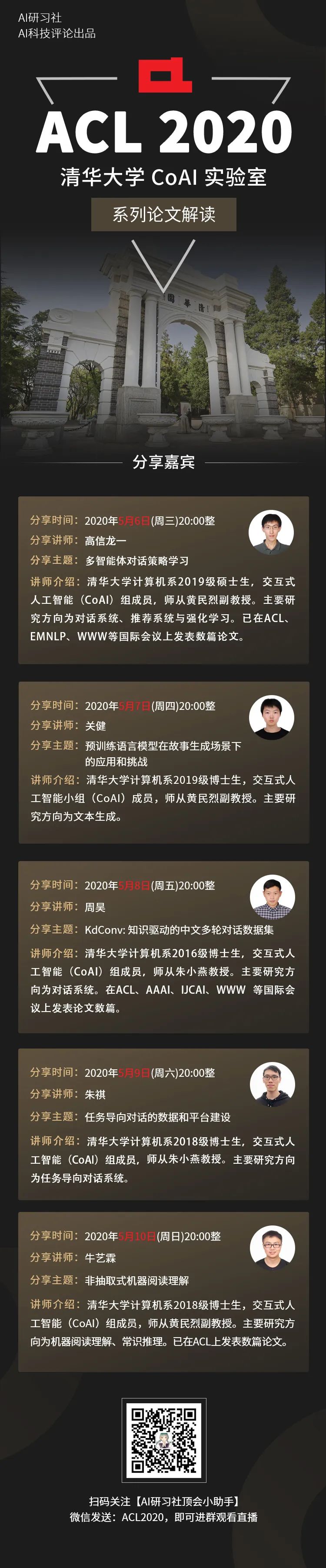
连续五天,ACL 2020 清华 CoAI 系列解读!

疫情之后,“旧的世界”将不复存在
线上直播将成为学术交流的重要形式




主题五:非抽取式机器阅读理解



登录查看更多
相关内容
Arxiv
8+阅读 · 2019年1月2日



相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2019年1月2日