面向深度学习的分布式文件系统
当你用大量高质量训练数据训练深度学习模型时,可能会刷新多个领域的模型最佳预测表现(例如图像分类、语音识别和机器翻译)。作为训练数据、日志、模型服务、检查点的存储中心,分布式文件系统正变得越来越重要。HopsFS就是不错的选择,它可以本地支持数据科学主流的Python框架,例如Pandas、TensorFlow/Keras、PySpark和Arrow。
数据集尺寸增加,预测性能增加
百度研究院曾经提出,可以根据训练数据的数量,判断深度学习模型预测的精确度是否能提高(或者能否生成更少的错误)。根据下方的对数坐标图可以看出,随着训练数据的尺寸增加,生成的错误不断减少,呈幂律分布。这一结果来源于对多领域不同的机器学习模型的研究,包括机器翻译、语言建模、图像分类、语音识别。假设这一结果在多个应用领域都通用,那么有可能在你的研究领域也成立。对正在考虑大规模投资深度学习的公司来说,这一结果非常重要。假设生成或收集1GB的新训练数据需要花费X美元,你就能预测它能为模型精确度提高多少。
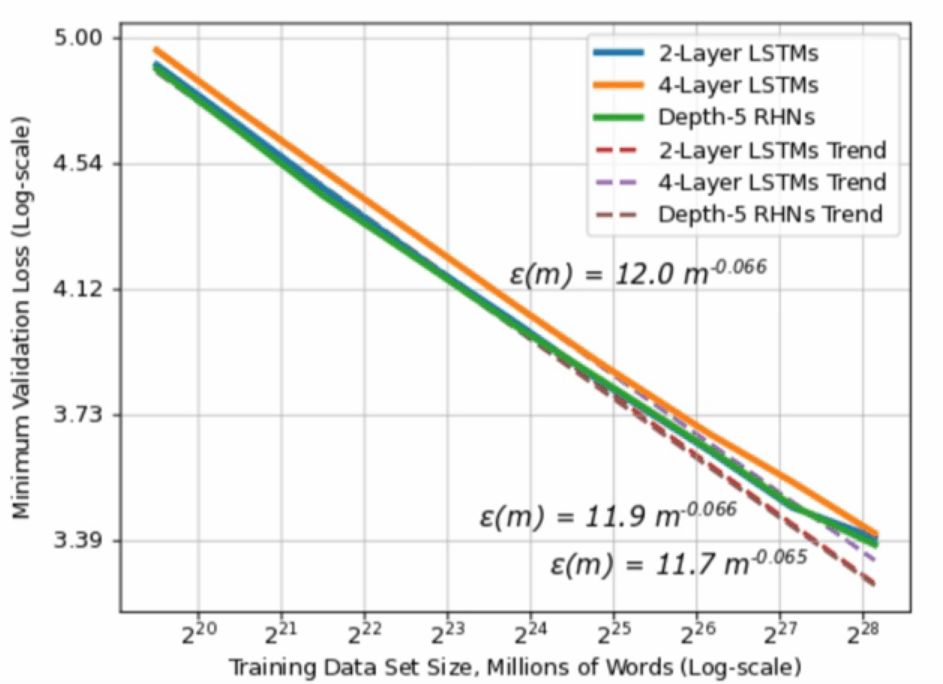
来源:百度研究院research.baidu.com/deep-learning-scaling-predictable-empirically/
可预测的投资回报率
这里通过收集或生成更多训练数据而得到的可预测投资回报率(ROI)比上面的概念稍复杂。首先,你需要收集到足够多的数据,如下图所示,使数据量超过“Small Data Region”,在幂律区域中,才能用足够的数据做出预测。
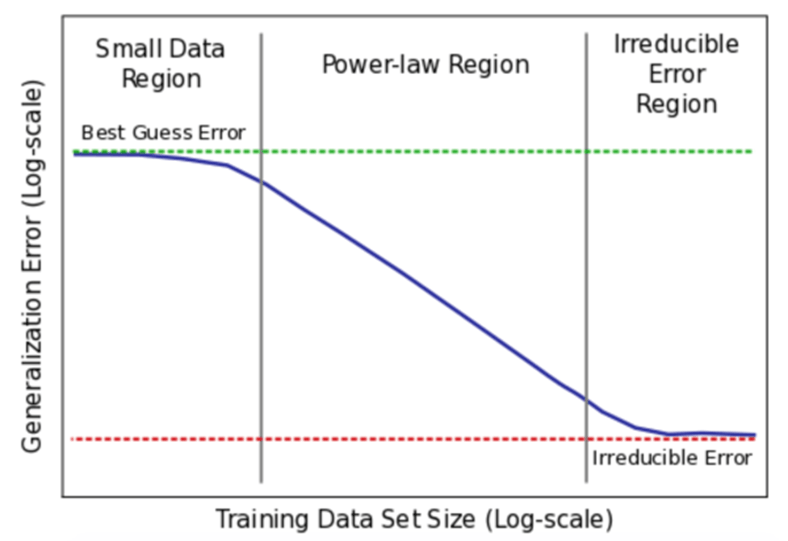
来源:百度arxiv.org/pdf/1712.00409.pdf
你可以根据你模型生成的错误数量变化绘制出函数图像,并联系起训练数据的多少制定出对数坐标。通过观察你模型的直线变化,计算你的幂律图形中的指数(图形的斜率)。百度的实证结果表明,在它们绘制的学习曲线上,指数的范围在-0.35到-0.07之间,说明模型在学习真实世界数据时比理论上要慢(理论上模型的理想幂律指数为-0.5)。
并且,如果你观察了幂律区域,当训练数据集的尺寸增加时,模型预测的生成错误会减少。例如,如果你在为一辆自动驾驶汽车训练图像分类器,那么小车自动形式的时间决定了训练数据的尺寸。所以,自动驾驶的时间越长,图像分类器出错的机会就越少,并且是可以预测的。这对商业领域来说,能够通过数据增加判断精确度增加,是非常重要的一点。
分布式文件系统的必要性
TensorFlow团队在2018年TensorFlow开发者峰会上表示,一个分布式文件系统对深度学习来说是必需的。数据集越来越大,GPU不仅仅要实现存储,还需要协调模型检查点、超参数优化和模型架构搜索。你的系统可能需要多个服务器,所以,一个分布式文件系统可以将你的机器学习流程中的不同阶段融合起来,可以让团队成员共享GPU硬件和数据。重要的是,分布式文件系统能根据你的编程语言和深度学习框架工作。
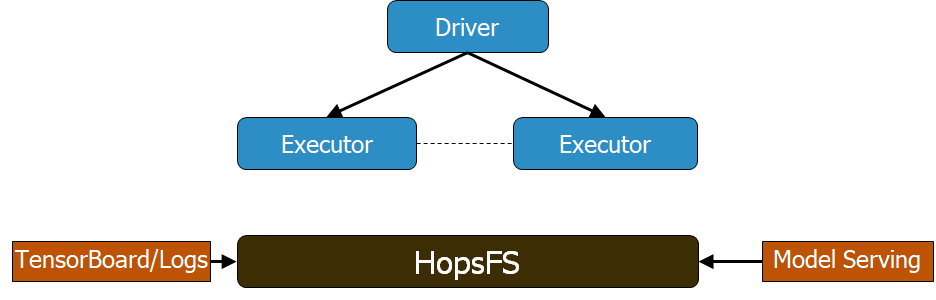
管理日志、TensorBoard、协调GPU、存储检查点等都需要分布式文件系统
前面我们说到,HopsFS是一种不错的选择,它是HDFS的替代。HopsFS/HDFS都支持主流的Python框架,例如Pandas、PySpark数据框架、TensorFlow数据等等。在Hopsworks中,我们提供嵌入式的HopsFS/HDFS支持,以及pydoop库。HopsFS有一个针对机器学习工作负载的特征,即对小型文件,它改善了吞吐量,并将降低了读取/书写的延迟。我们在Middleware 2018上有一篇经过同行审议的论文,证明了和之前的HDFS处理小文件相比,HopsFS的吞吐量提高了66倍。
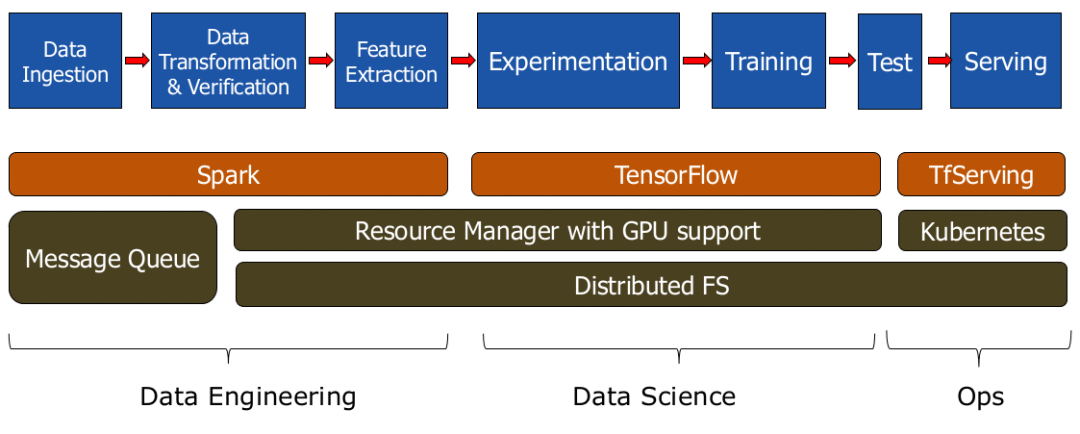
Python在分布式文件系统中的支持情况
下表体现出不同分布式文件系统所支持的框架:
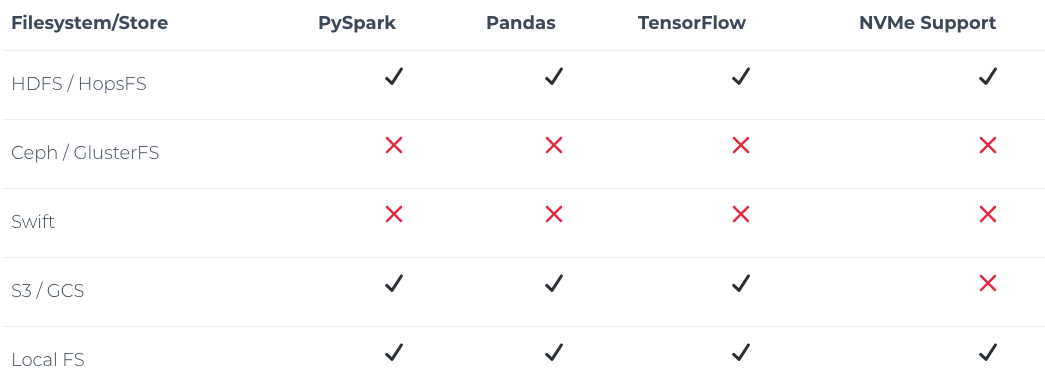
HopsFS中Python的支持情况
下面我们介绍几个用Python代码在HopsFS中使用数据集的例子,完整Notebook地址:github.com/logicalclocks/hops-examples/tree/master/tensorflow/notebooks
Pandas
import hops.hdfs as hdfs
cols = [“Age”, “Occupation”, “Sex”, …, “Country”]
h = hdfs.get_fs()
with h.open_file(hdfs.project_path()+“/TestJob/data/census/adult.data”, “r”) as f:
train_data=pd.read_csv(f, names=cols, sep=r’\s*,\s*’,engine=‘python’,na_values=“?”)
用Pandas时,和本地文件系统相比,我们唯一要改变代码的地方就是将openfile(..)改成h.openfile(..),其中h是HDFS/HopsFS中文档处理的指令。
PySpark
from mmlspark import ImageTransformer
IMAGE_PATH=“/Projects/myProj/Resources/imgs”
images = spark.readImages(IMAGE_PATH, recursive = True, sampleRatio = 0.1).cache()
tr = (ImageTransformer().setOutputCol(“transformed”)
.resize(height = 200, width = 200)
.crop(0, 0, height = 180, width = 180) )
smallImgs = tr.transform(images).select(“transformed”)
smallImgs.write.save(“/Projects/myProj/Resources/small_imgs”, format=“parquet”)
TensorFlow数据集
def input_fn(batch_sz):
files = tf.data.Dataset.list_files(IMAGE_PATH)
def tfrecord_dataset(f):
return tf.data.TFRecordDataset(f, num_parallel_reads=32, buffer_size=8*1024*1024)
dataset = files.apply(tf.data.parallel_interleave(tfrecord_dataset,cycle_length=32))
dataset = dataset.prefetch(4)
return dataset
参考资料
Deep Learning Scaling is Predictable, Empirically by Baidu:arxiv.org/pdf/1712.00409.pdf
Morning Blog review by Adrian Colyer:blog.acolyer.org/2018/03/28/deep-learning-scaling-is-predictable-empirically/
Distributed Deep Learning on Hops, Spark Summit Talk
Example Jupyter Notebook for working with files in HopsFS:github.com/logicalclocks/hops-examples/blob/master/tensorflow/notebooks/Filesystem/HopsFSOperations.ipynb
原文地址:www.logicalclocks.com/why-you-need-a-distributed-filesystem-for-deep-learning/