粤港澳大湾区数字经济研究院(IDEA研究院)实习研究博士生
清华大学2021级客座学生、早稻田大学博士生(指导老师:杨余久、酒井哲也)
● VQA任务是什么
● 介绍之前的模型和方法
● 欢迎来到Transformer的时代
2019:尝试多模态表征
2020:拥抱多模态表征
2021:统一构架的探索
● 下游任务(VQA等)
● 更多其他有趣的论文
本Part 2主要介绍:
● 欢迎来到Transformer的时代
2019:尝试多模态表征
2020:拥抱多模态表征
欢迎来到Transformer的时代:2019至今
2018 年,BERT 腾空出世之后,我们见识到了 transformer 的强大。所以,最近的工作都是基于 transformer 的模型构造而来。从此之后,多模态模型的模型基本上都开始抛弃单一任务了。大家的研究方向也从单一任务,迈向了 pretrain+finetune,VQA 也从一个特定的任务变成了众多下游任务中的一个。
Ref:
https://mp.weixin.qq.com/s/gyGeFHV2jlgCQaGmWBKMVQ
https://zhuanlan.zhihu.com/p/427323610
尽管我做这个 survey 是在 2020 年,但是,对很多文章都有所借鉴,根据了一些后来者的叙述缝缝补补。
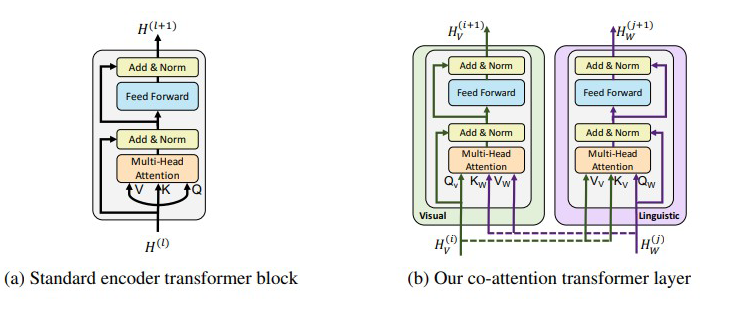
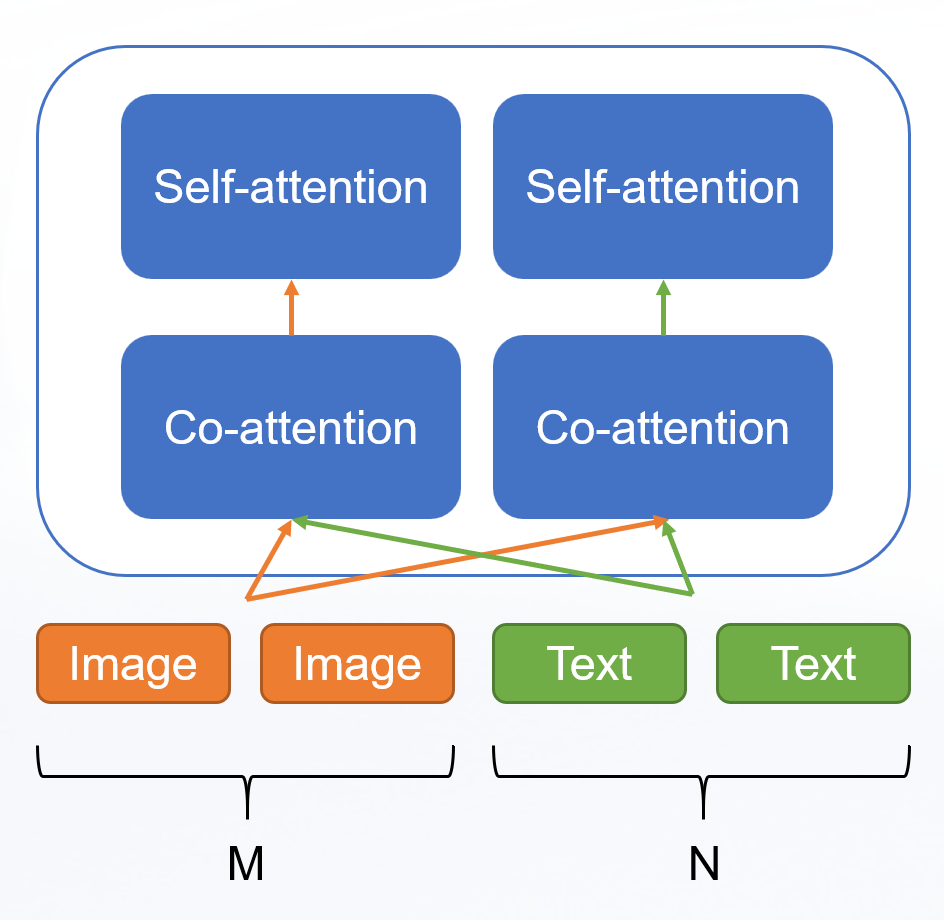
单流模型的定义:只使用 self-attention 来学习模态内和模态间的联系。
双流模型的定义:专注于学习模态之间的联系,比如 cross-attention,co-attention。基本上,transformer 时代到来之前,都是双流模型。
对于 Transformer-based 模型来说,单流模型和双流模型是有共通之处的。
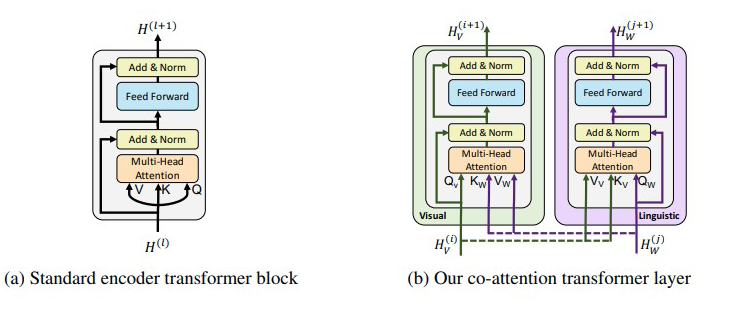
上图的(a)为基于 self-attention 的 block,(b)为基于通常的 attention 的组合而来的 co-attention 的 block。
对于 image 端的输入的 length 是 M 的话,对于 Text 端的输入的 length 是 N 的话。
那么对于单流模型来说,通常只需要用纯 self-attention 的 block,其计算复杂度为
。
对于双流模型来说,通常由两个 encoder 分别提取两个模态的信息,并且输入到一个特征融合模块中。两个 encoder 的计算复杂度分别为
和
,co-attention 的计算复杂度为
,其实合起来也就是
。
从这个角度来看,我们的单流和双流模型,也许本质上是一样的,只不过双流模型把单流模型中的一些操作解耦 了,使得我们的结果更加容易分析。
之前的工作都是在探索如何直接在视觉和语言之间建立联系,也就是用 attention 来直接计算。自从 transformer 起来了之后,不仅仅的整个多模态领域的构架发生了改变。也开始逐渐使用通用的多模态表征来做各种各样的下游任务了。而这下游任务也不只局限于 VQA 了。
说是全部改成了 transformer 的结构,但是实际上,仅仅是融合的部分以及文本的部分使用了 transformer 的架构,cv 端的特征依然来自于 fast rcnn。
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
https://readpaper.com/paper/2970608575
https://arxiv.org/abs/1908.02265
https://github.com/jiasenlu/vilbert_beta
Motivation / Contribution
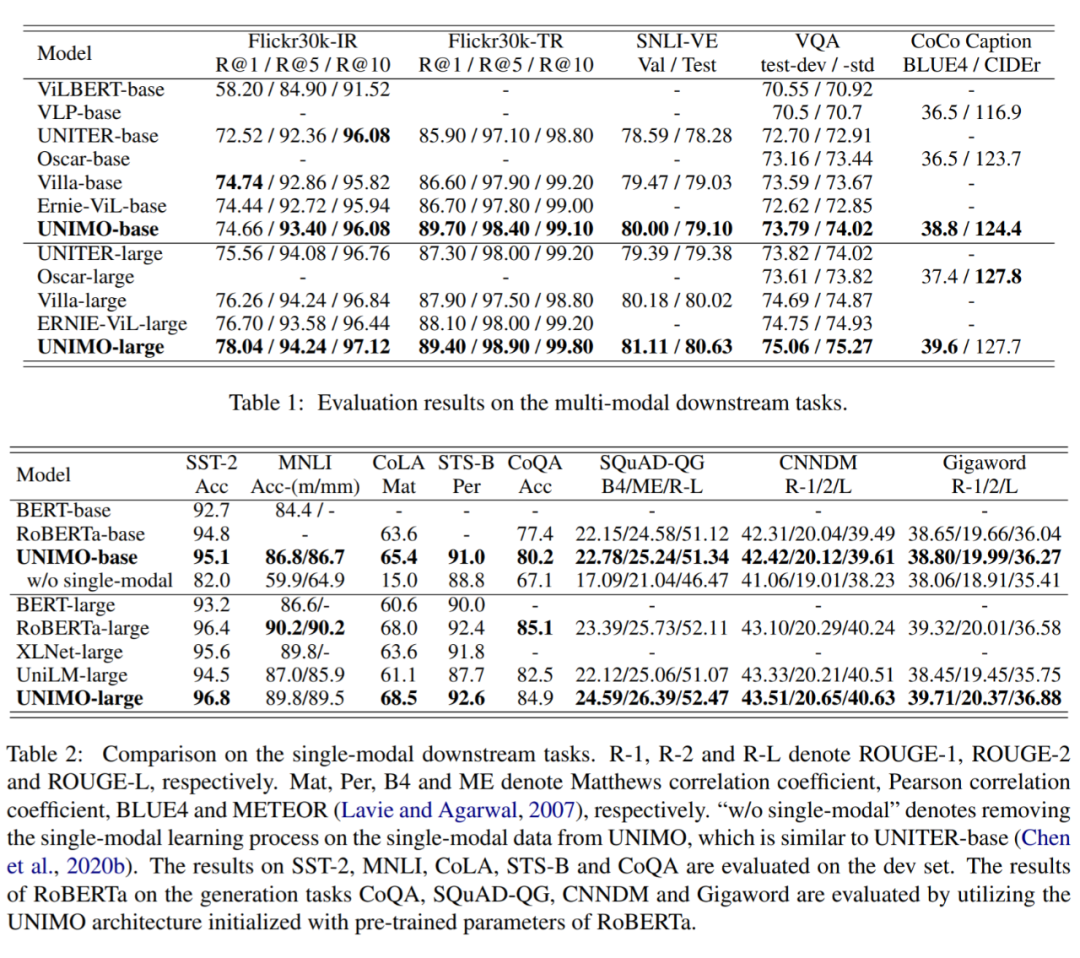
自然语言处理(NLP)领域在 2018 年提出的 BERT 模型(双向 Transformer 结构,利用了 self-attention 来增加上下文的相关性)逐渐成为了语言任务中首选的预训练模型。但在视觉与语言交叉的领域还没有出现一个通用的预训练模型,提出视觉与语言统一建模。该模型在 Conceptual Captions 数据集上进行预训练,再将其迁移应用到多个视觉-语言任务:视觉问答,视觉常识推理,指示表达(referring expressions)和基于字幕的图像检索。ViLBERT 应用到下游任务时仅需对基础架构进行少量增加。实验结果表明本文的 ViLBERT 在 4 个下游任务中显著优于面向特定任务的 sota。
(Jiasen Lu, 2019)提出 ViLBERT(Vision-and-Language BERT),该模型学习图像内容和自然语言的无任务偏好的联合表征。
首先,在 Conceptual Captions 数据集进行 Pre-train,然后再迁移到视觉问答,视觉常识推理,指示表达(referring expressions)和基于字幕的图像检索这四个视觉-语言任务。在下游任务中使用 ViLBERT 时,只需要对基础架构进行略微修改即可。
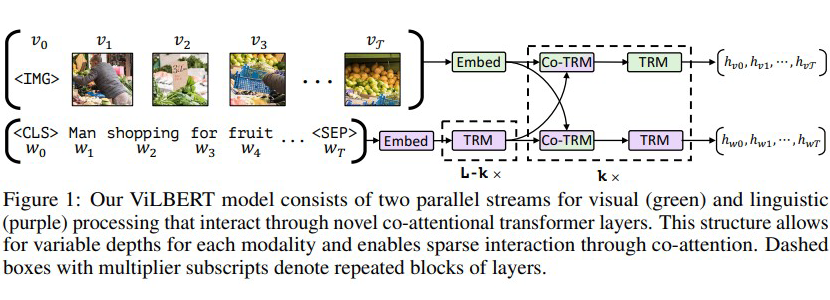
ViLBERT 修改 BERT 中 query 条件下的 key-value 注意力机制,将其发展成一个多模态共注意 transformer 模块。在多头注意力中交换的 key-value 对,该结构使得 vision-attended 语言特征能够融入入视觉表征(反之亦然)。
ViLBERT 学习的是静态图像及其对应描述文本的联合表征,分别对两种模态进行建模,然后通过一组 attention-based 的 interaction 将它们 merge 在一起。
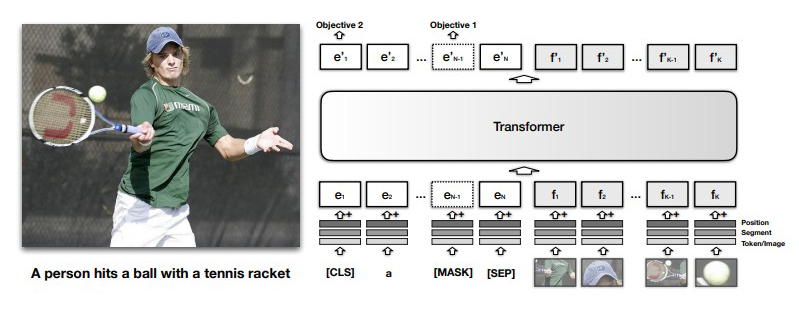
该模型由分别作用于图像块和文本段的 2 个平行 BERT 模型组成。每个流都是由一系列的 transformer blocks 和注意力 transformer 层组成。其 attention 层是用以两个模态之间特征融合。需要注意的是,流之间的信息交换是被限制于特定层的,所以,文本流在与视觉特征进行交流之前有更多的处理。这也符合我们的直觉,所选择的视觉特征已经相对高级,与句子中的单词相比,视觉特征需要有限的上下文聚合。
训练 ViLBERT 时采用了 2 个预训练的任务:
Masked Language Modeling(MLM):15%
Masked Object Classifation(MOC)
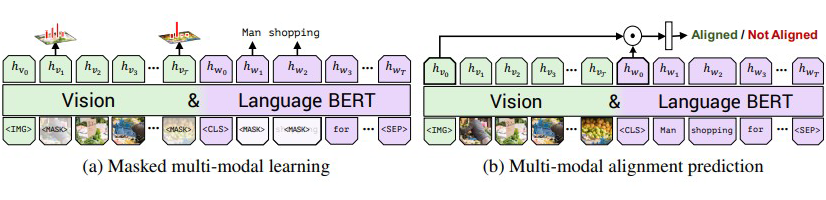
与标准 BERT 一样,对词和图像 rpn 输入大约 15% 进行 mask,通过余下的输入序列对 mask 掉的元素进行预测。对图像进行 mask 时,0.9 的概率是直接遮挡,另外 0.1 的概率保持不变。文本的 mask 与 bert 的一致。vilbert 并不直接预测被 mask 的图像区域特征值,而是预测对应区域在语义类别上的分布,使用 pretrain 的 object-detection 模型的输出作为 ground-truth,以最小化这两个分布的 KL 散度为目标。
Visual-linguistic Matching(VLM)
其目标是预测图像-文本对是否匹配对齐,即本文是否正确的描述了图像。以图像特征序列的起始 IMG token 和文本序列的起始 CLS token 的输出作为视觉和语言输入的整体表征。借用 vision-and-language 模型中另一种常见结构,将 IMG token 的输出和 CLS token 的输出进行 element-wise product 作为最终的总体表征。再利用一个线性层预测图像和文本是否匹配。
VisualBERT: A Simple and Performant Baseline for Vision and Language
https://readpaper.com/paper/2968124245
https://arxiv.org/abs/1908.03557
https://github.com/uclanlp/visualbert
Motivation / Contribution
文字和图片统一进行语义学习,提出单流的方法。提出了两种预训练任务。
(LH Li, 2019)提出的模型的结构和 Video BERT 类似,均将 text feature 和 visual feature 串联。不同的是,本文的 visual feature 使用的是 region feature,但是没有对其进行 mask。
其文字部分的输入为原始的 BERT 文字输入(词向量+位置编码+片段编码)加上 Token/Image 编码来表示其是图片或文字,而图片部分的输入则是采用通过 Faster-RCNN 提取的图片区域特征加上相应的位置编码,片段编码和 Token/Image 编码。
VisualBERT 遵循 BERT 一样的流程,先进行预训练然后在相应的任务上进行微调,其采用了两个预训练任务:第一个是和 BERT 一样的语言掩码,第二个则是句子-图像预测 (即判断输入的句子是否为相应图片的描述)。
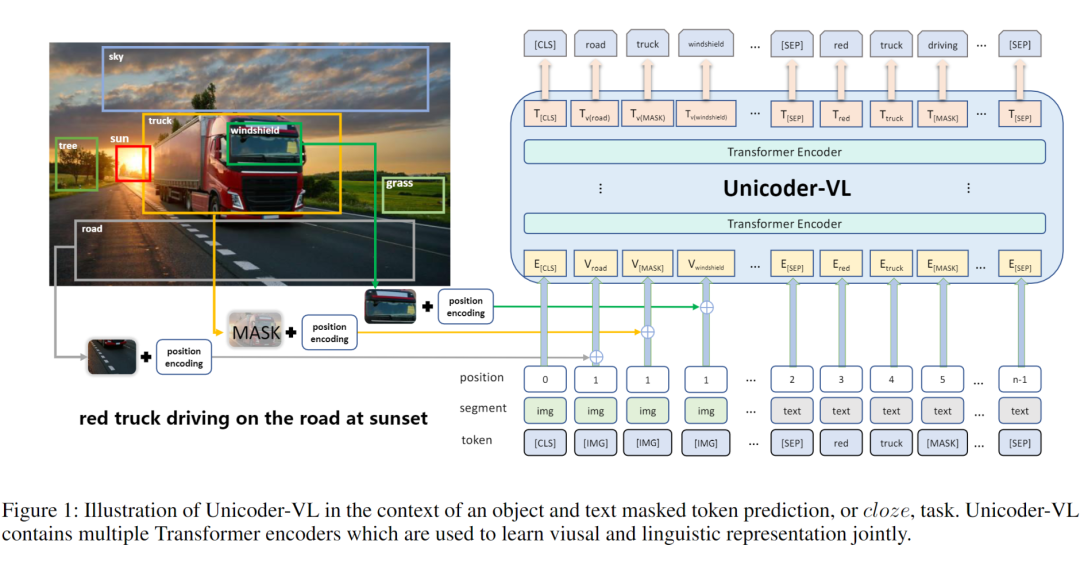
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
https://readpaper.com/paper/2998356391
https://arxiv.org/abs/1908.06066
https://github.com/microsoft/Unicoder
在图像捕获、场景图生成、视频分类和视频问答上 finetune。
如图所示,本文模型中以图像的特征匹配文本中的特定短语共同输入到编码器中进行嵌入,随后使用多层的 Transformer 进行跨模态的表征学习。其中,图像嵌入使用了 Fast-RCNN 进行特征提取,并使用 [IMG] 进行标记。
MaskedLanguage Modeling(MLM):将一部分的词语进行 mask,任务是根据上下文推断该单词。
Masked Object Classification(MOC):对图像的一部分内容进行 mask,任务是对图像进行分类,此处的分类使用的依然是目标检测技术,只是单纯的将目标检测中置信度最高的一项作为分类类别。
Visual-linguistic Matching(VLM):利用 [CLS] 的最终隐藏状态来预测语言句子是否与视觉内容语义匹配,并增加了一个 FC 层。
其中前两个任务视为了基于语言和视觉内容学习输入内容的上下文感知表示,而第三个任务是为了预测语言和视觉是否可以互相描述。
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
https://readpaper.com/paper/2970231061
https://arxiv.org/abs/1908.07490
Motivation / Contribution
本文要解决的问题:多模态深度学习中,缺少特征之间的联系,两个特征提取分支在提取特征过程中没有进行交互,导致视觉和语言信息并没有得到充分联系。
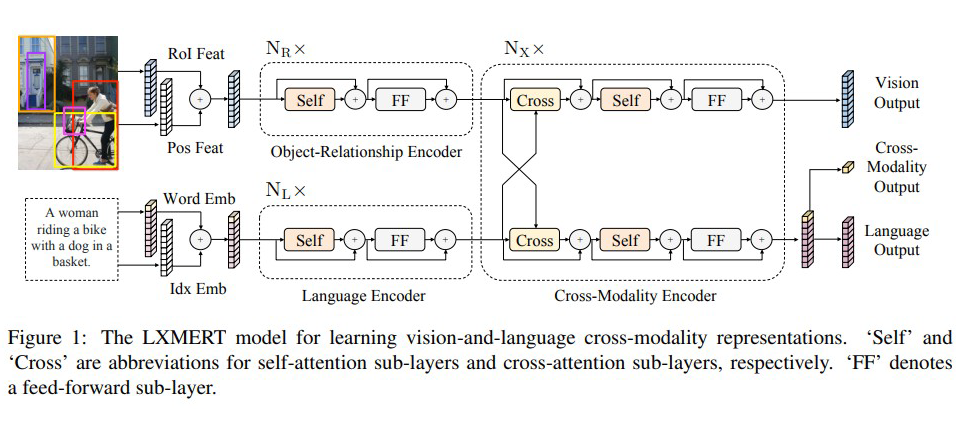
本文提出了一种跨模态模型,该模型有两个输入,分别为图片与文本,其中图片为对象序列,文本为单词序列,具有针对语言,视觉和跨模态的三个输出。模型使用双路的 Transformer 结构,使用三种 Encoder(对象关系编码器、语言编码器、跨模态编码器)通过五种预训练方式来赋予模型的跨模态能力。
(H Tan, 2019)提出了 LXMERT 框架来学习这些语言和视觉的联系,它含有三个编码器:一个对象关系编码器、一个语言编码器和一个跨模态编码器。
通过精心设计和组合这些自我注意和交叉注意层,我们的模型能够生成语言表示、图像表示和跨模式表示。接下来,将详细描述该模型的组件。
词级句子嵌入 一个句子首先被分成
,长度为 n,用的是 WordPiece tokenizer。接下来,通过嵌入子层将单词
及其索引 i(
在句子中的绝对位置)投影到向量上,然后添加到索引感知词嵌入。
对象级图像嵌入 从图像(上图边框表示)对象检测器检测 m 个对象
。每个对象
由其位置特征
(即,边界框坐标)及其 2048 维感兴趣区域(RoI)特征
表示。我们是通过增加 2 个全连接层的输出来学习位置感知嵌入
。
编码器
单模态编码器 在嵌入层之后,他们首先应用两个 transformer 编码器,即语言编码器和对象关系编码器,它们中的每一个都只专注于一个单一的模态(即语言或视觉)。在单模态编码器中(上图中的左侧虚线框),每层都包含一个自注意(“Self”)子层和一个前馈(“FF”)子层,其中前馈子层进一步由两个完全连接的子层组成.。我们分别在语言编码器和对象关系编码器中采用
层和
层,在每个子层之后添加一个残差连接和层归一化(在图 1 中用“+”符号表示)。
跨模态编码器 跨模态编码器中的每个跨模态层(上图中的右侧虚线框)均由两个自注意子层,一个双向交叉注意子层和两个前馈子层组成。在他们的编码器实现中,我们将这些跨模态层叠加
层(即,使用第 k 层的输出作为第
层的输入)。在第 k 层内部,首先应用了双向交叉注意子层,该子层包含两个单向交叉注意子层:一个从语言到视觉,一个从视觉到语言。
LXMERT 跨模态模型有三个输出,分别用于语言、视觉和交叉模态。语言和视觉输出特征序列由交叉模态编码器产生的;对于跨模态输出,他们附加了一个特殊的标记 [CLS](在上图的底部分支中表示为顶部黄色块)在句子词之前,并且该特殊标记在语言特征序列中的对应特征向量为用作交叉模式输出。
Language Task: Masked Cross-Modality LM
任务设置与 BERT 几乎相同:单词被随机掩蔽,概率为 0.15,模型被要求预测这些蒙面词。
LXMERT 具有跨模态模型体系结构,可以从视觉模态中预测掩蔽词,从而解决模糊性问题。
Vision Task: Masked Object Prediction
通过随机掩蔽物体(即用零遮掩 ROI 特征)概率为 0.15 来预先训练视觉的一面,并要求模型预测这些被掩盖对象的结构。
该任务分成两个子任务,第一个任务是 RoI Feature Regression ,使用 L2 loss 来预测被遮蔽 object 的 RoI Feature,这不需要语言信息的帮助,可以使模型学习到对象之间的关系。第二个子任务是 Detected-Label Classification ,结合了视觉信息和语义信息进行联合预测,所有图片的标签都由 Faster RCNN 给出。
为了学习一个强大的交叉模态表示,预先训练 LXMERT 模型与两个任务,明确需要语言和视觉模式。
Cross-Modality Matching 对于每个句子,概率为 0.5,用一个不匹配的句子替换它。然后,训练一个分类器来预测图像和句子是否相互匹配。这个任务有点像在 BERT 中进行“下一句预测”。
Image Question Answering(QA)为了扩大训练前的数据集训练前数据中大约 1/3 的句子是关于图像的问题。当图像和问题匹配时,要求模型预测这些图像相关问题的答案。
Github:
https://github.com/airsplay/lxmert
3.1.5 VL-BERT
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
https://readpaper.com/paper/2995460200
https://arxiv.org/abs/1908.08530
https://github.com/jackroos/VL-BERT
Motivation / Contribution
一般来说,之前的视觉-语言模型分别使用计算机视觉或自然语言处理领域中的预训练模型进行初始化,但如果目标任务数据量不足,模型容易过拟合从而损失性能。并且对于不同的视觉-语言任务,其网络架构一般是经过特殊设计的,由此很难通过视觉-语言联合预训练的过程帮助下游任务。
为了让 VL-BERT 模型利用更为通用的特征表示,作者在大规模图片描述生成数据集 Conceptual Captions 还有 BooksCorpus,English Wikipedia 两纯文本数据集(MLM)中进行 VL-BERT 的预训练,实验证明此预训练过程可以显著提高下游的视觉-语言任务的效果,包含视觉常识推理、视觉问答与引用表达式理解等。值得一提的是,在视觉常识推理排行榜中,VL-BERT 取得了当前单模型的最好效果。
先前的研究是分别对图像和语言用特定任务的预训练模型进行微调,然后再整合到一起。这样的话,会缺乏一定的“共识”(visual-linguistic)。任务的关键是聚合多模信息(multi-modal information)。为了更好地实现通用表示,作者(W Su, 2019)在大规模的概念标注数据集和纯文本语料库上对 VL-BERT 进行预训练。
(W Su, 2019)利用 transformer 处理以视觉与语言嵌入特征的输入。其中输入的每个元素是来自句子中的单词、或图像中的感兴趣区域(Region of Interests,简称 RoIs)。获取具有更为丰富的聚合与对齐视觉和语言线索的 representation。
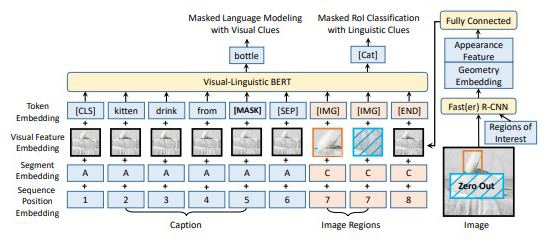
Token Embedding 和 BERT 是一样的。WordPiece embeddings(Wu et al., 2016)with a 30,000 vocabulary。对于图片,会分配一个 [IMG]。
Visual Feature Embedding 每一个输入元素都有一个对应的视觉特征嵌入,视觉特征嵌入是视觉外观特征(visual appearance feature)和视觉几何特征(visual geometry embedding)的 concatenation。
segment embedding 定义了三种类型的句段 A,B,C,以将来自不同来源的输入元素分开。A 表示来自于第一个输入句子中的单词,B 表示来自于第二个输入句子中的单词,C 表示来自于输入图像的 RoI。
position embedding 与 BERT 一样,将序列位置嵌入添加到每个输入元素中,以指示其在输入序列中的顺序。由于输入的视觉元素之间没有自然顺序,因此它们在输入序列中的任何排列都应获得相同的结果。因此,所有视觉元素的序列位置嵌入都相同。
Step1:图片和文本没法直接对齐,所以暴力输入整张图,直接将图像、文本、segment 和 position embeding 相加作为输入。
Step2:提取图像中的重要部分,增加无文本的图像输入。由于整张图片的粒度远大于文本 token,一次性输入整张图片显然不利于图像和文本信息的交互。所以使用了目标检测工具对图片进行分块,提取图像中感兴趣的核心部分 RoI(region-of-interest),加上 [IMG] 标识,输入到模型中。
利用视觉线索(visual clues)对masked语言建模
根据文本 + 图像信息预测文本 token,升级版的 MLM。唯一不同的是被 mask(15% 的概率)的 word 除了根据没被 mask 的文本来预测还可以根据视觉的信息来辅助。比如上图中的例子,被 mask 后的 word sequence 是 kitten drinking from [MASK],如果没有图片给我们的视觉信息是无法预测出被 mask 的词是 bottle。
根据文本+图像信息预测 RoIs 的类别,针对图像的“MLM”。图像中的每个 RoI 都会以 15% 的概率被随机 mask,预训练任务是根据其他线索预测被 mask 的 RoI 的类别标签。为了避免由于其他元素的视觉特征嵌入而导致任何视觉线索泄漏,在应用 Fast R-CNN 之前,将 mask RoI 中放置的像素置为 0。在预训练期间,对应于被 mask 的 RoI 的最终输出特征将被 feed 到具有 softmax 交叉熵损失的分类器中,以进行对象类别分类。(有个小问题,这里的 Fast R-CNN 做这个任务的时候,生成的标签感觉不算是 ground truth,只能作为辅助训练)
图像标题关联预测(Sentence-Image Relationship Prediction)
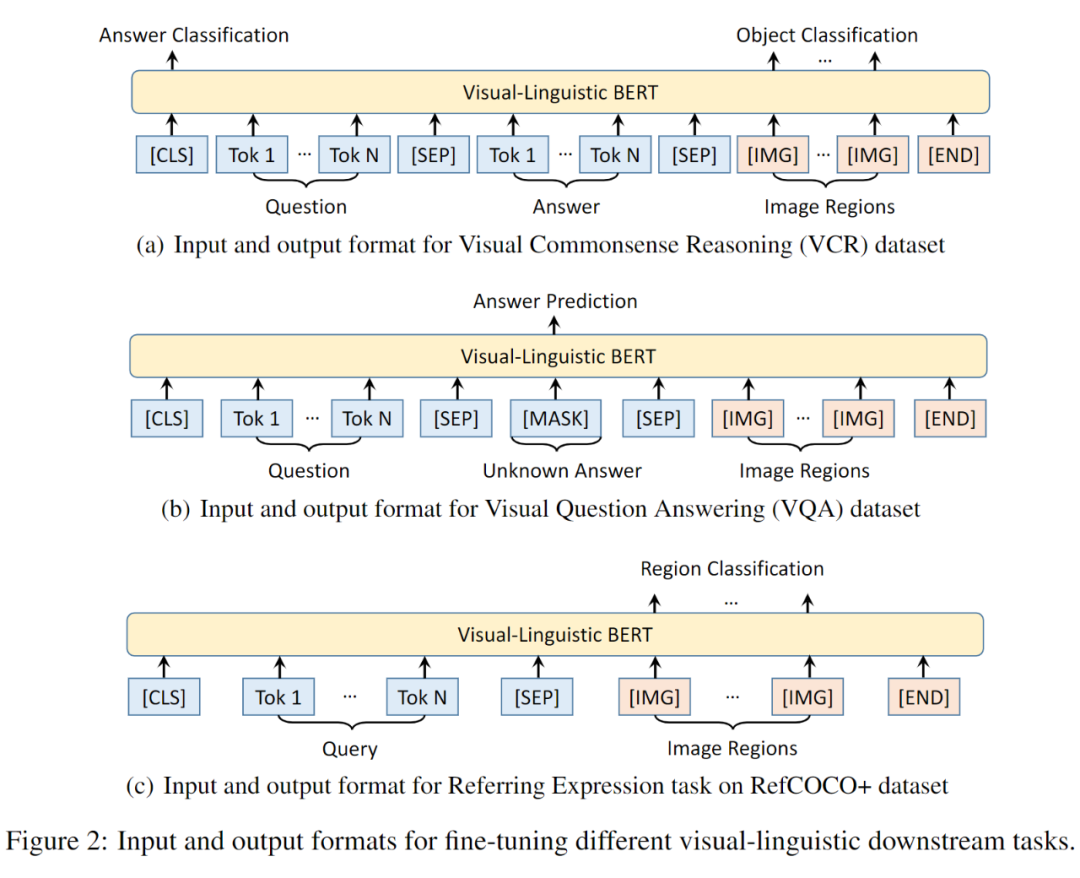
视觉常识推理任务即给定图片与相关问题,机器不仅需要回答问题,还需要提供理由来证明答案的正确性。此任务(Q->AR)被分解为两个子任务,即视觉问答(Q->A,给定图片与问题,输出正确答案),以及视觉推理(QA->R,给定图片、问题与答案,输出正确的理由)。
注意,这里比较有意思的一个点是,在(b)中使用了 msak 符号来进行预测答案来做生成任务。
VL-BERT 使用一个 single cross-modal Transformer,让文本和图片信息能更早更多的交互。但是我觉得这种暴力输入图片的时候,会导致输入参数量爆炸,也许不是一个好选择。还有做 MLM 的时候还是分成了两个任务,有没有办法把这两个任务整合成一个呢?
UNITER: UNiversal Image-TExt Representation Learning
https://readpaper.com/paper/3090449556
https://arxiv.org/abs/1909.11740
https://github.com/ChenRocks/UNITER
Motivation / Contribution
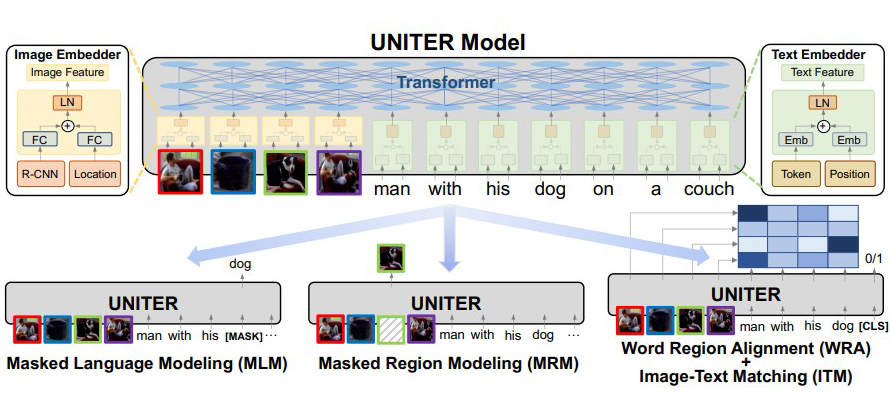
联合图像-文本的表征学习为大多数视觉+语言(V+L)任务的基础,一般通过联合处理多模态输入得到,用于实现对视觉和文本的理解。但是,这种特征通常是针对特定任务的。在本文将介绍一种通用的图像-文本表征学习 UNITER。UNITER 是通过在四个图像-文本数据集(COCO, Visual Genome, Conceptual Captions, and SBU Captions)上进行大规模的预训练而获得的,可以通过联合多模态嵌入为异构下游 V+L 任务提供支持。
研究人员设计了三个预训练的任务:掩蔽语言建模(MLM)、图像-文本匹配(ITM)和掩蔽区域建模(MRM)。UNITER 在 6 个 V+L 任务(超过 9 个数据集) 上实现了新的技术水平,包括可视化问题回答 、图像-文本检索、引用表达式理解、视觉常识推理、视觉蕴涵和 NLVR2。
a)有文本的预训练任务比没有文本的预训练任务效果更好;
b)Vison+Language 组合的预训练效果要好于单独的 Vision/Language;
c)最好的预训练组合是:MLM+ITM+MRC-kl+MRFP;
d)将上面提到的四个数据一起训练效果最好,这也证明数据越多效果越好。
(Yen-Chun Chen, 2019)介绍了一种通用的图像-文本表示方法 UNITER,它是通过对四个图像-文本数据集(COCO, Visual Genome, Conceptual Captions, and SBU Captions)进行大规模的预训练而获得的,可以通过联合多模态嵌入为异构下游 V+L 任务提供支持。
词嵌入 + 位置嵌入 -> Layer Normalization
Masked Language Modeling(MLM)(BERT)
Image-Text Matching(ITM)图片文字匹配问题
Word-Region Alignment(WRA)
使用 Optiomal Transport(自归一,稀疏化)来做单词和图片区域匹配的问题
Masked Region Modeling(MRM)
12-in-1: Multi-Task Vision and Language Representation Learning
https://readpaper.com/paper/3034727271
https://arxiv.org/abs/1912.02315
https://github.com/facebookresearch/vilbert-multi-task
https://zhuanlan.zhihu.com/p/150261938
Motivation / Contribution
1. 对 regions进行 mask 时,将 IoU 大于 0.4 的 regions 也 mask 掉,避免视觉信息泄漏;
2. 在多模态对齐的负样本采样时,不强制 masked multi-modal modelling loss,这样可以有效地降低负样本带来的噪声。
提出 Clean V&L Multi-Task setup,可以在多任务训练过程中,确保没有任务泄漏;
提出多任务训练模型,在 12 个 V&L 数据集上同时训练,在四个任务上进行了验证:Vocab-based VQA、Image Retrieval、Referring Expressions 和 Multi-modal Verification。
之前的 pre-training 工作,都是先进行 pre-training,然后在特定的 task 中进行 fine-tune,各个 task 之间是独立的。这样的话,VQA 的模型不能用来做 retrieval,每一个新的 task 都需要去重新 fine-tune 一个模型。
但其实呢,每个 task 之间是有存在相互促进的影响的,例如,学着表达「小红花瓶」和理解与回答「小红花瓶是什么颜色的?」是基本相同的概念。联合训练多个任务可以潜在地汇集这些不同的监督任务。而且,单独对于特定 task 去 finetune 对于小的数据集容易 overfitting,而 multi-task 同时训练可以减小这个问题。
(J Lu, 2019)基于 ViLBERT 开发了一个视觉-语言的多任务模型来学习 12 个不同的数据集。主要创新点在于设计了一个 mutil-task 的训练策略来联合训练多个 task,以及在 pre-train task 中加入了一些小的 trick。
设计了一个 mutil-task 的训练策略,Dynamic stop and go 策略。因为在 mutil-task learning 的过程中,有一个比较大的问题,就是有的数据库比较难,有的比较简单,那怎么同时去训练到,因为可能会出现在小数据集上 overfitting,而大数据集还训练不够。简单的说,就是它会去监控验证集的结果,就是对于每个 task 的如果两个 epoch 过后,他的 performance 提升少于 0.1%,那么就认为他已经收敛了,就停止训练,但如果一直停止的话,多个 epoch 过后,就可能会丢失掉这个 task 的信息,所以如果验证集的结果比最好的 task 减低 0.5% 之后,在重新开学训练这个 task。
1. Masked multi-modal modelling only for aligned image caption pairs,跟 BERT 一样的语言掩码,只是在 mask 的时候,只在成 pair 的 image-text 进行 mask, 这样可以避免 negative samples 带来的噪声。
2. Masking overlapped image regions(IOU>0.4),图片中可能存在一个问题,就是 mask 掉这个 region,去 predict 它的时候,因为图片存在 overlap,可能并 不需要依赖文本的信息,只需要通过这种 local 信息就能很好的预测出来, 如果把这种 overlap 大 0.4 的 region 也 mask 掉的话,可以强行让网络更多的 去依赖文本的信息来进行预测。
2020 年开始,就全面拥抱多模态表征的方法了。只不过,现在开始去寻找各个模型的问题,尝试给模型们修修补补。已经不满足于只是引用多模态表征了,而是彻底利用多模态表征。在这个时期一个重要的问题就是如何训练,这就包括了如何进行预训练以及如何引入更多的训练。
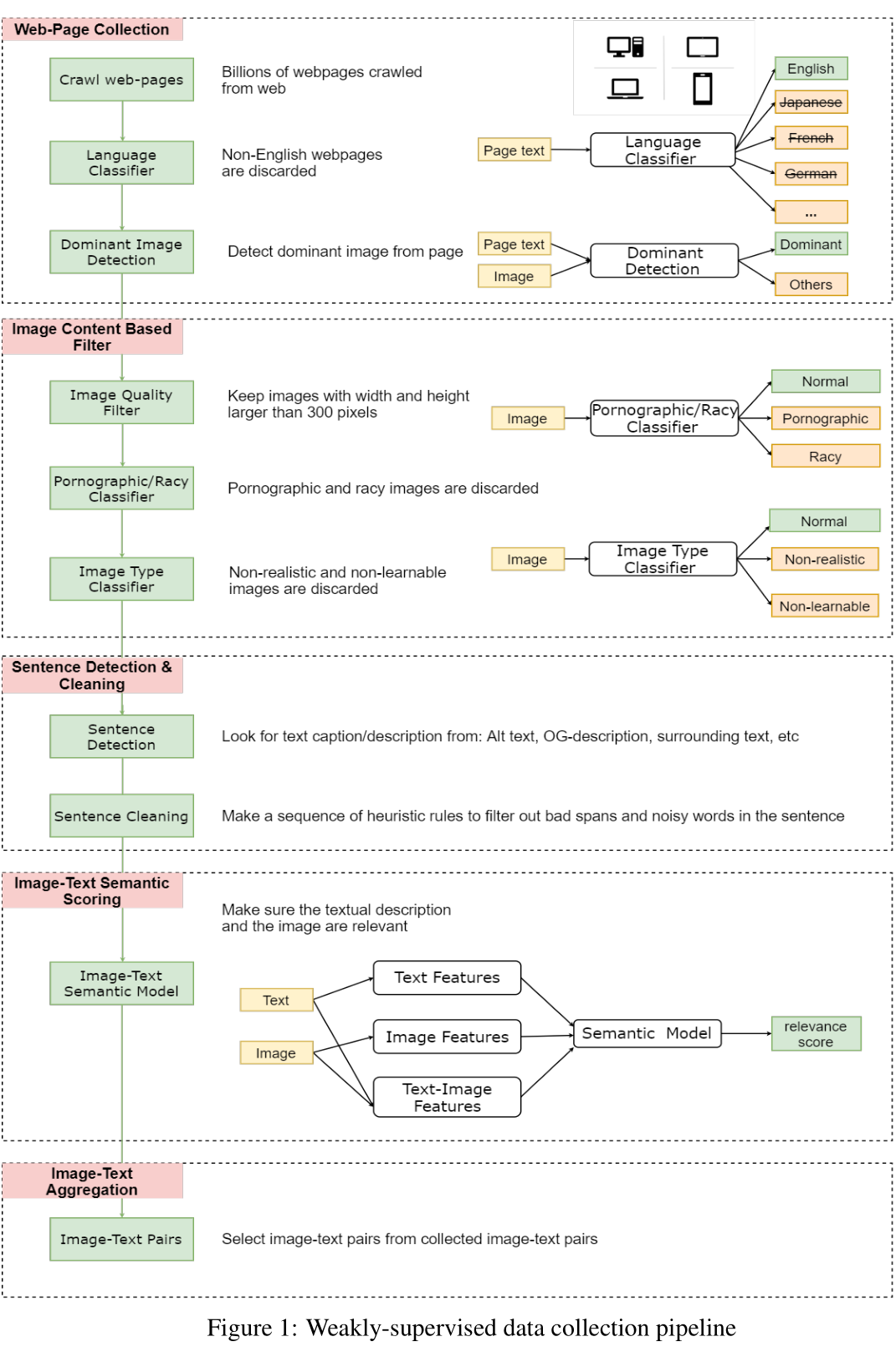
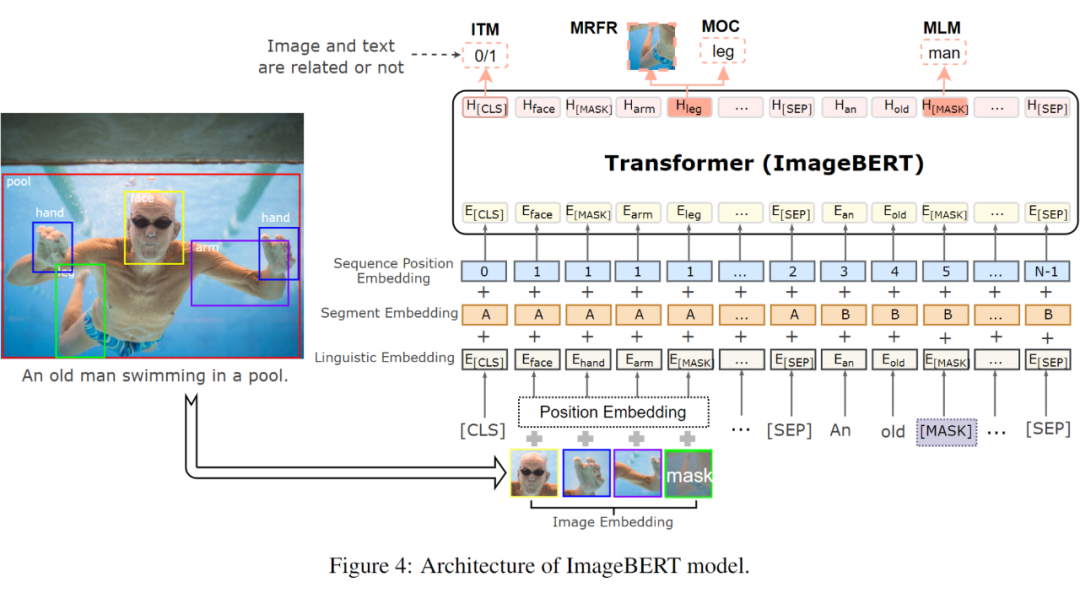
ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
https://readpaper.com/paper/3001555892
https://arxiv.org/abs/2001.07966
https://zhuanlan.zhihu.com/p/104879331
Motivation / Contribution
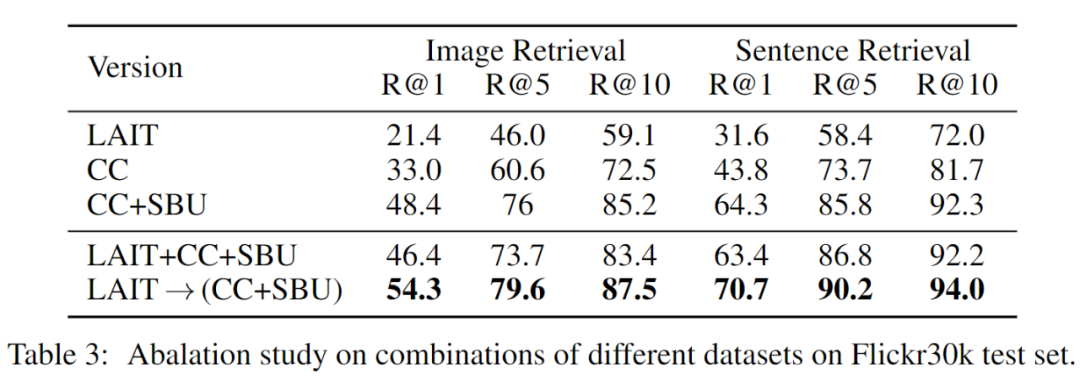
主要扩展数据,千万网上爬取处理好的图文 pair 数据(LAIT),之前 UNITER 组合了四个数据集(Conceptual Captions,SBU Captions,Visual Genome, MSCOCO),形成了一个 960 万的训练语料库,并在多个图像-文本跨模态任务上实现了最佳结果。LXMERT 将一些 VQA 训练数据增添到预训练中,并且在 VQA 任务上也获得了最佳结果。
先是从网络上收集数亿的网页,从中清除掉所有非英语的部分,然后从中收集图片的 URLs,并利用 HTML 标记和 DOM 树特征检测出主要图片(丢弃非主要图片,因为它们可能与网页无关)。
随后仅保留宽度和高度均大于 300 像素的图片,并将一些色情或淫秽内容的图片以及一些非自然的图片丢弃。
针对剩下的图片,将 HTML 中用户定义元数据(例如 Alt、Title 属性、图片周围文本等)用作图像的文本描述。
为了确保文字和图片在语义上是相关的,作者利用少量 image-text 监督数据,训练了一个弱 image-text 语义模型来预测 <text, image> 在语义上是否相关。用这个模型从十亿规模的 image-text 对中过滤掉相关性不高的数据,从而生成的数据集 LAIT(Large-scale weAk-supervised Image-Text),其中包含了 一千万张图片,图片描述的平均长度为13个字。
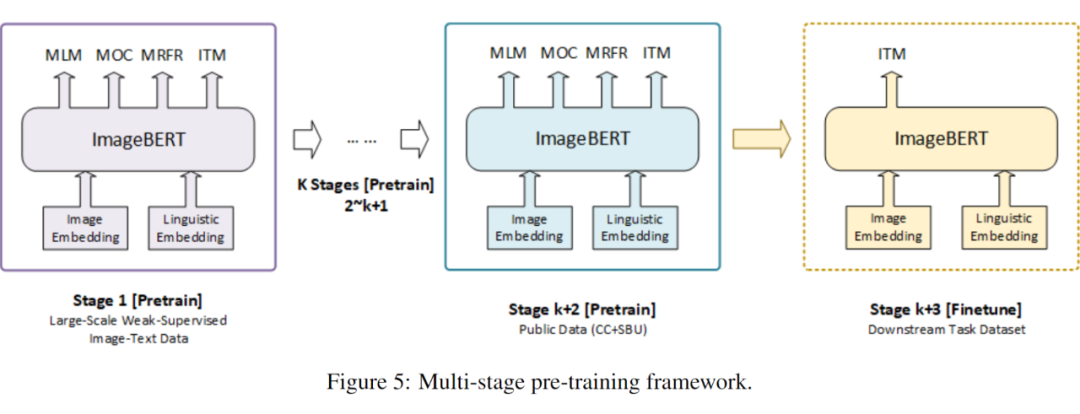
多阶段预训练 Multi-stage Pre-training
主要思想是先用大规模域外数据训练预先训练好的模型,然后再用小规模域内数据训练。在多阶段预训练中,为了有顺序地利用不同种类的数据集,可以将几个预训练阶段应用到相同的网络结构。
更为具体的,在 ImageBERT 模型中使用两阶段的预训练策略。第一个阶段使用 LAIT 数据集,第二个阶段使用其他公共数据集。注意,两个阶段应使用相同的训练策略。
掩码语言建模(Masked Language Modeling)
掩码对象分类(Masked Object Classification)
掩码区域特征回归(Masked Region Feature Regression)
图文匹配(Image-Text Matching)
其中掩码区域特征回归(MRFR),与掩码对象分类类似,其也对视觉内容建模,但它在对象特征预测方面做得更精确。顾名思义,该任务目的在于对每个掩码对象的嵌入特征进行回归。在输出特征向量上添加一个完全连通的图层,并将其投影到与汇集的输入 RoI 对象特征相同的维度,然后应用 L2 损失函数来进行回归。
Counterfactual Samples Synthesizing for Robust Visual Question Answering
https://readpaper.com/paper/3035517717
https://arxiv.org/abs/2003.06576
https://github.com/yanxinzju/CSS-VQA
https://zhuanlan.zhihu.com/p/269047073
https://blog.csdn.net/xiasli123/article/details/106098825
Motivation / Contribution
尽管视觉问答(VQA)在过去几年中已经取得了令人瞩目的进步,但是当今的 VQA 模型倾向于捕获训练集中的表层语言相关性,而不能推广到具有不同 QA 分布的测试集中。为了减少语言偏见,最近的一些工作引入了一个辅助的仅问题模型,以规范化针对性 VQA 模型的训练。
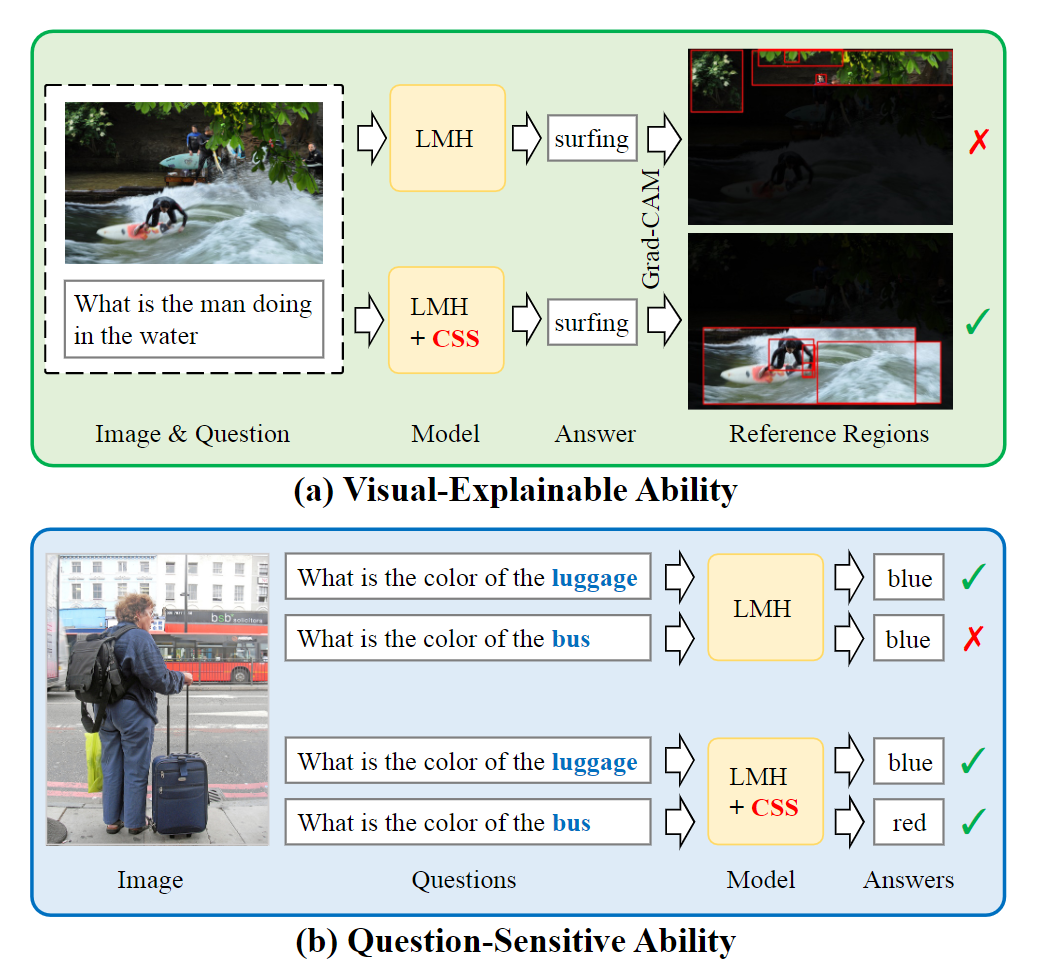
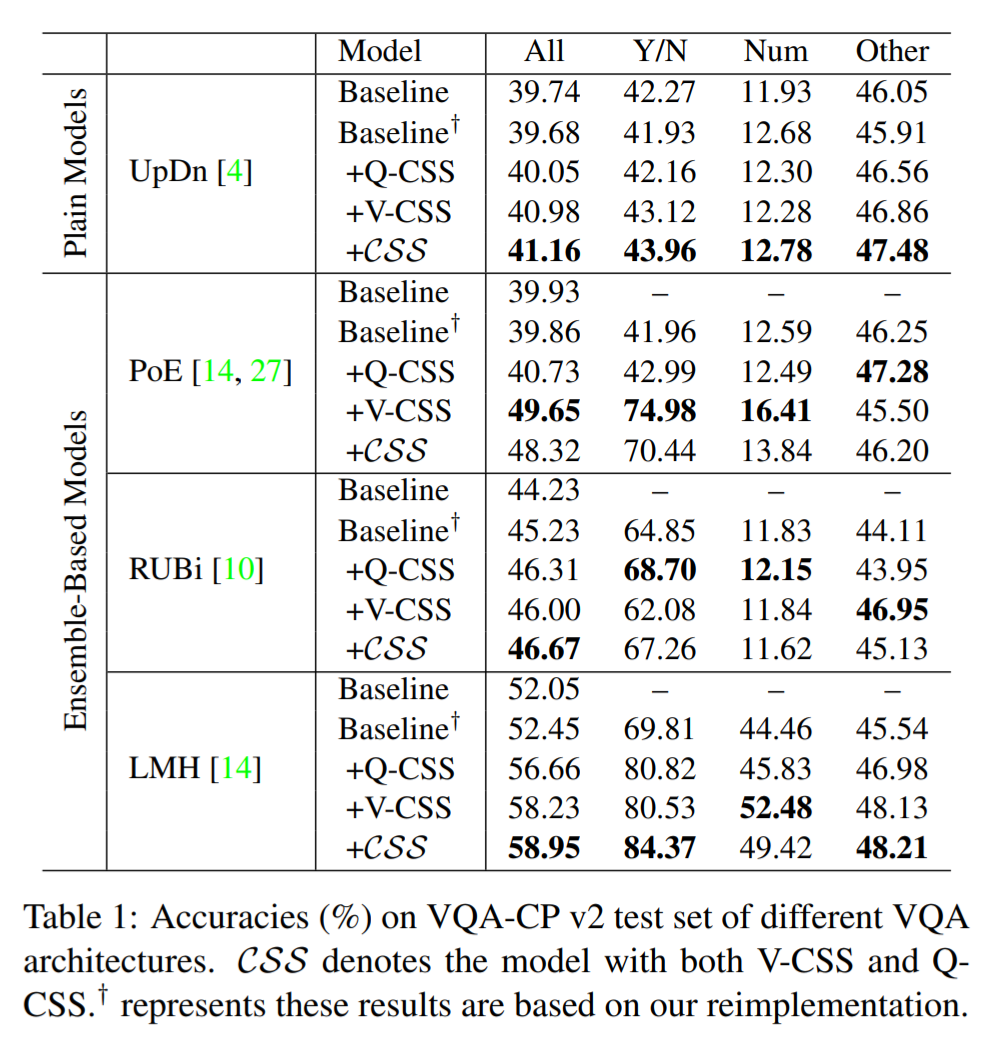
但是,由于设计的复杂性,当前的方法无法为基于集成模型的模型配备理想 VQA 模型(如图)的两个必不可少的特征:
1)视觉可解释能力:在做出决策时,模型应依赖正确的视觉区域。
2)问题敏感能力:模型应该对所讨论的语言变化敏感。
为此,作者提出了一种与模型无关的反事实样本合成(CSS)训练方案。CSS 通过掩盖图像中的关键对象或问题中的单词并分配不同的真实答案来生成大量反事实训练样本。在使用互补样本(即原始样本和生成的样本)进行训练后,VQA 模型被迫专注于所有关键对象和单词,从而显着提高了视觉可解释性和问题敏感性能力。
在上图(b)中,遮住图片中的关键对象“领带”,生成反事实图片。反事实图片、原问题和自动分配的答案合成一个反事实样例。在上图(c)中,遮住问题中的关键词“tie”,生成反事实问题。反事实问题、原图片和自动分配的答案合成一个反事实样例。视觉问答模型经过原训练样例和反事实样例的训练后,被迫关注关键对象和关键词 。
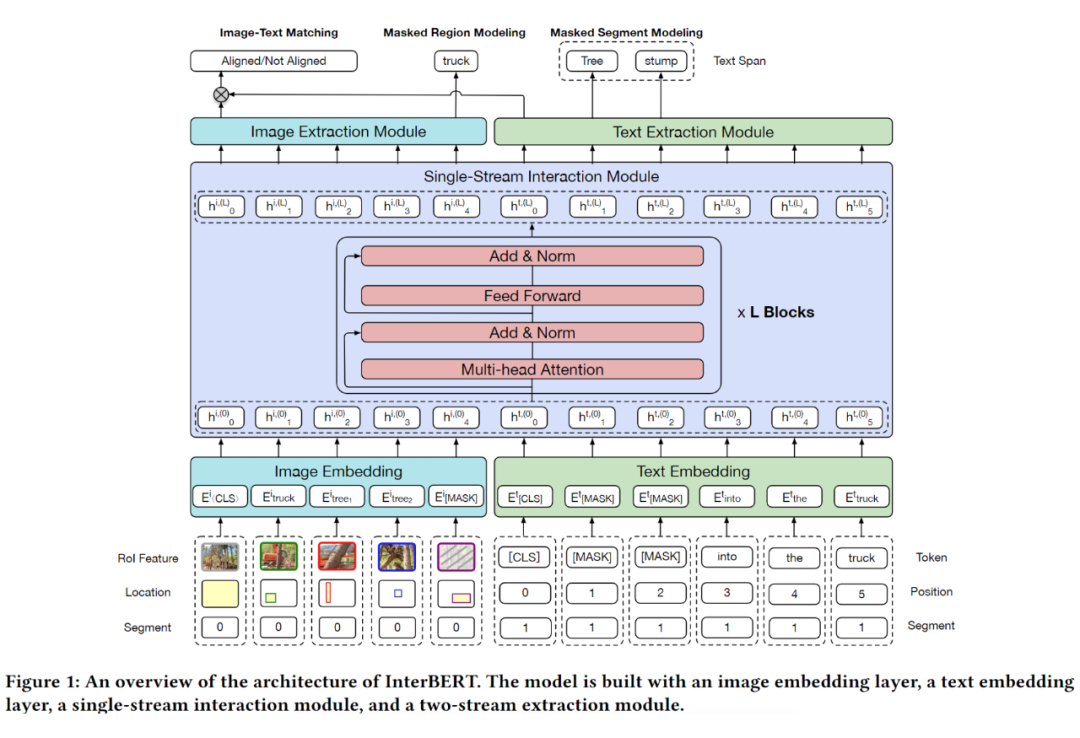
InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining
https://readpaper.com/paper/3035652667
https://arxiv.org/abs/2003.13198
https://github.com/black4321/InterBERT
https://zhizhou-yu-github-io.vercel.app/2020/06/14/Multimodal-Papers-Reading-Notes.html
Motivation / Contribution
现有的多模态预训练模型,存在两方面问题:一是预训练任务比较简单,例如 masked language/Object modeling 任务以及 image-text matching 任务;二是 single-stream 类模型例如 Unicoder-VL 仅仅是用 BERT 模型来融合两个模态的信息,而 two-stream 类模型例如 ViLBERT、LXMERT 仅仅通过 co-attention 融合各个 stream 的信息,缺乏 stream 内的 self-attention(原文:where there is no self attention to the self-context in each stream in the co-attention layers)。
基于上述,作者提出 InterBERT,包含一个 single-stream cross-modal encoder 除了各个模态的输入,并使用 two-stream encoder 分别处理不同模态的信息,以最大程度的进行模态间信息交互同时保留各个模态的独立性信息。另外,作者还提供了一个基于淘宝的 3.1M 大小的中文 image-text 多模态预训练数据集。
Two-Stream Independence Module:除了通过 Single-Stream Interaction Module 进行模态间信息融合,为了保留模态内的独立信息,作者为每个模态单独设计了一个 Transformer 结构来完成这一任务。
masked segment modeling(MSM)按照 10% 的概率挑选文本 mask 的锚点,随后以锚点开始 mask 连续的单词,平均长度为3,最后预测被 mask 的单词。
masked region modeling(MRM)按照 15% 的概率挑选图像 RoI mask 的锚点,随后将被选中的 RoI 以及与该 RoI 重叠 IOU 值大于 0.4 的 RoIs 一起 mask 为全 0 向量,预测被 mask 的 RoI 类别。
Image-Text Matching with Hard Negatives 构建了强负例(根据 tf-idf)首先在模型整体框架之上再次构建一个 MLP,将两个模态最后的输出相乘输入到 MLP 中得到最后的 matching score。
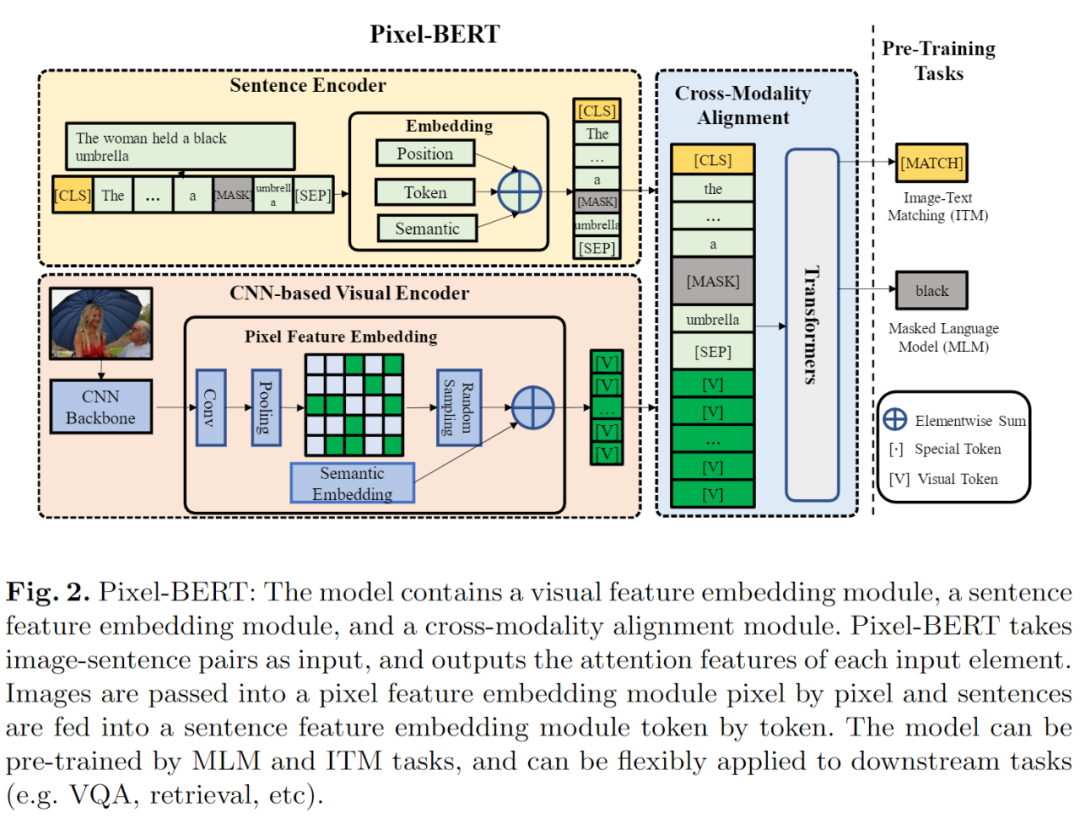
Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
https://arxiv.org/abs/2004.00849
https://www.youtube.com/watch?v=Kgh88DLHHTo
Motivation / Contribution
抛弃传统的 fastRCNN 提取目标及其锚框,利用(经过卷积/全连接)后的 region 特征来作为图像特征,
而利用 ResNet 直接对图像进行提取 Pixel 特征,这样可以避免忽略掉一些不能被识别的物体和背景信息。
这算是一个开端,终于有人意识到 FastRCNN 的问题了。
用 transformer 模型对 language 进行编码。同时,用 CNN 抽取 图像的特征,然后输入到一个特征映射模块中。该模块的特色是,随机的从中扣取 local feature patch,以防止过拟合。然后 language 和 vision feature 组合在一起,放到 transformer 模型中。
Overcoming Language Priors in VQA via Decomposed Linguistic Representations
https://readpaper.com/paper/2997072136
https://ojs.aaai.org/index.php/AAAI/article/view/6776
https://jingchenchen.github.io/files/papers/2020/AAAI_Decom_VQA.pdf
https://blog.csdn.net/BierOne/article/details/104566242
注:DLR-vqa 这个名字只是为了好编辑,我私自取的,原文作者并没有取。
Motivation / Contribution
针对于 VQA 领域,他们发现了一个 language prior problem。
现在的模型并没有学会依照 Image 来回答问题,而只是简单的依赖 answer 的比例。比如对于 what color 这类 question,答案为 white 占比为 80%,那么当输入这类问题,模型就直接回答为 white,而完全不需要依照 Image,且这样的正确率很高。
模型产生了某种惰性。(其实我认为,不不完全是如此,可以通过 attention,relu 等可视化的手段去观察,其实实际上还是可以学到的。当然,这个角度写 paper 还是挺不错的。)
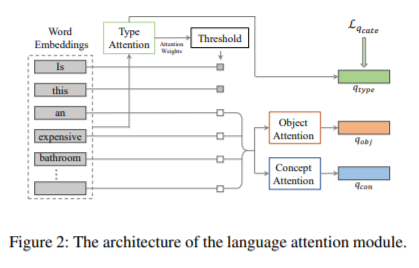
(1)我们学习问题的分解语言表示,并将基于语言的概念发现和基于视觉的概念验证解耦,以克服语言先验。
(2) 我们使用一个结合了硬注意机制和软注意机制的语言注意模块来灵活地识别问题中的不同信息,同时分离概念表征和类型表征。
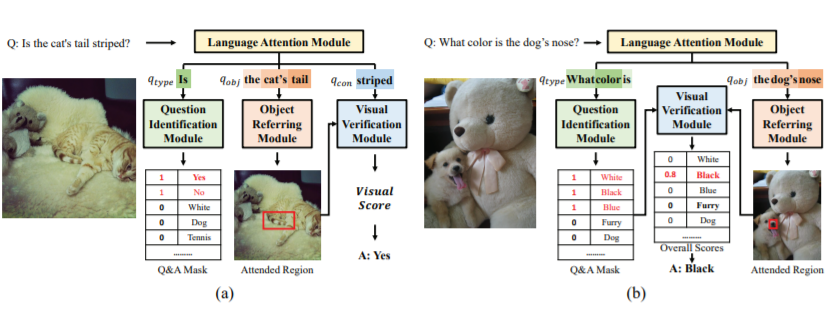
利用 question 的 type 作为先验来确定应该在哪个 answer set 上 predict。
如图(a),如果 question 属于 yes/no 这类,那么它的 anwer 集为 {yes,no},其它的一律去掉。然后通过
和 Image 信息采用 up-down attention 定位 region,最后再和
混合,进行二分类。
如图(b),如果 question 不属于 yes/no 这类,那么首先需要用
来预测 answer set,然后用
与 Image 进行 soft attention 得到最终的 image represention(与上面相同,)。最后,计算 answer set 中每个 answer 的得分即可。
三个部分组成:Type attention,Object attention, Concept attention。
其实这篇论文就是角度找的好,要是从 multi-task learning,估计就中不了了。
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
https://readpaper.com/paper/3091588028
https://arxiv.org/abs/2004.06165
https://github.com/microsoft/Oscar
https://zhuanlan.zhihu.com/p/150261938
Motivation / Contribution
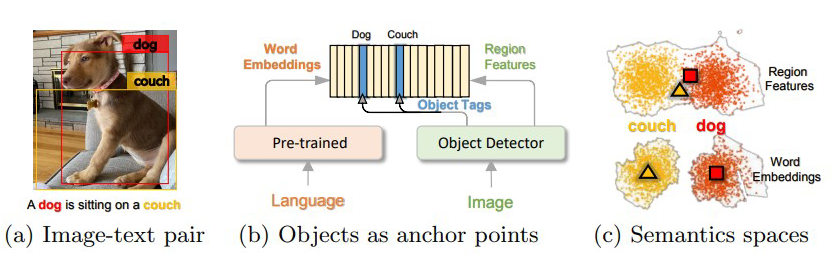
将相同语义下的物体(名词)作为图像和语言对齐的锚点(Anchor Point)从而简化图像和文本之间的语义对齐的学习任务。
也就是用 Faster-RCNN 检测出来的物体标签对应 caption 中的词建立一个关联
提出了 Oscar 预训练方法,这是一种强大的 VLP 方法,用于学习用于 V+L 理解和生成任务的通用图像文本表示。
现在基于 bert 来处理的 vision-language task 存在的问题:现在的方将 image region features 和 text features 拼起来,然后利用自我注意机制以暴力方式学习图像区域和文本之间的语义对齐。
由于没有显示的 region 与 text poses 之间的对齐监督,因此是一种弱监督的任务。
另外,vision region 常常过采样(region 之间有重叠),从而带来噪声和歧义(由于重叠,导致 region 之间的特征区分性不大),这将会使得 vision-language task 任务更加具有挑战性。
(Xiujun Li, 2020)通过引入从 images 中检测出的 object tags 作为 anchor points 来减轻 images 和 text 之间语义对齐的学习。
●
输入表示:将每个(图像-文本)样本定义为一个三元组(单词 序列, 物体标签,区域特征)。
●
预训练目标:根据三元组中三个项目的分组方式,从两个不同的角度查看输入:模态视角和字典视角。
字典视图的掩盖码恢复损失,它衡量模型根据上下文恢复丢元素(单词或对象标签)的能力。
模态视角的对比损失,它衡量模型区分原始三元组 及其“污染”版本(即原始物体标签被随机采样的标签替换)的能力。
1. A Dictionary View:Masked Token Loss,跟 BERT 语言掩码一样,对 text 路和 object tags 路进行 masked language modeling 的训练 task。
2. A Modality View:Contrastive Loss,实际上是一个二分类,当输入的三元组中,原始物体标签(object tags)被随机替换掉 50%,就认为是反例,反之为正例。
这篇文章如果去掉 Object Tags,就跟普通的多模态 BERT 没有区别了,但这样一个简单的操作,获得了目前 Image-base VL-PT 文章中所有任务的最好结果。
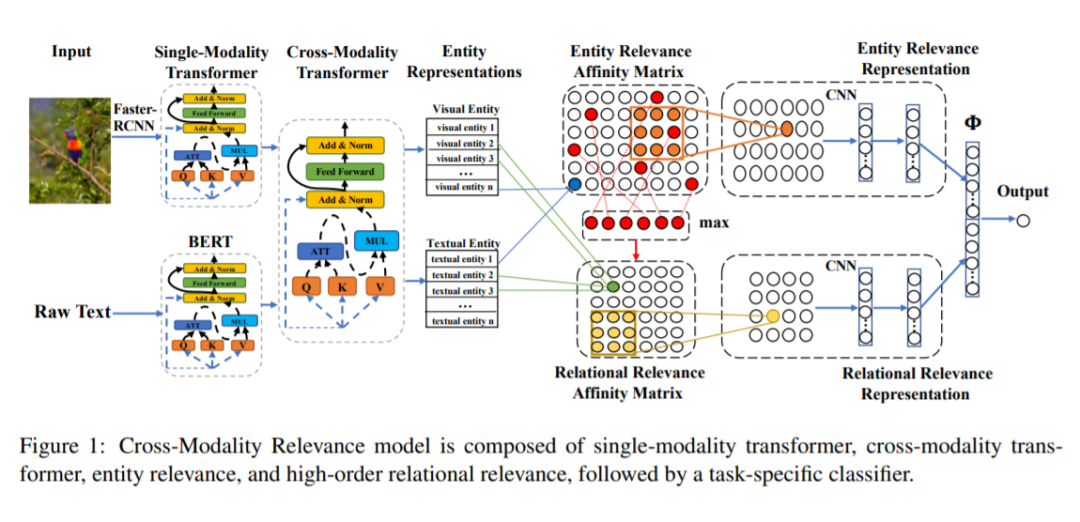
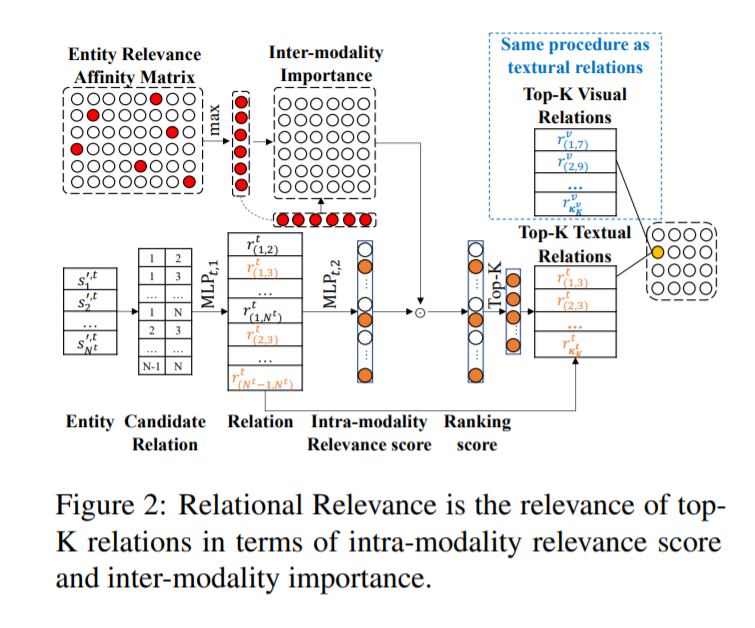
Cross-Modality Relevance for Reasoning on Language and Vision
https://readpaper.com/paper/3034649151
https://arxiv.org/abs/2005.06035
https://github.com/HLR/Cross_Modality_Relevance
https://blog.csdn.net/ms961516792/article/details/108254786
Motivation / Contribution
跨模态表示学习中,有一类方法致力于寻找处理不同模态数据时,components 和 structure 的相关性,现有的方法多使用注意力机制。随着信息检索领域的发展,寻找不同信息之间的相关性(也就是“matching”)作为核心问题,变得越来越重要。之后,Transformer 出现了,受益于“matching”,其在多个 task 上取得了 SOTA。但是,这种在注意机制中的“matching”是用来学习一组权重,来突出 components 的重要性,忽略了 relevance patterns。
1. 提出跨模态相关框架(cross-modality relevance framework),在一个对齐的空间中,同时考虑不同模态的实体相关性和关系相关性;
3. 在 VQA 和 NLVR 任务上,都达到了新的 SOTA。
Entity(Relational)Relevance Affinity Matrix,
Entity(Relational)Relevance Representation。
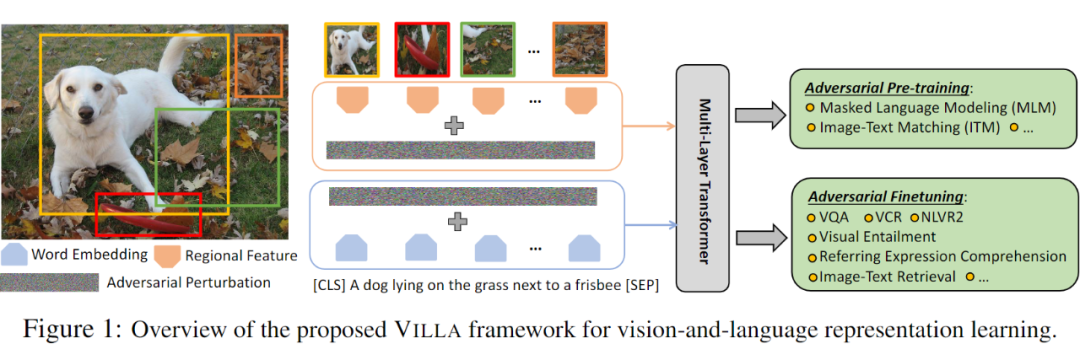
Large-Scale Adversarial Training for Vision-and-Language Representation Learning
https://readpaper.com/paper/3035688398
https://arxiv.org/abs/2006.06195
https://github.com/zhegan27/VILLA
https://www.cnblogs.com/wangxiaocvpr/p/13097962.html
Motivation / Contribution
受到前人对抗训练方法的启发,将其用到 vision-language model 的预训练中。
通过在 pre-training stage,执行对抗训练, 改善的泛化能力对微调阶段也是有益的。
在微调阶段,任务相关的微调信号变得可用,对抗微调可以用于进一步的改善性能。
由于 pre-training 和 finetuning 共享同一个数学表达式,同样的对抗算法可以在两个阶段都采用。
对抗的预训练和微调机制
在映射空间添加干扰
增强的对抗训练方法
Two-stage Adversarial Trainer
预训练和微调在本质上是紧密联系的。模型的训练需要掌握本质的推理技巧,从而促使模态融合,进行跨模态的联合理解。作者认为:
通过在 pre-training stage,执行对抗训练, 改善的泛化能力对微调阶段也是有益的;
在微调阶段,任务相关的微调信号变得可用,对抗微调可以用于进一步的改善性能。
由于 pre-training 和 finetuning 共享同一个数学表达式,同样的对抗算法可以在两个阶段都采用。
Perturbations in the Embedding Space
对于 image modality,由于最新的 V-L 模型通过将 pre-trained object detectors 作为输入,作者就直接在特征空间添加干扰。在预训练的 V+L model 中,位置映射是用于编码图像区域的位置和单词的索引。本文的方法仅仅改变了 image 和 word embedding 的映射,其他的多模态特征未变。此外,由于 image 和 text 模态的不同,作者仅对其中的一个模态添加扰动。这里加的扰动不能太大,否则会改变原始的语义信息,这是不能接受的
https://zhegan27.github.io/Papers/villa_slides.pdf
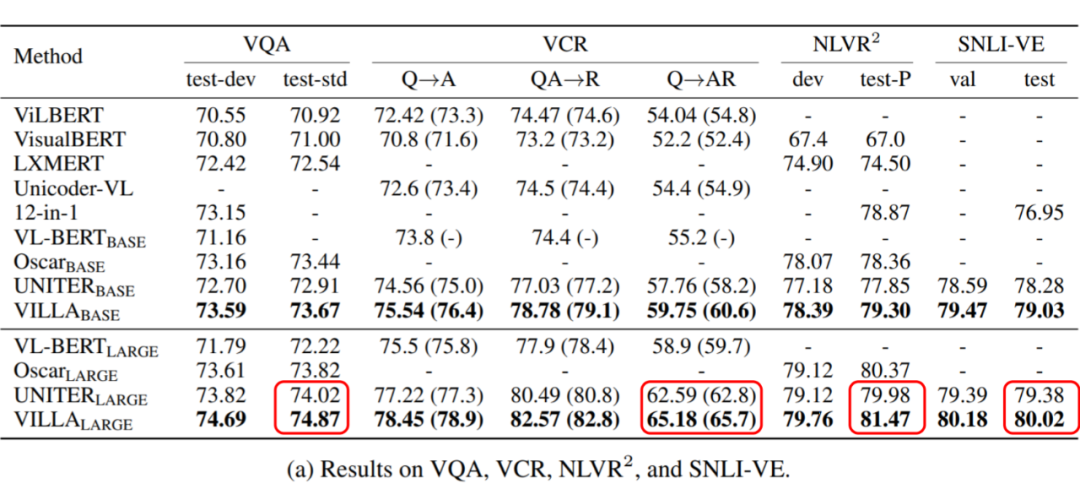
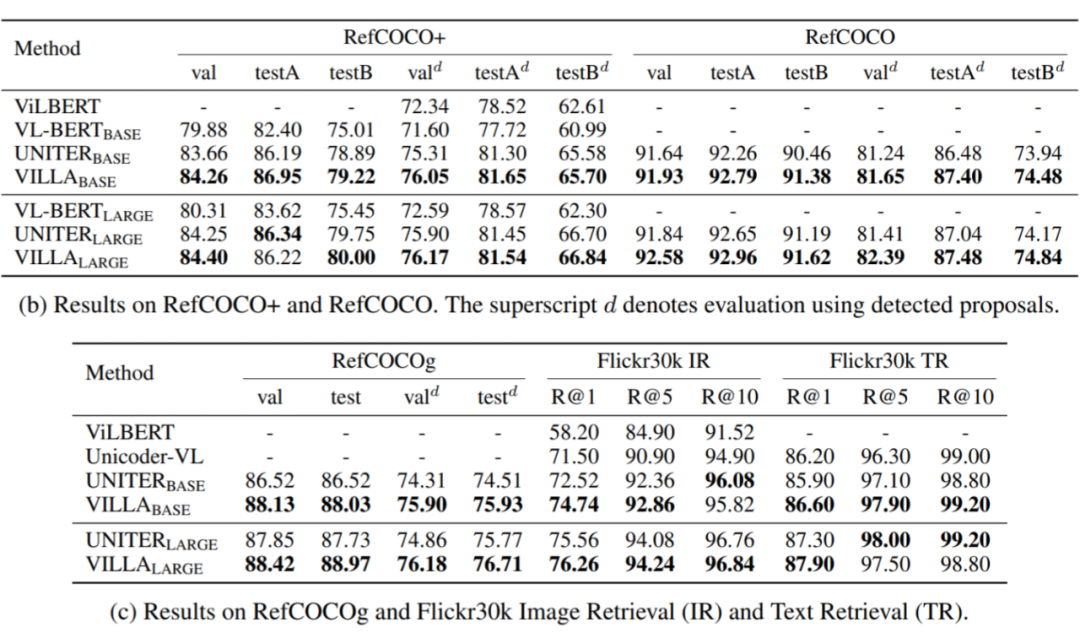
Results(VQA, VCR, NLVR2, SNLI-VE)
ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Gra
https://readpaper.com/paper/3038476992
https://arxiv.org/abs/2006.16934
https://github.com/PaddlePaddle/ERNIE/tree/repro/ernie-vil
https://zhuanlan.zhihu.com/p/362712915
Motivation / Contribution
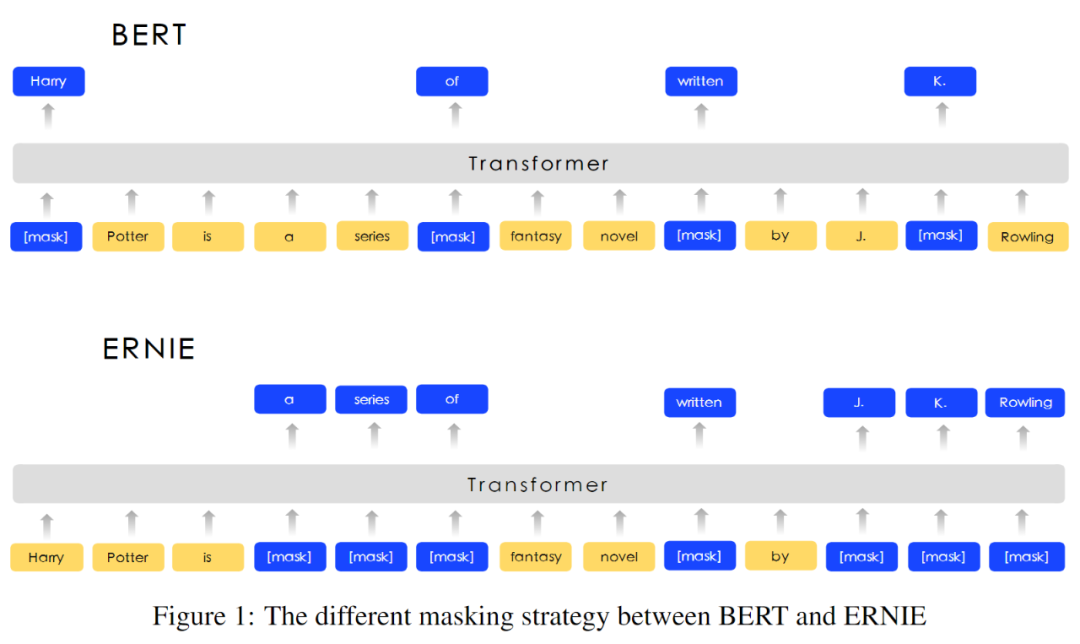
原始的 bert 采用 MLM 的方式进行模型训练,ERNIE
设计过一种 knowledge masking strategy ,mask 掉有有含义的表示部分,从而实现效果的提升。
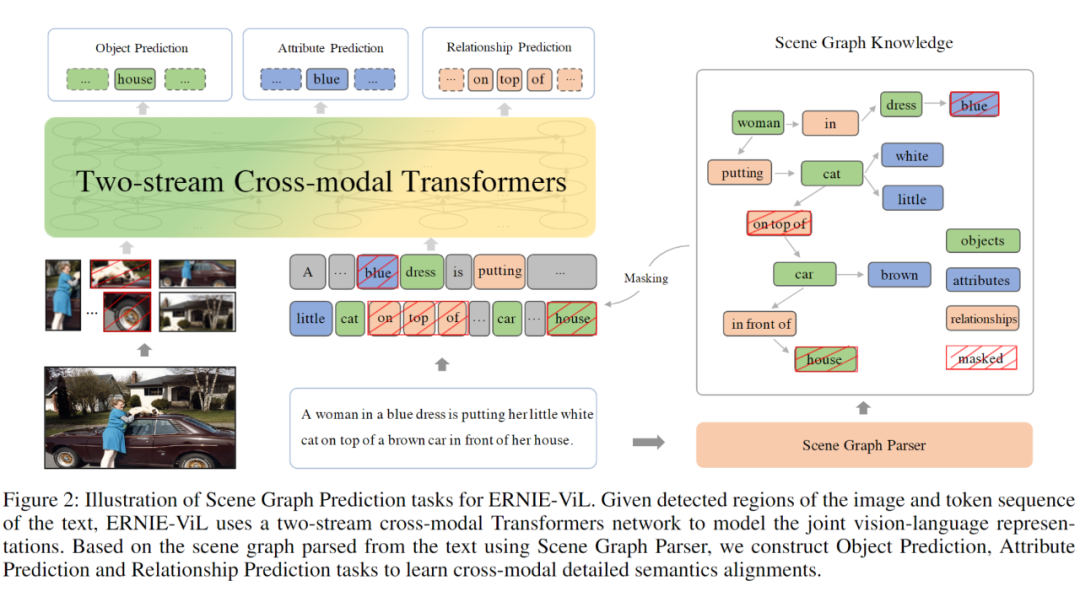
基于类似的想法, 为了提取出关键的内容部分, ERNIE-VIL 将场景图 引入到多模态预训练任务中来。场景图主要有三部分组成 物品、属性、关系,如下图所示:
在图像描述中,如果可以很好的抓住这些细粒度的语言特征,那么就可以很好的将图片分开来,进而提升多模态预训练的效果。
当我们看到图片时,我们首先关注到图片中的物品(Objects)、 特点属性(Attributes)和物品之间的关系。以这张图片描述为例,人、车、房子、猫、树组成了图片的基本元素。而物品的属性,如白色的猫、穿蓝色衣服的女人、棕色的汽车则是对物品进行更详细的刻画。物品之间的位置和语义关系如 “猫在车上”、“车在房前”构成了物体间的关联。我们通过物品、属性、关系可以描述出一个视觉场景的细粒度语义。
提出了三个多模态预训练的场景图预测(Scene Graph Prediction)任务:物体预测(Object Prediction)、属性预测(Attribute Prediction)、关系预测(Relationship Prediction)。
物体预测:随机选取图中的一部分物体,如上面图里的“house”,对其在句子中对应的词进行掩码,模型根据文本上下文和图片对被掩码的部分进行预测。
属性预测:对于场景图中的属性 - 物体对,如上面图里的“<dress, blue>”,随机选取一部分词对其中的属性进行掩码,根据物体和上下文和图片对其进行预测。
关系预测:随机选取一部分 “物体 - 关系 - 物体” 三元组,如上面图里的“<cat, on top of, car >”,然后对其中的关系进行掩码,模型根据对应的物体和上下文和图片对其进行预测。
掩码语言模型(Masked Language Modelling)
掩码图像区域预测(Masked Region Prediction)
图文对齐(Image-Text Matching)
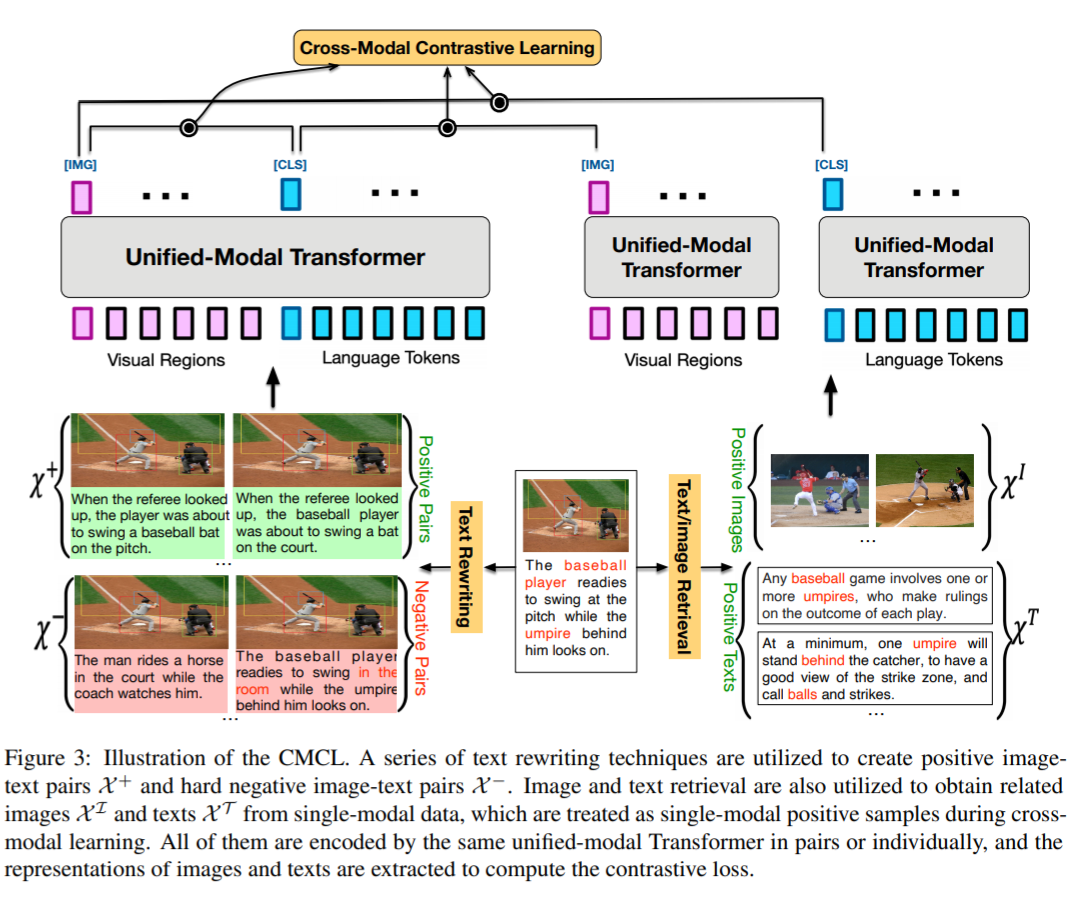
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
https://readpaper.com/paper/3118641406
https://arxiv.org/abs/2012.15409
https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO
https://zhuanlan.zhihu.com/p/422302599
Motivation / Contribution
预训练模型可分为 single-modal 和 multi-modal,前者使用大量的文本/图像进行训练(CV: VGG ResNet, NLP: BERT GPT RoBERTa),后者使用图文对进行训练(Cross-modal: ViLBERT VisualBERT UNITER)。然而,multi-modal 模型只能利用少量的图文对进行训练,只能学到 image-text 的表达,不能泛化迁移到 single-modal 的任务。因此,本文提出了一个 UNIfied_MOdal 预训练模型,该模型可以同时适应 single-modal 和 multi-modal 的下游任务。
使用了从互联网采集到的大量 non-paired 的 text 和 image 来学习更具有泛化能力的模型表达,提高模型图文理解能力和生成能力。
这个模型经过 fine-tune 后可以适应 single-modal 和 multi-modal 的下游任务(understanding and generation)
visual knowledge 和 textual knowledge 可以相互指导学习,最终达到了更好的效果。
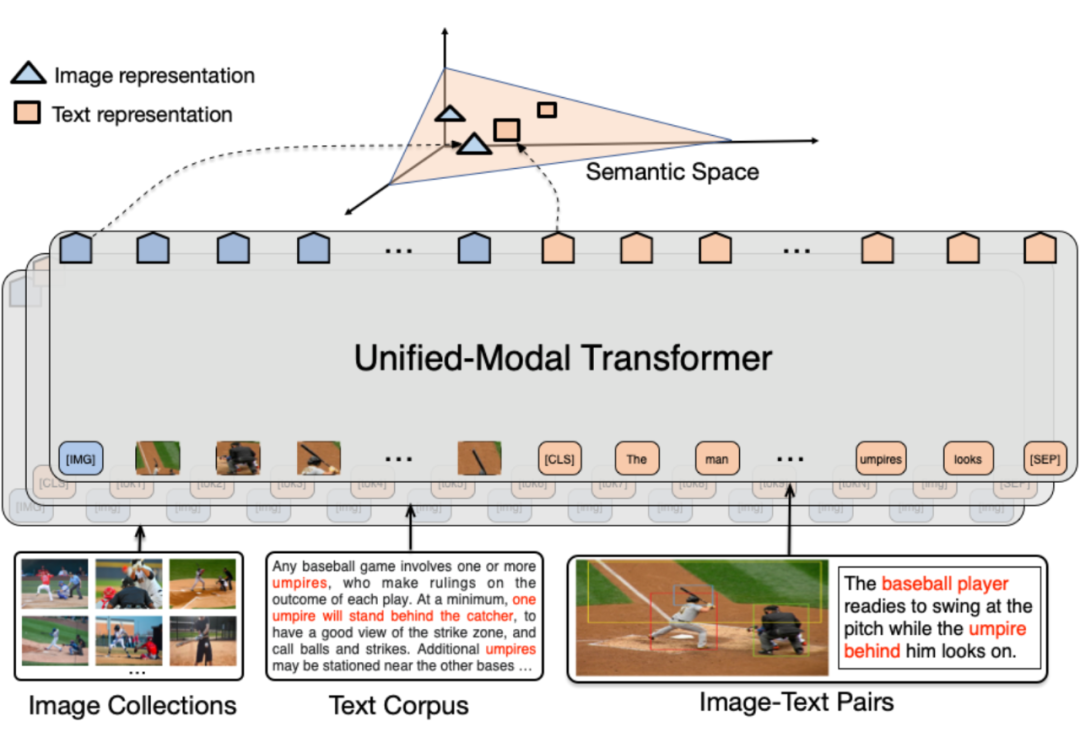
模型框架如图,本质是一个 multi-layer 的 self-attention transformers
文本——用 BPE 编码得到 W = {[CLS], w1, ..., wn, [SEP]} ,然后用 self-attention 得到 token representation {h[CLS] , hw1 , ... , hwn , h[SEP]}.
图像——用 Faster RCNN + ROI Pooling 得到 region features V = {[IMG], v1, ... , vt} ,同样利用 self-attention 得到 representation {h[IMG] , hv1 , ... , hvt}.
图文对 —— 将前面的特征 cat 起来 {[IMG], v1, ... , vt, [CLS], w1, ... , wn, [SEP]}. 送到 multi-layer transformer 来学到 cross-modal representation
visual——reconstruct the masked regions;
language——mask name-entities and reconstruct、Seq2Seq Generation、Bidirectional Prediction;
image-text pair——cross-modal understanding and generation
Cross-Modal Contrastive Learning
一般来来说,正样本是 image-text pair,而负样本则是从当前的 batch 中随机采样,然而这种随机采样的方法得到的 image/text 本身匹配程度很低,学出来的特征空间不能很好处理一些比较相似的图文对。因此,本文提出了一些数据增强(text rewriting, image/text retrieval)的策略以解决以上问题。上图为训练流程,经过数据增强后得到的正负 pairs 送进网络进行对比学习。针对 pair 的数据,直接将图文 cat 起来送进去,而用 retrieval 得到的 non-pair 的相似数据,用一个独立的 transformer 提取特征之后再与左边对应的图片/文字进行匹配。
纯文本 BookWiki and OpenWebText
纯图片 a subset of OpenImages and COCO unlabel
图片-文本对 COCO , Visual Genome(VG), Conceptual Captions(CC)and SBU Captions
UNIMO-base 用 RoBERTa-base,UNIMO-large 用 RoBERTa-large 来做初始化。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧