AAAI20好文推荐 | 视觉对话,VDST可以提出更好的问题?!
点击中国图象图形学报→主页右上角菜单栏→设为星标


图片来源网络
已有人机对话研究大多基于语言信息,而人类对话多发生在特定物理世界场景中,人们会基于场景中的视觉信息展开对话。
2017年由蒙特利尔大学、DeepMind和Twitter等单位的研究人员联合提出的视觉对话任务GuessWhat?!是一个模拟人类在视觉场景中进行对象猜测的游戏,其中猜测者如何提出好的问题是影响猜测准确率的难点。
图图今天推荐AAAI2020 Oral Paper中的一篇好文,成果来自北京邮电大学人工智能学院王小捷教授和庞伟博士,论文提出了一种新的视觉对话状态定义以及状态追踪机制,基于此机制的提问模型在标准评测数据上比现有最好模型提升了6个百分点。

标题:Visual Dialogue State Tracking for Question Generation
作者: Wei Pang, Xiaojie Wang
引用格式: Wei Pang, Xiaojie Wang. Visual Dialogue State Tracking for Question Generation. In Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020
全文链接:https://arxiv.org/abs/1911.07928
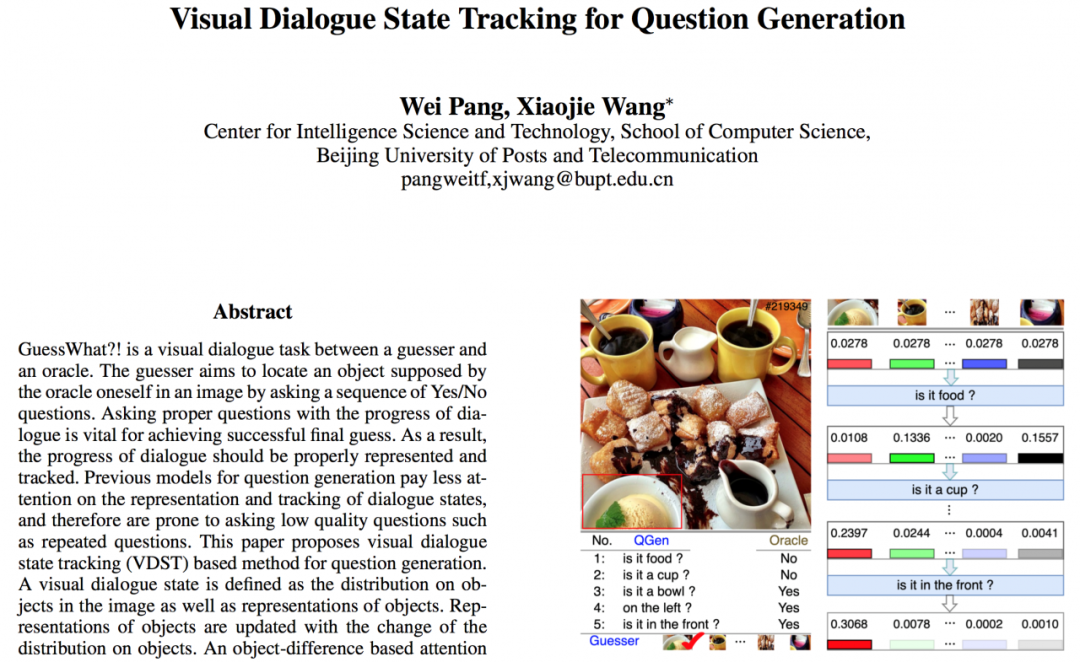


基于给定的视觉信息和任务目标,以对话的形式达成目标,比如从一张有丰富场景的图片中找到一个具体对象,这就是论文研究的GuessWhat?!任务。
它涉及到对话的两个参与方(Agent):问题生成(Questioner, 又称为QGen)和问题回复(Oracle)。
游戏开始前,Oracle预先设定图片中的一个对象(object)作为任务目标,QGen通过多轮的提问,最后结合Oracle的回复来对图片中的目标进行定位,如果定位到Oracle设定的目标,就是一个成功的对话。论文关注问题生成(QGen),提出了跨模态的对话跟踪机制。
将图像看做含有若干个对象的视觉信息,对话状态定义为一个二元组:<对象上的概率分布、对象的表征>。
随着对话的进行,QGen结合已有的对话历史,在对象集合上会产生一个概率分布,哪些对象可能是目标,对应的概率会大一些,哪些对象已被排除,对应的概率减小;于是,对象的表征随着概率分布的变化,也产生变化,疑似对象的表征要展现出来更多的内容,以便产生更有针对性的、更丰富的关于自身的问题。
在QGen和Oracle的每一轮对话后,QGen的对话状态都会更新。首先根据当前QGen的问题和Oracle的回复更新对象上的概率分布,其次根据已更新的概率分布,更新对象的表征,如图1右侧所示的对话状态跟踪过程。

图1 左侧是QGen和Oracle的一个5轮对话;右侧是QGen的对话状态跟踪,彩色条带表示对象的表征,它之上的数字表示概率分布
图2是论文提出的对话状态跟踪(Visual Dialogue State Tracking, VDST)框架。它包括4个部分:
1)跨模态匹配模块(CMM)比较当前的对话,由问题和回复组成,和图像中的每一个对象比较,产生一个对象上的概率分布;
2)对象更新模块(UoOR)根据CMM产生的概率分布,更新对象的表征;
3)对象自差分模块(OsDA)在对象之间进行比较,找到有差异的视觉信息,作为产生下一个问题的因素;
4)解码器(QDer)是一个单层的LSTM模型,它依据OsDA的输出,生成一个新的问题。
QGen把这个新问题向Oracle提问,得到Oracle的回复后,重复执行上述的四个部分,构成一问一答的交互闭环。
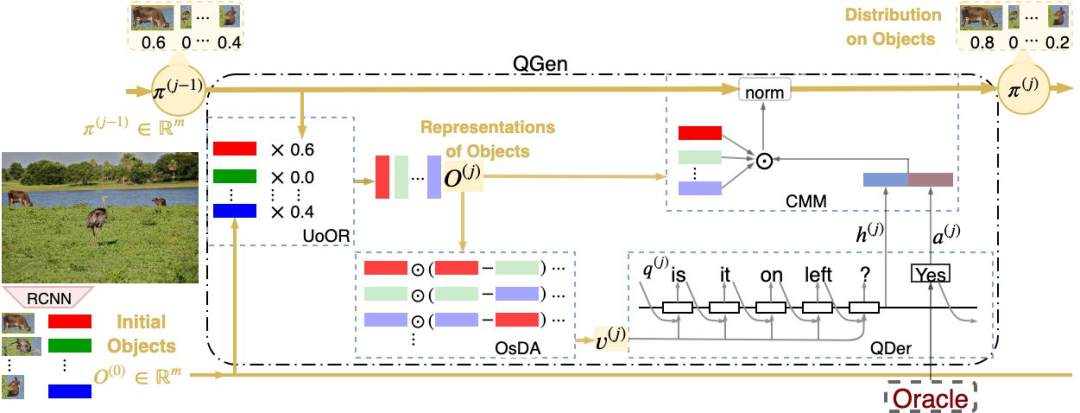
图2 论文提出的对话状态跟踪模型(VDST model)
在GuessWhat?!数据集上沿用主流的评价方法:任务成功率。如果QGen定位到Oracle设定的目标,对话是成功的,否则是失败的对话。实验分别在训练集和测试集上进行,训练集(NewObject)表示图片参与了模型的训练,图片中的目标对象是重新随机选择的;测试集(NewGame)上表示图片和对象都是新的,没有参与到模型训练。表1对比了3种采样方法下不同QGen模型的实验结果。
表1 QGen模型上的任务成功率对比

从表1中可以看出,在有监督学习和强化学习上,VDST模型都优于对比模型。在测试集上,固定5轮对话中,VDST模型的准确率达到64.36%,8轮对话达到67.73%,相比RIG模型提高了6个百分点。
图3中的蓝色曲线显示了VDST模型在强化学习时的学习曲线,红色曲线是我们在GuessWhat?!任务上最新模型的结果,任务成功率达到83.3%,已经接近人类水平的84.4%。
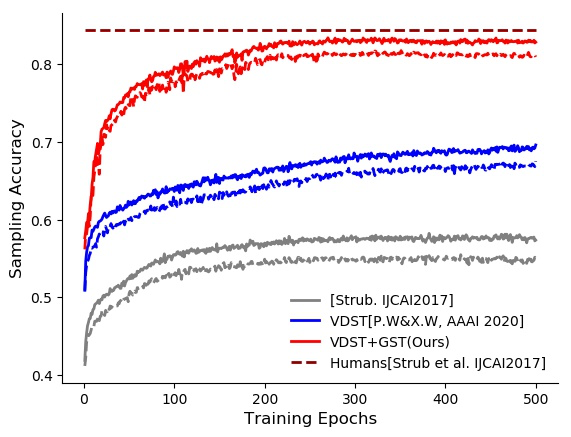
图3 强化学习在GuessWhat?!训练集和验证集上的学习曲线
在视觉对话系统中引入跨模态对话状态跟踪机制,建模生成问题的过程,可以显著提高GuessWhat?!任务的猜测成功率。
作者简介

庞伟,北京邮电大学人工智能学院博士研究生,主要研究视觉和语言问题,多模态对话系统。
Email: pangweitf@bupt.edu.cn

王小捷,北京邮电大学人工智能学院教授、博士生导师,主要研究方向为认知计算,自然语言理解。
E-mail: xjwang@bupt.edu.cn
前沿进展 | 多媒体信号处理的数学理论
中国卫星遥感回首与展望
单目深度估计方法:现状与前瞻
目标跟踪40年,什么才是未来?
算法集锦 | 深度学习如何辅助医疗诊断?
10篇CV综述速览计算机视觉新进展
算法集锦|深度学习在遥感图像处理中的六大应用
专家推荐|高维数据表示:由稀疏先验到深度模型
专家报告 | AI与影像“术”——医学影像在新冠肺炎中的应用
专家推荐|真假难辨还是虚幻迷离,参与介质图形绘制让人惊叹!
学者推荐 | 深度学习与高光谱图像分类【内含PPT 福利】
专家报告|深度学习+图像多模态融合
专家报告 | 类脑智能与类脑计算
Hinton,吴恩达,李飞飞 !大师深度学习课程集锦
羡慕别人中了顶会?做到这些你也可以!
如何阅读一篇文献?
共享 | SAR图像船舶切片数据集
《中国图象图形学报》2020年第2期目次
《中国图象图形学报》2020年第1期目次
《中国图象图形学报》2019年第12期目次
《中国图象图形学报》2019年第11期目次
本文系《中国图象图形学报》独家稿件
内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:韩小荷
指导:梧桐君
审校:夏薇薇
总编辑:肖 亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。
与你同在
前沿 | 观点 | 资讯 | 独家
电话:010-58887030/7035/7418
网站:www.cjig.cn






