TensorFlow全新的数据读取方式:Dataset API入门教程
作者:何之源
首发于知乎专栏:AI Insight
量子位 已获授权编辑发布
转载请联系原作者
Dataset API是TensorFlow 1.3版本中引入的一个新的模块,主要服务于数据读取,构建输入数据的pipeline。
此前,在TensorFlow中读取数据一般有两种方法:
使用placeholder读内存中的数据
使用queue读硬盘中的数据(关于这种方式,可以参考我之前的一篇文章:十图详解tensorflow数据读取机制)
文章地址:
https://zhuanlan.zhihu.com/p/27238630
像Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂。此外,如果想要用到TensorFlow新出的Eager模式,就必须要使用Dataset API来读取数据。
本文就来为大家详细地介绍一下Dataset API的使用方法(包括在非Eager模式和Eager模式下两种情况)。
Dataset API的导入
在TensorFlow 1.3中,Dataset API是放在contrib包中的:
而在TensorFlow 1.4中,Dataset API已经从contrib包中移除,变成了核心API的一员:


基本概念:Dataset与Iterator
让我们从基础的类来了解Dataset API。参考Google官方给出的Dataset API中的类图:
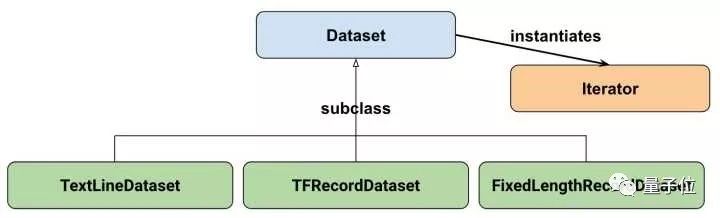
在初学时,我们只需要关注两个最重要的基础类:Dataset和Iterator。
Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以是向量,也可以是字符串、图片,甚至是tuple或者dict。
先以最简单的,Dataset的每一个元素是一个数字为例:

这样,我们就创建了一个dataset,这个dataset中含有5个元素,分别是1.0, 2.0, 3.0, 4.0, 5.0。
如何将这个dataset中的元素取出呢?方法是从Dataset中示例化一个Iterator,然后对Iterator进行迭代。
在非Eager模式下,读取上述dataset中元素的方法为:

对应的输出结果应该就是从1.0到5.0。语句iterator = dataset.make_one_shot_iterator()从dataset中实例化了一个Iterator,这个Iterator是一个“one shot iterator”,即只能从头到尾读取一次。one_element = iterator.get_next()表示从iterator里取出一个元素。
由于这是非Eager模式,所以one_element只是一个Tensor,并不是一个实际的值。调用sess.run(one_element)后,才能真正地取出一个值。
如果一个dataset中元素被读取完了,再尝试sess.run(one_element)的话,就会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据的行为是一致的。
在实际程序中,可以在外界捕捉这个异常以判断数据是否读取完,请参考下面的代码:

在Eager模式中,创建Iterator的方式有所不同。是通过tfe.Iterator(dataset)的形式直接创建Iterator并迭代。迭代时可以直接取出值,不需要使用sess.run():

从内存中创建更复杂的Dataset
之前我们用tf.data.Dataset.from_tensor_slices创建了一个最简单的Dataset:
其实,tf.data.Dataset.from_tensor_slices的功能不止如此,它的真正作用是切分传入Tensor的第一个维度,生成相应的dataset。

例如:
传入的数值是一个矩阵,它的形状为(5, 2),tf.data.Dataset.from_tensor_slices就会切分它形状上的第一个维度,最后生成的dataset中一个含有5个元素,每个元素的形状是(2, ),即每个元素是矩阵的一行。

在实际使用中,我们可能还希望Dataset中的每个元素具有更复杂的形式,如每个元素是一个Python中的元组,或是Python中的词典。
例如,在图像识别问题中,一个元素可以是{“image”: image_tensor, “label”: label_tensor}的形式,这样处理起来更方便。
tf.data.Dataset.from_tensor_slices同样支持创建这种dataset,例如我们可以让每一个元素是一个词典:

这时函数会分别切分”a”中的数值以及”b”中的数值,最终dataset中的一个元素就是类似于{“a”: 1.0, “b”: [0.9, 0.1]}的形式。
利用tf.data.Dataset.from_tensor_slices创建每个元素是一个tuple的dataset也是可以的:

对Dataset中的元素做变换:Transformation
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。
通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
常用的Transformation有:
map
batch
shuffle
repeat
下面就分别进行介绍。
(1)map
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值加1:

(2)batch
batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为32的batch:
(3)shuffle

shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小:

(4)repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:
如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常:


例子:读入磁盘图片与对应label
讲到这里,我们可以来考虑一个简单,但同时也非常常用的例子:读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本。在训练时重复10个epoch。
对应的程序为(从官方示例程序修改而来):

在这个过程中,dataset经历三次转变:
运行dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))后,dataset的一个元素是(filename, label)。filename是图片的文件名,label是图片对应的标签。
之后通过map,将filename对应的图片读入,并缩放为28x28的大小。此时dataset中的一个元素是(image_resized, label)
最后,dataset.shuffle(buffersize=1000).batch(32).repeat(10)的功能是:在每个epoch内将图片打乱组成大小为32的batch,并重复10次。
最终,dataset中的一个元素是(image_resized_batch, label_batch),image_resized_batch的形状为(32, 28, 28, 3),而label_batch的形状为(32, ),接下来我们就可以用这两个Tensor来建立模型了。
Dataset的其它创建方法….
除了tf.data.Dataset.from_tensor_slices外,目前Dataset API还提供了另外三种创建Dataset的方式:
tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
它们的详细使用方法可以参阅文档:Module: tf.data
文档地址:
https://www.tensorflow.org/api_docs/python/tf/data
更多类型的Iterator….
在非Eager模式下,最简单的创建Iterator的方法就是通过dataset.make_one_shot_iterator()来创建一个one shot iterator。除了这种one shot iterator外,还有三个更复杂的Iterator,即:
initializable iterator
reinitializable iterator
feedable iterator
initializable iterator必须要在使用前通过sess.run()来初始化。使用initializable iterator,可以将placeholder代入Iterator中,这可以方便我们通过参数快速定义新的Iterator。一个简单的initializable iterator使用示例:

此时的limit相当于一个“参数”,它规定了Dataset中数的“上限”。
initializable iterator还有一个功能:读入较大的数组。
在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中。
当array很大时,会导致计算图变得很大,给传输、保存带来不便。
这时,我们可以用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样就可以避免把大数组保存在图里,示例代码为(来自官方例程):

reinitializable iterator和feedable iterator相比initializable iterator更复杂,也更加少用,如果想要了解它们的功能,可以参阅官方介绍,这里就不再赘述了。
总结
本文主要介绍了Dataset API的基本架构:Dataset类和Iterator类,以及它们的基础使用方法。
在非Eager模式下,Dataset中读出的一个元素一般对应一个batch的Tensor,我们可以使用这个Tensor在计算图中构建模型。
在Eager模式下,Dataset建立Iterator的方式有所不同,此时通过读出的数据就是含有值的Tensor,方便调试。
作为兼容两种模式的Dataset API,在今后应该会成为TensorFlow读取数据的主流方式。关于Dataset API的进一步介绍,可以参阅下面的资料:
Importing Data 官方Guide地址:
https://www.tensorflow.org/programmers_guide/datasets
Module: tf.data API文档地址:
https://www.tensorflow.org/api_docs/python/tf/data
如何联合使用Dataset和Estimator:
https://developers.googleblog.com/2017/09/introducing-tensorflow-datasets.html
点击左下角“阅读原文”,可解锁更多作者的文章
还可以直接参与讨论~
量子位特约稿件,转载请联系原作者。
— 完 —
加入社群
量子位AI社群11群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




