研究员大战「硬演 AI」的故事。
AI 整的活,永远出乎人类的预料。最近,一个网络小说阅读 APP 因为有 bug 登上了热搜,b 站上也出现了不少搞笑视频,一些还有百万播放量。
![]()
引发人们广泛讨论的「番茄小说」是抖音旗下的阅读 APP,和其他很多同类应用一样带有听书功能,AI 算法生成的语音可以让你直接去听任何文字版小说,同时去做别的事。
番茄小说的不同之处在于——相对大多数 APP,它的语音合成 AI 「更聪明一点」:能够把文字读出不同音色和语气,如果文字是「哈哈哈……」,AI 不会平淡地念出来,而是真的会笑起来;当读到两个人对话的时候,它还能自动把声音分成两个不同的语气,从而区别出不同的角色。
然而在某些小说里,如果作者写的文字给的 S 太多,AI 会进入死循环发出怪声,或者文字中带有几段英文,甚至希腊字母,那么 AI 就会读出完全的中式英语。
这就让人有点绷不住了,毕竟在网文世界里,人们往往很在意这种特殊用法的描写。
「番茄小说 bug 的热搜确实出乎我们预料,在内部大家也讨论了很久,」火山语音(字节跳动 AI Lab 智能语音团队)负责人马泽君说道。「最近一段时间,人们对语音合成技术的进步感到兴奋,但万万没想到是从这个角度火出圈的。」
马泽君表示,修复 bug 的技术早已研发完成。问题出现后,经过和业务方的沟通,快速上线了新的模型,bug 就被修复了。旧版本的存量音频正被逐渐替换,网文爱好者们向鬼畜区投稿的快乐并没有持续太久。
其实,在字节跳动内部,马泽君领导的团队与番茄小说的合作从 2019 年就开始了。去年,火山语音已经对语音合成模型进行了大版本迭代,从早期的自回归结构演变成引入外部时长对齐机制的非自回归结构。相比原先的模型,新模型在消除对齐错误以及累积误差等方面有了很大改进,从而解决了发声不清晰、超长句停不下来的问题。
这些工作说来容易,但对于研究人员来说,要想构建一个完美的语音合成 AI 需要克服很多挑战。
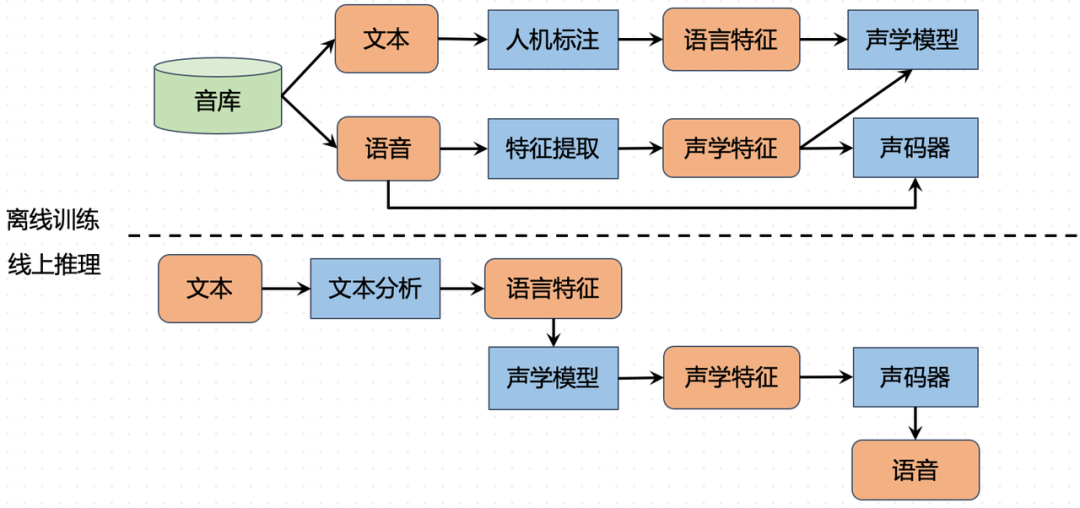
在人工智能领域里,语音技术是计算机视觉(CV)和自然语言理解(NLP)之外的另一个重要领域,最早的研究可以追溯到 1952 年。一个典型的语音合成系统(Text-to-Speech,TTS)通常分成三个标准技术模块:文本分析前端,中间的声学模型,和最后的声码器(vocoder)。
![]()
为了让机器发出的声音接近真人,首先需要保证输出内容不读错,这就需要文本分析模型来进行解析。为了能读出轻重缓急,声学模型需要在文本分析得出的语言学特征基础上对发音的语速、音高和停顿进行预测,再以 Mel 谱特征输出。最后,声码器负责将 Mel 谱转化成为波形输出,它需要保证高质量的音质,避免出现金属音等情况。
在番茄小说中,文本分析前端采用了 NLP 领域应用广泛的 Transformer 架构模型 BERT,通过神经网络加规则混合的正则化模型(TN)和多任务前端模型,结合长期的人工规则修正,不断提升前端的句级别精度,并通过蒸馏、量化等技术降低了算力需求。声学模型采用了以 LConv 为基础的 parallel Tacotron 结构,声码器使用了以 GAN 为基础的全神经网络架构。
真人朗读之所以听起来自然,是因为人类对上下文内容的理解。为了让合成语音更加好听,在常规 TTS 流程之上,火山语音团队还加入了更多功能模块,实现了角色归属、情感控制两个模块。在角色归属中同样采用了 bert 结构,进行对话判定和指代消歧两个任务的建模,另外也采用类似的结构进行情感预测。
「小说文字中可能会出现多人对话,一个说话人又可能会存在多种情感,我们把音色和情感进行了解耦,可以更好地控制合成语音的表现力,进而就可以实现不同的音色和不同情感的灵活组合,这也是一项较大的突破。」马泽君说道。
AI 多播是另一个有趣的尝试:算法模型先通过上下文理解,得出每句话是旁白还是对话、由哪个角色说的、以怎样的情感表达等相关信息, 再用对应人设和情感的模型进行合成,最终完成一部有声书的演绎。
语音合成的 AI 虽然有些地方读法不对,但大多数时候都给人带来了很好的体验。在演示 bug 的视频下也有网友认为,番茄小说的文本朗读是同类 APP 里听起来最舒服的。
![]()
火山语音除了为番茄小说提供了 AI 朗读技术外,还支持了语音搜索的能力,后者可以帮助用户更快捷地找到自己感兴趣的小说。
「比如你可以对手机说:找《风起陇西》对应的原著小说,我们能让用户听得更爽,找得更快,」马泽君表示。
番茄小说是抖音在 2019 年初推出的免费阅读产品,如今已成为目前国内在线阅读 APP 领域里热度最高的一个。AI 朗读技术在其中起到了不小作用。
火山语音正计划把这些能力迁移到更多语言中,借助跨语言合成技术,不仅能用准确的音色读出英文,还覆盖了西班牙语、印尼语等,同时可以保留原本的小说风格。这大大丰富了旗下的国际单播音色矩阵,为不同国家的用户提供了更多的选择。
除了情感合成和多角色朗读这两个最大特点,火山语音目前正在探索的方向是在 AI 文本朗读的过程中加入背景音乐和音效。「我们还在探索多角度的声源定位,让你在戴上耳机的时候,空间音频效果可以演绎出脚步声的移动,获得身临其境的体验,」马泽君说道。
除了能让 AI 念小说,火山语音的研究还覆盖语音的多个方面,今年的国际语音技术顶会 ICASSP 2022 上,字节跳动有关音乐翻唱检索的研究 Bytecover2 被大会接收,其能在海量曲库中准确搜索出一首曲目的不同翻唱版本。
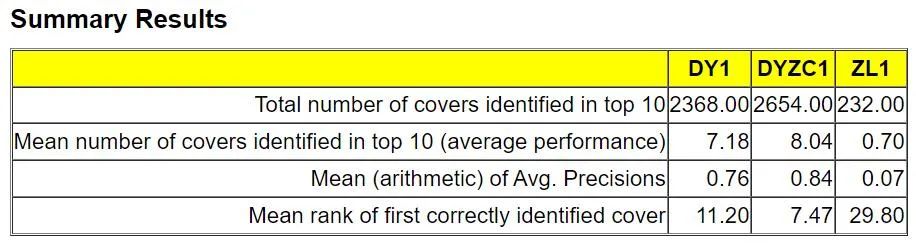
在上一代的 Bytecover 研究中,火山语音曾创造性地将 ResNet-IBN 模型和多任务学习的思路应用到了翻唱特征识别任务中,显著提高了翻唱特征的鲁棒性和可区分性。Bytecover 在国际音乐信息检索竞赛 MIREX 上取得了历史最好成绩,准确率比第二名高了 8%,大幅刷新了翻唱识别赛道历年最好记录,mAP 指标达到 84%,是同年参加该竞赛的其他方案性能的 14 倍。
![]()
而在 Bytecover2 上,作者通过使用主成分分析(PCA)对全连接层(FC)进行初始化,构建PCA-FC模块对特征进行降维,减少了计算开销,把检索速度一下提升了八倍。更重要的是,这项技术目前已经在字节系大量产品中落地,在音乐分发、曲库整理、智能推荐等任务中发挥了重要作用。
AI 研究最近的趋势是「大模型」。在计算机视觉和自然语言处理上,大规模预训练模型已经成为重要的研究方向,火山语音也在语音领域进行了探索。其提出基于 Swin transformer 音乐自监督预训练方法 S3T 可以有效挖掘音乐的时域和频率信息,其在多个下游任务取得了业界领先的效果。
例如
S3T 在行业通用的音乐分类数据集上相比之前的自监督方法准确率提升了 12.5%,还超过了特定任务上的最优监督学习方法。
「字节跳动面向全球市场,需要面对大量数据和广泛的需求,语音大规模预训练模型是我们研究的重要方向,」马泽君表示。「在最新的工作中,研究人员分别从算法和工程优化了数百万小时语音数据的预训练,实现了百亿参数规模的大模型。」
未来,火山语音还希望去做千万小时数据规模,完成千亿参数的大模型,实现支持 100 种语言的目标。
为番茄小说打造 AI 语音技术的火山语音团队于 2017 年 10 月成立,目前已有百名成员,在北京、上海、深圳,及海外的新加坡和波兰都设有研发中心。
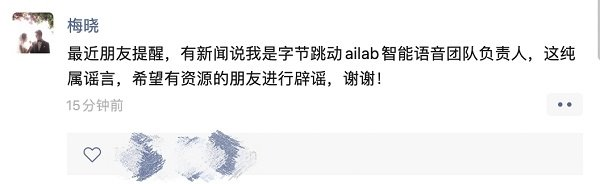
近期有关火山语音的另一个消息是有媒体报道负责人离职,马泽君表示,报道中提到的梅晓系原 AI Lab 语言学专家,主要负责语言学在语音合成技术上的应用。并非 AI Lab 的智能语音部门负责人。
![]()
火山语音长期以来面向字节跳动内部各业务线以及火山引擎 ToB 行业与创新场景,提供了全球领先的语音 AI 技术能力以及卓越的全栈语音产品解决方案。在音频理解、创作、检索和生成以及智能对话等领域持续进行场景创新以及行业赋能,高效解决了语音通信、人机语音交互、音视频内容理解与创作等领域诸多问题。
「我们不仅负责前沿算法的研究,也肩负着工程化的任务,面向公司的整体业务」马泽君说道。「我们认为人工智能不仅可以在实验室里实现技术突破,或者是展示酷炫的效果,更希望它们可以走向实际应用场景。只有通过与用户不断互动,迭代提升,我们才能实现这样的目标。」
不仅是番茄小说,火山语音技术的应用已经覆盖到了抖音、剪映等字节跳动核心内容产品和工具上。智能语音提供的多语言的视频字幕能力可以使用 13 个语言,面向 30 多个国家提供服务。除了向娱乐产品提供服务以外,其语音技术也向火山引擎及飞书提供能力。
儿童节之际,火山语音旗下的 AI 音乐人 ByteMuse 在抖音上新了《摇摇车》、《喵喵》、《sunny kitty》三首 AI 创作的童趣配乐,大小朋友都能更有仪式感地记录、分享生活,欢迎大家在抖音上体验。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com