MIT和Google等提出:新全景分割算法 DeeperLab
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

前戏
最近图像分割方向,出了很多paper,CVer也立即跟进报道(点击可访问):
【导读】本文介绍一篇很棒的新全景分割算法:DeeperLab。该论文是由麻省理工学院、Google和伯克利加州大学联名提出。从DeeperLab名字可以看出,该算法与DeepLab有着不解之缘。前者用来解决 Whole Image Parsing问题,也就是 Panoptic Segmentation(全景分割)问题,后者是用来解决Semantic Segmentation(语义分割)问题。
注:为什么叫DeeperLab,一方面是基于DeepLab,另一方面,毕竟是全家桶命名法嘛。之后可能会有DeeperLabv2、DeeperLabv3等...
简介
《DeeperLab: Single-Shot Image Parser》

arXiv: https://arxiv.org/abs/1902.05093
github: None
作者团队:MIT & Google & UC Berkeley
注:2019年02月15日刚出炉的paper
Abstract:我们提出了一种用于image parsing(图像解析)的 single-shot, bottom-up 的方法。Whole image parsing(整幅图像解析),也称为全景分割,涵盖了 “stuff” 类的语义分割任务和 “thing” 类的实例分割,为图像中的每个像素分配语义和实例标签。最近的 whole image parsing 方法通常使用单独的独立模块来进行组成语义和实例分割任务,并且需要多次推断。相反,本文提出的DeeperLab image parser(图像解析器)使用一种非常简单的全卷积方法执行 whole image parsing,该方法以 single-shot 方式联合处理语义和实例分割任务,从而使得流线型系统更适合快速处理。对于定量评估,我们使用基于实例的全景质量(PQ)度量,并提出基于区域的分析覆盖(PC)度量,它更好地捕获 “stuff” 类和更大物体实例上的图像分析质量。我们介绍了具有挑战性的 Mapillary Vistas 数据集的实验结果,其中我们的单一模型在GPU上实现了31.95%(val)/ 31.6%PQ(测试)和55.26%PC(val),每秒3帧(fps)或接近实时速度(GPU上为22.6 fps),精度会降低。
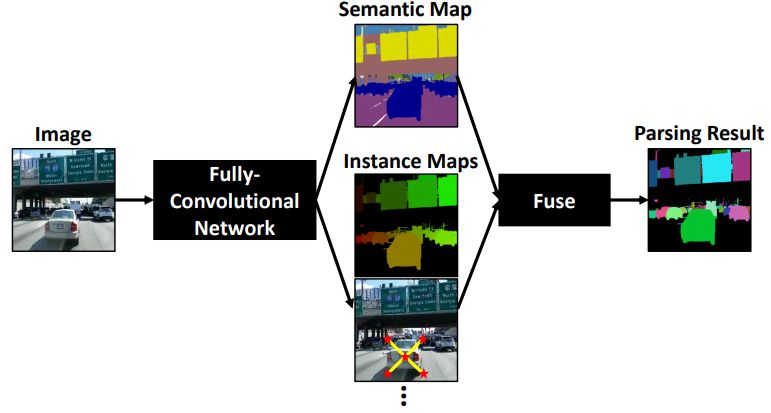
The proposed single-shot, bottom-up image parser, DeeperLab
正文
注:本文所使用的"我们"是指论文作者团队,在此致敬原作者团队分享这么棒的work
主要贡献
1)我们为高效的 image parsers 提出了几种神经网络设计策略,特别是减少了高分辨率输入的内存占用。这些创新包括广泛应用 depthwise separable convolution(深度可分离卷积),使用带有简单的两层预测头的共享解码器输出,扩大 kernel 大小而不是使网络更深,采用 spaceto-depth and depth-to space 而不是上采样,并采用 hard data mining 。还提供了详细的 ablation(消融)研究,以验证这些策略在实践中的作用。
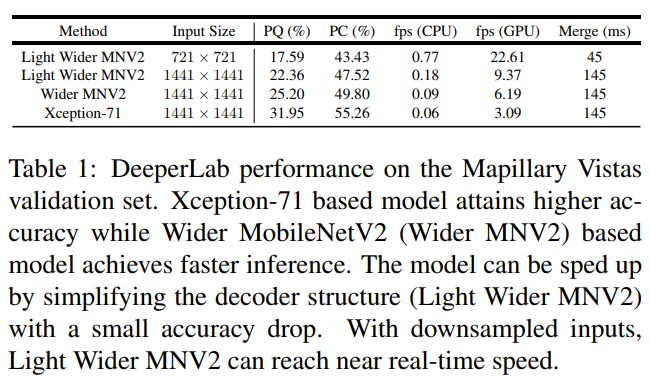
2)我们基于提出的设计策略,提出了一种高效的 single-shot, bottom-up image parser:DeeperLab。例如,在 Mapillary Vistas 数据集上,基于Xception-71 [5,6,7]的模型实现了31.95%PQ(val)/ 31.6%(测试)和55.26%PC(val),每秒3帧(fps)在GPU上。我们的新型更广泛的基于MobileNetV2 [8]的模型可以实现接近实时的性能(GPU上为22.61 fps),当然精度会有所降低。
3)我们提出了一种新的度量标准:Parsing Covering,用于从基于区域的角度评估 image parsing 结果。
Parsing Covering 即将开源,链接:http://parsingcovering.mit.edu/
此外,我们还在补充材料中介绍了DeeperLab在其他数据集上的实验结果(Cityscapes,Pascal VOC 2012和COCO)。
具体方法
1 Encoder
我们已经尝试了两个基于有效深度可分离卷积的网络:标准Xception-71 ,用于更高精度,以及一个新的MobileNetV2变体:Wider MobileNetV2,用于更快的推理.
2 Decoder
Decoder 模块的目标是恢复详细的物体边界。在DeepLabV3+之后,我们采用了一种简单的设计,它将 encoder输出的 activations (步长16)与来自网络 backbone 的低级特征映射(步长4)相结合。
3 Image Parsing Prediction Heads
所提出的网络包含五个预测 heads,每个预测 heads 直接连接到共享 decoder 输出,并且由两个 kernel 尺寸分别为7×7和1×1的卷积层组成。
3.1 Semantic Segmentation Head
我们提出的 bootstrapped cross-entropy loss 定义为如下:
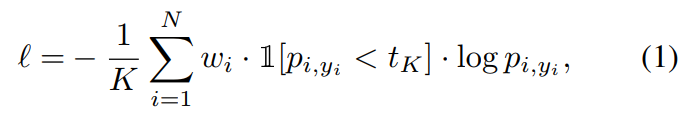
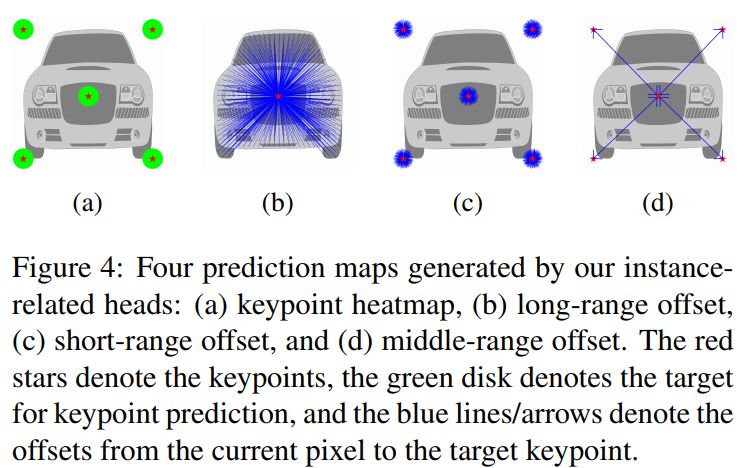
3.2 Instance Segmentation Heads
我们为目标实例采用基于关键点的表示。受 PersonLab 启发,我们定义了四个预测 heads,用于实例分割:【1】The keypoint heatmap 【2】The long-range offset map 【3】The short-range offset map 【4】The middle-range offset map。 这些预测的重点是预测每个像素与其相应实例的关键点之间的不同关系,我们将其融合以形成类别不相关的实例分割。
4 Prediction Fusion
Instance Prediction
Semantic and Instance Prediction Fusion
5 Evaluation Metrics
PQ
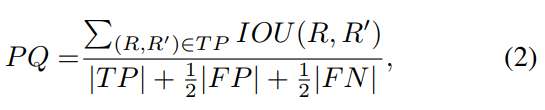
PC
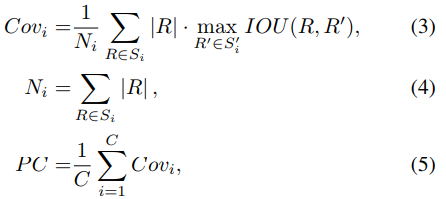
实验结果
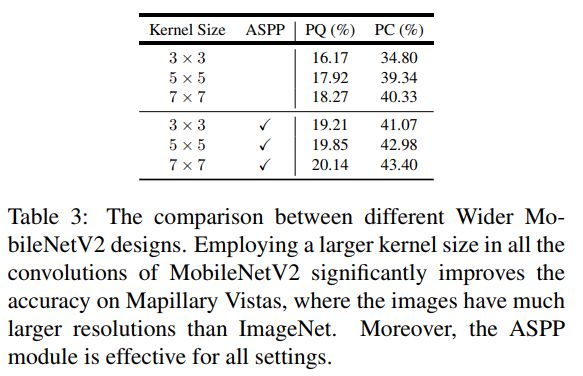

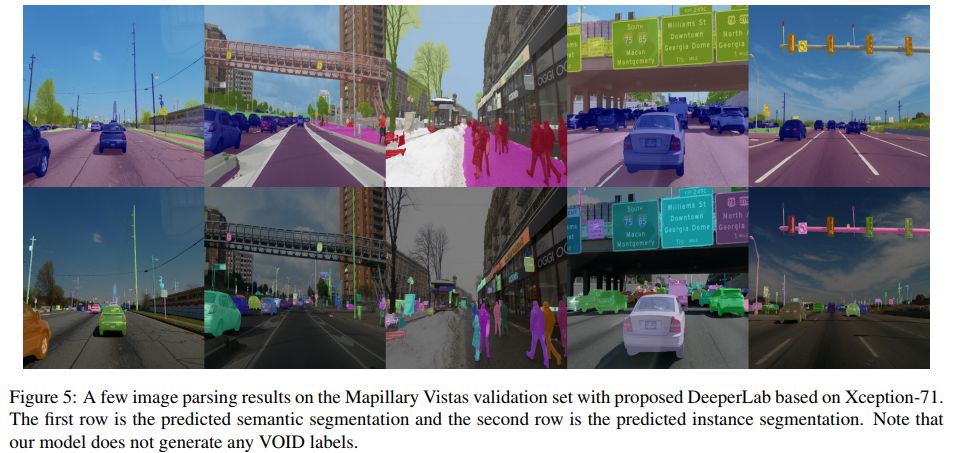
结论
DeeperLab 作为新的全景分割算法,其在精度和速度之间取得了很好的平衡,论文中做了大量实验和tricks。
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!

