新三维模型。注意,尽管有些转换是保持相似性的,但它们仍然丰富了数据集。
还可以从现有的三维模型中综合渲染来自各种(随机)视点、姿势、照明条件和背景的新的二维和2.5D(即深度)视图。它们也可以覆盖自然图像或随机纹理。然而,这会导致域移位问题,即合成图像的空间与真实图像的空间不同,当在完全不同类型的图像上测试方法时,这通常会导致性能下降。
最后,弱监督和无监督技术最大限度地减少了对3D注释的依赖。然而,它们需要分割掩码,可以使用最新的最先进的目标检测和分割算法获得,或者摄像机参数。联合训练三维重建、分割和摄像机参数估计是特征研究的一个非常有前途的方向。
【1】V. Blanz and T. Vetter, “A morphablemodel for the synthesis of 3d faces,” in Siggraph, 1999, pp. 187–194.
【2】A. T.Tran, T. Hassner, I. Masi, and G. Medioni, “Regressing robust anddiscriminative 3D morphable models with a very deep neural network,” in IEEECVPR, 2017, pp. 1493–1502.
【3】E.Richardson, M. Sela, and R. Kimmel, “3D face reconstruction by learning fromsynthetic data,” in 3D Vision, 2016, pp. 460–469.
【4】 A.Tewari, M. Zollhofer, H. Kim, P. Garrido, F. Bernard, P. Perez, and C.Theobalt, “Mofa: Model-based deep convolutional face autoencoder forunsupervised monocular reconstruction,” in IEEE CVPR, 2017, pp. 1274–1283.
【5】 K.Genova, F. Cole, A. Maschinot, A. Sarna, D. Vlasic, and W. T. Freeman,“Unsupervised Training for 3D Morphable Model Regression,” in IEEE CVPR, 2018.
【6】A. S.Jackson, A. Bulat, V. Argyriou, and G. Tzimiropoulos, “Large pose 3d facereconstruction from a single image via direct volumetric cnn regression,” inIEEE CVPR, 2017, pp. 1031–1039.
【7】M. Sela,E. Richardson, and R. Kimmel, “Unrestricted facial geometry reconstructionusing image-to-image translation,” in IEEE CVPR, 2017, pp. 1576–1585.
【8】M. Feng,S. Zulqarnain Gilani, Y. Wang, and A. Mian, “3d face reconstruction from lightfield images: A model-free approach,” in ECCV, 2018, pp. 501–518.
【9】H.Izadinia, Q. Shan, and S. M. Seitz, “Im2cad,” in IEEE CVPR, 2017, pp.5134–5143.
【10】S.Tulsiani, S. Gupta, D. F. Fouhey, A. A. Efros, and J. Malik, “Factoring shape,pose, and layout from the 2D image of a 3D scene,” in IEEE CVPR, 2018, pp.302–310.
从0到1学习SLAM,戳↓
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
文章不错,点个赞



