视频分割在移动端的算法进展综述
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:陈泰红
https://zhuanlan.zhihu.com/p/60621619
本文已授权,未经允许,不得二次转载
语义分割任务要求给图像上的每一个像素赋予一个带有语义的标签,视频语义分割任务是要求给视频中的每一帧图像上的每一个像素赋予一个带有语义的标签。
视频分割是一项广泛使用的技术,电影电视特效、短视频直播等可以用该技术将场景中的前景从背景中分离出来,通过修改或替换背景,可以将任务设置在现实不存在不存在或不易实现的场景、强化信息的冲击力。传统方式可通过视频图像的手工逐帧抠图方式(摄影在带绿幕的专业摄影棚环境摄制,后期特效完成背景移除切换图 1),比如《复仇者联盟》《美国队长》《钢铁侠》等通过专业软件(比如Pr、会声会影)加入各种逼真的特效,让影片更加有趣,更加震撼。可以想象2019年北京卫视和浙江卫视有了这样的特技,不需要人工逐帧抠图ps某吴姓知名大叔,将是多么的和谐…

本文首先综述视频分割的基础,比如视频目标分割的分类,评价指标和数据集,详细介绍Google为youtube app设计的移动端视频分割方法, 以及CVPR2019视频分割领域取得的最新进展,简单介绍RVOS、重点介绍在分割精度和实时性取得平衡的FEELVOS和SiamMask。
1 视频分割基础
1.1 视频目标分割分类
语义分割分为图像的语义分割和视频语义分割,如所示。
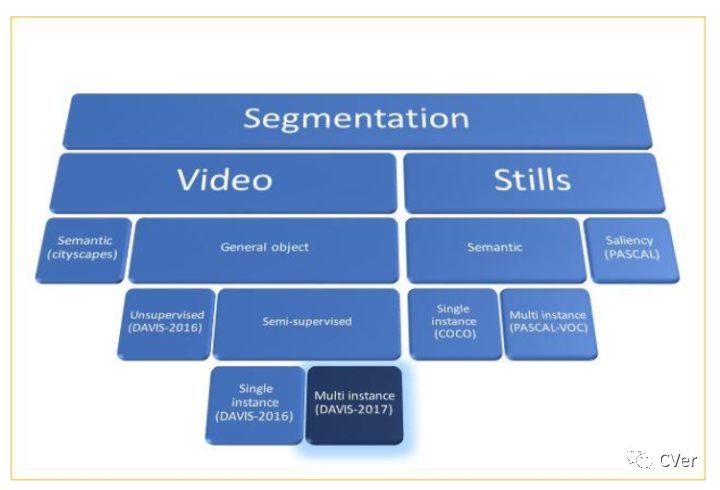
基于图片的语义分割经典算法包括FCN,SegNet、Dilated Convolutions、DeepLab (v1 & v2& v3)、RefineNet、PSPNet、Large Kernel Matters等。但是,视频目标分割任务和图片的语义分割有两个基本区别:视频目标分割任务分割的是非语义的目标,并且视频目标分割添加了一个时序模块,它的任务是在视频的每一连续帧中寻找目标的对应像素。直接使用经典的语义分割算法难以达到视频处理的性能,这也是为什么基于时序的MaskTrack算法优于基于视频独立帧独立处理的OSVOS算法。
1.2 视频分割评价指标
视频目标分割评价指标包括轮廓精确度(Contour Accuracy)和区域相似度(Region Similarity),时序稳定度Temporal stability。
区域相似度(Region Similarity):区域相似度是掩膜 M 和真值 G 之间的 Intersection over Union 函数
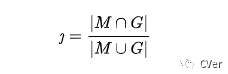
轮廓精确度(Contour Accuracy):将掩膜看成一系列闭合轮廓的集合,并计算基于轮廓的 F 度量,即准确率和召回率的函数。即轮廓精确度是对基于轮廓的准确率和召回率的 F 度量。
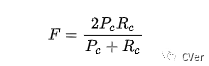
直观上,区域相似度度量标注错误像素的数量,而轮廓精确度度量分割边界的准确率。
1.3 视频分割数据集
视频分割领域的数据集包括DAVIS系列(DAVIS-2016,DAVIS-2017,DAVIS-2018),youtube-VOS,GyGO: E-commerce Video Object Segmentation by Visualead(电商视频目标分割数据集),KITTI MOTS(Multi-Object Tracking and Segmentation)and MOTS Challenge Datasets。
2 Google:移动端实现视频分割
2.1 移动终端与视频分割
在移动终端可以实现视频分割,比如华为Mate 20系列其新增的人像留色功能(人像留色或人像分割是视频分割的一部分,分割目标是人类),能够在录像过程中,实时识别出人物的轮廓,然后通过AI优化只保留人物身上的颜色,将周边景物全部黑白化,如此一来使人物主体更加突出,打造大片既视感。

如图 3所示,图片中的人物主体,衣服的颜色、人体肤色、头发的颜色得以悉数保留。反观作为背景的地面、栏杆、台阶以及远方的树木等景物,统一变成了黑白色。整体看起来,十分具有电影大片的既视感。
本节主要介绍谷歌为手机设计的用摄像头实时创造视频分割的抠图技术[1],文章中实现的视频人像分割的效果非常惊人,而且在iPhone 7上能跑 100+ FPS。

stories 是 YouTube 的轻量视频格式。将视频分割整合stories,给 YouTube app 带来精确、实时、便携的移动视频分割体验(需要翻墙体验)。Google提供的视频分割技术不需要专业设备,让创作者能方便地替换和修改背景,从而轻易地提高视频的制作水准。以移动端神经网络解决语义分割为基础,满足以下条件:
l 移动端的解决方案必须是轻量级的,对于实时推断,达到每秒 30 帧的分割速度。
l 视频模型需要利用时间冗余度(相邻帧看起来相似),和具备时间一致性(相邻帧得到相似的结果)。
l 高质量的分割结果需要高质量的标注。
2.2 标注数据集
为了实现高质量的数据集,google标注了10w+的图片,这些图片包括丰富的前景和背景信息。前景标注实现精细化的像素级定位,比如头发、眼睛、颈部、皮肤、嘴唇等,取得98%以上IoU的人工标注质量。目前google没有公开这部分数据集(图 5),可以使用另外一个开源的数据集Supervisely Person Dataset[2]替代完成模型的训练。

2.3 网络架构
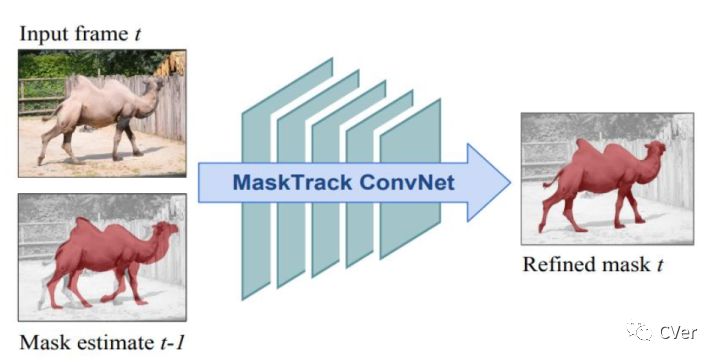
谷歌设计的模型参考[3],网络模型的输入帧是当前帧(t)RGB三通道+上一帧(Prior Mask,t-1帧)的二进制掩码。Prior Mask是上一帧的推理结果,如果是视频的首帧,Prior Mask可以是all zero的一个matrix。
在模型训练时没有视频首帧的mask,所以需要使用算法把ground truth mask 转化成可能的Prior Mask。Google使用[3]的方法:
l 直接使用Empty previous mask ,模拟视频的首帧。
l 对 ground truth mask做仿射变换,模拟人对着镜头左右/上下/前后移动。
l 对 ground truth mask做thin-plate splines变换,Google的说法是可以模拟摄像头的快速移动和旋转。
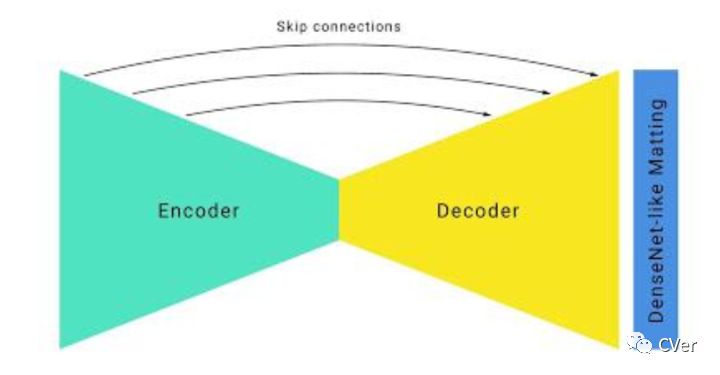
Google在移动端采用Unet+Hourglass架构。Hourglass在人体姿态估计常用的一种架构,模型推断速度很慢,Google做一下改进:
l 采用大卷积核且stride=4以上,提取RGB特征,较少运算复杂度。
l 使用大尺度下采样和Unet跳跃连接,加速在上采样时恢复低层次特征。
l 修改ResNet bottleneck。ResNet bottleneck实现信道压缩4倍(256通道特征压缩到64通道),而Google压缩到16通道,且无显著降低特征质量。
l 为了改善人像边缘的准确度,在网络的最后接了几层DenseNet Layer(使用了 Deep Image Matting 中的一些idea)。
Google的这些改进措施在移动端设备快速运行,在iPhone 7上实现了100+ FPS,在Pixel 2上实现了40+ FPS,在Google自己标注的数据集上实现IoU94.8% 的精度,为YouTube stories实现流畅的运行效果。
由于Google公布的技术仅在一篇blog[1],没有公布训练细节和详细的网络架构,为复现增加不少困难。
2.4 优缺点分析
Google实现的移动端视频分割,实现在普通设备运行特效的可行性。iPhone 7貌似也不算低端手机,华为在Mate 20实现人像留色,AI进入人类生活的方方面面。
Google提出很多可以借鉴的方向,比如模型压缩可以使用魔改ResNet bottleneck,大卷积核和大的stride。数据集方面可以采用视频分割常用的Lucid Dreaming(其实是ground truth进行放射变换并随机放在图像上,数据增强的一种方式)。
Google没有开源自家数据集和模型细节,模型的复现增加一些困难。
3 FEELVOS
FEELVOS[5]是德国亚琛工业大学和Google联合提出的视频分割算法,主要解决半监督视频分割中推断速度慢,网络结构复杂,神经网络依赖于第一帧的fine-tuning,基于embedding向量机制、global matching和local matching,实现多目标分割,模型简单,推断迅速,端到端实现且较高鲁棒性,在DAVIS2017的验证集上J&F有65%,取得视频分割速度和精度的平衡。
3.1 Motavation
DAVIS Challenge on Video Object Segmentation是CVPR会议之一的workshop,其中semi-supervised video object segmentation任务验证偏向J&F指标,对模型的实时性要求不高,比如2018 DAVIS challenge的冠军模型PReMVOS集成4个不同的神经网络,视频每帧推断时间38秒,无法满足实时性的要求。论文设计一个简单(单一神经网络),推断快速(不需要使用第一帧做微调),端到端实现且应用于多目标分割,在DAVIS 2017首先较高的鲁棒性。
论文基于Pixel-Wise Metric Learning (PML),提出一种学习embedding向量的方法和邻近匹配(包括global matching,local matching)作为神经网络的特征,结合backbone feature,前一帧预测mask共4个维度特征用于端到端的模型训练。
3.2 网络架构
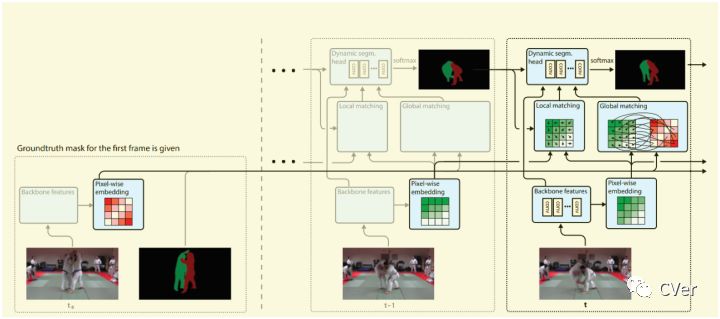
如图 8所示FEELVOS神经网络的架构,包括backbone feature,pixel-wise embedding,local matching,global matching等Dynamic segmentation head部分。
在视频处理过程中,视频中每一帧的每一个object经过backbone提取基础特征和embedding layer提取embedding特征。根据embedding向量,当前帧和前一帧之间计算local matching distance map、当前帧和视频第一帧之间计算global matching distance map。Dynamic segmentation head堆叠4个特征(backbone feature,ocal matching distance map,global matching distance map,前一帧mask预测),使用深度可分离卷积以及softmax预测当前帧的mask信息。
以上计算过程是针对每一个object计算,随着object增多,计算时间线性增加。
论文采用的backbone 是去除最后一层的DeepLabv3+(Xception-65,特征分辨率相对于原RGB图像缩小4倍),再加了一个embedding layer输出embedding向量。backbone的提取特征是共享方式,既每个图像计算一次特征。每一个embedding向量对应stride=4的RGB图像区域。不同帧图像或同一图像的两个像素属于同一类,其embedding向量距离很近,如果两个像素属于不同类别,其embedding向量距离较远。
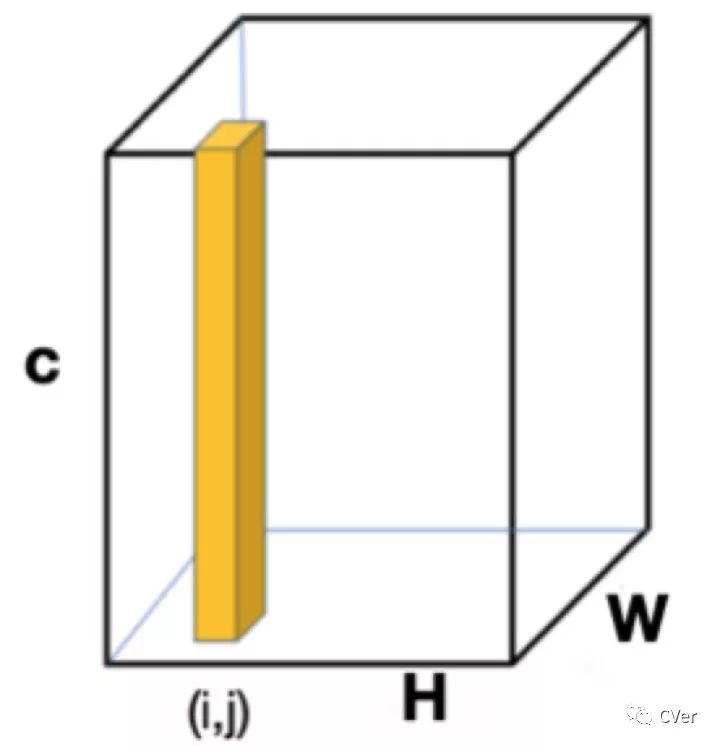
p,q表示两个像素,ep 和 eq 分别表示对应的embedding向量, 表示embedding空间距离,其计算方式为:
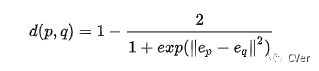
d(p,q) 取值范围是[0,1]之间。对于相同类别的像素,我们可以很轻松的求出d的值应该很接近0或者为0;对弈不同类别的像素,d接近1或者为1。
embedding layer由深度可分离卷积构成,既3x3卷积层和1x1卷积,提取特征维度是100。在pixel-wise embedding基础上,当前帧和视频第一帧之间计算global matching distance map。当前帧和前一帧之间计算local matching distance map。
global matching distance map的计算比较耗费时间。论文中输入图像像素为465x465,embedding layer输出为为(465/4)x(465/4)x100,每一帧都需要和第一帧计算distance map,比较耗费时间。
local matching distance map的计算可简化。前一帧和当前帧中目标的移动一般是很小的,没有必要还去用当前embedding feature的一个向量对所有的第一帧的embedding向量计算距离仅在一个k邻域的大小中计算距离。
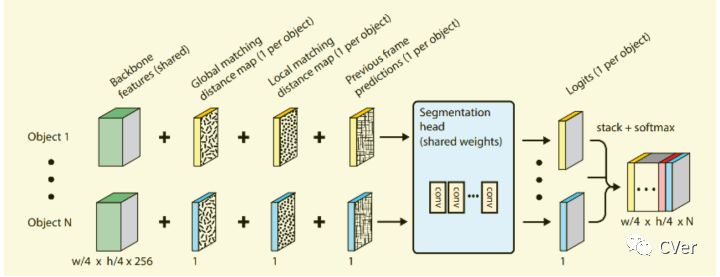
Dynamic segmentation head网络输入为4类:backbone feaures、global matching distance map,、local matching distance map和前一帧的mask输出。
Dynamic segmentation head由四个深度分离卷积(7x7卷积核)组成,产生一个一维的feature map(1 x w/4 x h/4)用来预测类别,对于每一个目标都需要Dynamic segmentation head计算logits。
论文实验环境进行Ablation Study,Dynamic segmentation head网络有四个输入,作者分别disable其中一些输入,做了6个实验。证明了local matching和global matching很重要,丢弃它们会导致网络性能的大幅下降。
3.3 优缺点分析
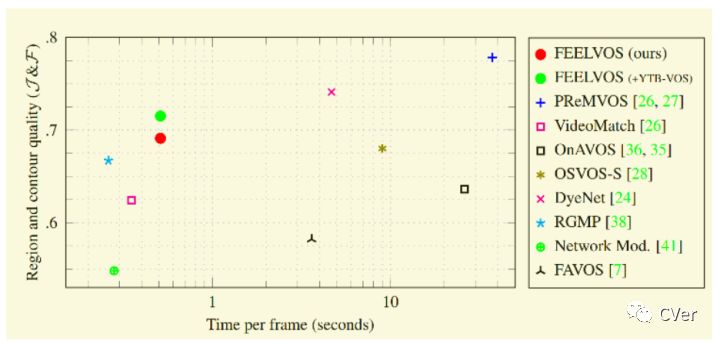
1、如图 11所示,FEELVOS在性能和耗时实现平衡,耗时在0.6s/帧左右,实时性需要进一步调试。
2、Global matching阶段需要当前帧和首帧的特征图计算所有的匹配关系,论文已经简化为采样首帧的每个object 1024像素,依然计算量较大。
3、不需要每帧都和首帧计算Global matching,在运动缓慢的视频,比如跳跃5帧或10帧计算。只有local matching计算会带来累计误差,而Global matching可以做到矫正累计误差。
4、在计算当前帧的mask时依赖于前一帧的mask,随着视频序列的增加,mask误差会累计增加,建议增加一个mask监督对齐的过程。
5、模型对首帧ground truth影响较大。比如在论文提供的实验中,首帧是一个猫的分割图,背部区域没有标记,在其后预测中猫的背部区域预测不是很好。
4 RVOS
视频目标分割依赖于时序相关性和空间相关性,而LSTM在处理时间序列具有天然的优势。在ConvLSTM基础上,来自加泰罗尼亚开放大学的学者提出基于RNN实现的视频分割算法ROVS,解决one-shot和zero-shot多目标视频分割问题,在P100 GPU达到44ms/帧的推断处理速度。
4.1 ConvLSTM
LSTM已经在语音识别、视频分析、序列建模等领域取得了非常精彩的进展,传统的LSTM网络由input gate, forget gate, cell, output gate, hidden五个模块组成。
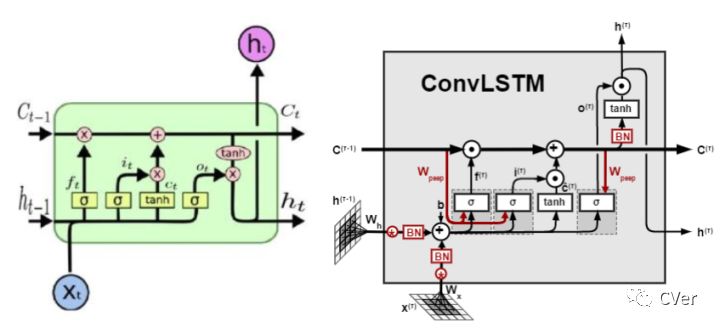
LSTM结构我们也可以称之为FC-LSTM,因其内部门之间是依赖于类似前馈式神经网络来计算的,而这种FC-LSTM对于时序数据可以很好地处理,但是对于空间数据来说,将会带来冗余性,原因是空间数据具有很强的局部特征,但是FC-LSTM无法刻画此局部特征。ConvLSTM尝试解决此问题,做法是将FC-LSTM中input-to-state和state-to-state部分由前馈式计算替换成卷积的形式图 12。
4.2 网络架构
如图 13所示RVOS网络架构,其backbone是典型的Encoder-Encoder,每帧图像中N个目标对应N个RNN。论文提出的模型解决两个问题one-shot and zero-shot VOS。
one-shot VOS既普通的DAVIS任务,给定初始化帧的mask和图像序列,预测视频序列的mask。对于zero-shot VOS任务,输入仅为RGB图像。
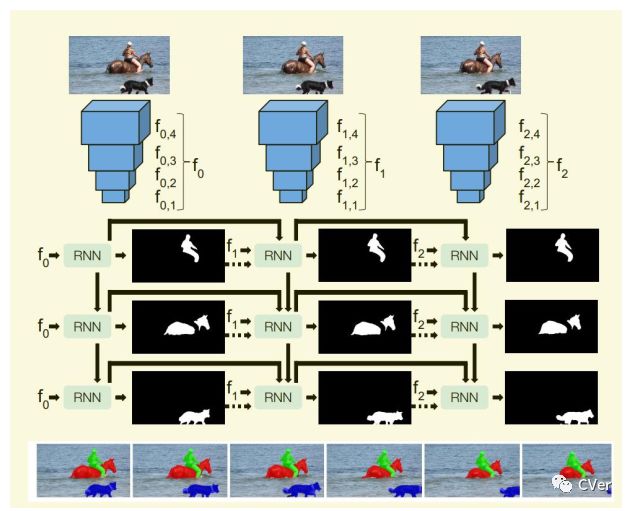
zero-shot VOS从视频序列中分割没有任何先验知识的目标,模型必须检测和分割出现在视频中的目标。YouTube-VOS和DAVIS是为one-shot VOS设计,在视频序列中会出现初始化帧没有的对象且没有标注信息,给 zero-shot VOS带来很大的困难。论文是在每帧图像中分割10个对象目标,期望5属于预测对象。
4.3 优缺点分析
1、多目标实体分割的性能依赖于分割实体的数目。
2、RNN虽然处理时序可空间具有明显优势,ConvLSTM也可用于处理图像,但是对存储空间的依靠高,推断时间上不易达到实时性的需求。
3、个人认为zero-shot VOS已经脱离了VOS范畴,可以视频分解为序列图形,单独在每个图像上做实体分割,在进行图像之间的匹配。
5 SiamMask
5.1 Motavation
目标跟踪(Tracking)和视频目标分割( video object segmentation,VOS)虽然同属视频分析领域,一直井水不犯河水。视觉目标跟踪任务就是在给定某视频序列初始帧的目标大小与位置的情况下(一般为标注框形式),预测后续帧中该目标的大小与位置。早期的跟踪算法使用坐标轴对齐的矩形框,而在VOT2015之后使用旋转矩形框,对跟踪精度要求的提高,实时是mask的近视计算。
VOS是给定初始帧的mask,预测视频序列的mask。在VOS领域,一般基于光流法,离线训练且需要初始帧的mask真值做finetune,为了精度而降低实时性,限制了视频分割的应用范围。
中科院自动化所和牛津大学设计的SiamMask[8],将视频目标跟踪和视频分割结合起来,实现实时像素级的目标定位。初始化简单,仅需要在初始帧给出目标的包围框,在其后的图像序列计算估计的包围框和目标分割mask。
5.2 网络架构
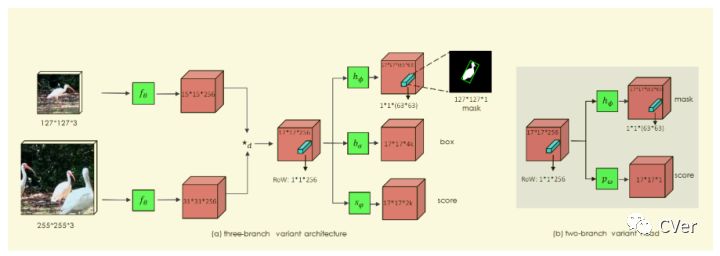
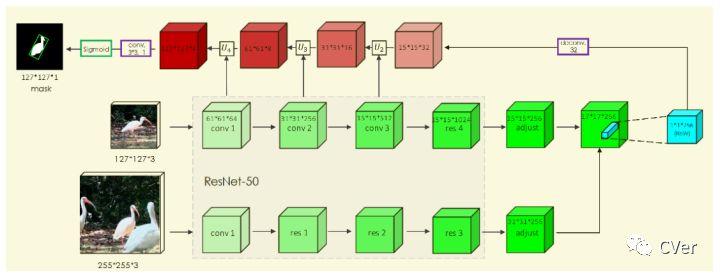
如图 14所示siammask网络架构在 Siamese Net based tracker 的基础上,进一步引入 Mask branch,得到分割结果和跟踪目标信息。这一步,其实相当于一定程度上解决了目标尺度变化的问题。
127x127x3是模板patch,来自第0帧。255x255x3是搜索区域,来自第n帧的一个局部区域。 表示卷积提取特征,两个分支共享同一个backbone,分别得到15*15*256和31*31*256的特征图,再经过 (depth-wise卷积)得到17*17*256特征图。
Mask分支是在Siamese Net新增,利用一个vector来编码一个RoW的mask。这使得每个prediction位置具有非常高的输出维度(63*63),论文通过depthwise的卷积后级联1x1卷积来升维来实现高效运行。
图 14所示的mask预测类似于encode-decode模型,在卷积过程不断损失特征,预测的Mask分支的精度并不太高。论文提出利用SharpMask语义分割模型,Refine Module用来提升分割的精度。
Siammask在视频跟踪领域(VOT),VOT2016和VOT2018数据集上的性能,我们的方法已经到达到SOTA的结果,同时保持了56fps的超实时的性能表现。Siammask在视频目标分割领域(VOS), DAVIS2017和Youtube-VOS数据集精度表现尚可,但是实时性提高1-2个数量级,56fps的处理速度可以满足移动终端的需求。
5.3 优缺点分析
1、Siammask的多任务学习方法,同时在VOT和VOS取得精度和实时性的trade off,学术界的研究比较容易落地工业级。
2、Siammask的mask预测分支采用SharpMask语义分割模型,精度带提高,替代这部分的模型可以进一步提高mask预测精度。
3、目前tracking没有专门处理消失问题(object traker如果从当前画面离开或完全遮挡),特别的,siammask挺容易受到具有语义的distractor影响。当遮挡时,它预测的mask是两个物体的mask。VOS领域处理遮挡和消失也比较困难。
以上仅为个人阅读论文后的理解、总结和思考。观点难免偏差,望读者以怀疑批判态度阅读,欢迎交流指正。
文末附CVer - 图像分割交流群入群方式
参考文献
[1] ai.googleblog.com/2018/
[2] supervise.ly
[3] Anna Khoreva,Federico Perazzi1,Rodrigo Benenson. Learning Video Object Segmentation from Static Images. arXiv preprint arXiv: 1612.02646, 2016.
[4] Anna Khoreva · Rodrigo Benenson · Eddy Ilg.Lucid Data Dreaming for Video Object Segmentation. arXiv preprint arXiv: 1703.09554, 2017.
[5] Paul Voigtlaender, Yuning Chai, Florian Schroff, .FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation. In Proc. of the IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2019.
[6] Xingjian Shi, Zhourong Chen, Hao Wang.Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv preprint arXiv: 1506.04214, 2015.
[7] Carles Ventura, Miriam Bellver, Andreu Girbau.RVOS: End-to-End Recurrent Network for Video Object Segmentation. In Proc. of the IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2019.
[8] Qiang Wang, Li Zhang, Luca Bertinetto.Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proc. of the IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2019.
CVer图像分割交流群
扫码添加CVer助手,可申请加入CVer-图像分割交流群。一定要备注:图像分割+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡)

▲长按加群
这么硬的综述分享,麻烦给我一个在看

▲长按关注我们
麻烦给我一个在看!

