案例分享 | 文本反垃圾在花椒直播中的应用概述
文 / 杨照璐,花椒直播智能工程部算法工程师

一、背景
随着花椒用户和主播用户的数量不断增加,一些非法用户(垃圾虫)利用花椒平台数据流量大、信息传播范围广的优势,通过各种多媒体手段(文本、图片、语音、短视频等)在用户个人资料信息(昵称,签名,头像等)及直播间聊天等场景散播垃圾信息,这些信息严重影响了用户的观看体验,甚至会导致用户流失、活跃度下降,此外一些情节严重的违法违规内容会给平台带来运营风险和负面的社会影响。
二、问题分析
本文主要以文本为对象,简要地介绍花椒平台在文本反垃圾方面所采用的文本垃圾拦截技术。目前平台上所接触到的文本垃圾信息基本上可以概括为以下几个类别:
垃圾广告:各类商品广告、诈骗广告等
色情内容:色情词汇、色情服务及低俗信息等
暴恐、政治敏感词: 暴恐涉政、违禁品等
竞品信息及其他信息等
对于平台初期数据量较少、垃圾信息形式单一的情况,采用人工审核的方式基本可以解决问题。但是随着平台业务的拓宽与发展,业务量迅速增加,仅依靠人工审核方式无法应对,这时需要借助一些规则策略和算法模型辅助人工审核,以减少人工审核工作量,提高审核效率。
简单的垃圾信息,可以通过设置规则进行关键词过滤和屏蔽,正则表达则可以发挥很大作用。但是发布者为了逃避拦截,通常都会对垃圾信息进行改造和伪装,比如拼音替换,同义词替换,象形字替换,嵌入表情字符,用表情代替字符,甚至是将文字顺序打乱。对于复杂的信息,其表达形式广泛、没有规律,仅仅通过规则过滤达不到效果,可借助精准的算法模型进行检测。
垃圾信息拦截是一个常见的文本二分类任务,是自然语言处理领域的一个基本任务,目的是推断出给定的文本的标签。二分类问题常见的评价指标有准确率 (Accuracy),精准率 (Precision),召回率 (Recall),F1-score 等。
三、文本分类算法介绍
1、传统文本分类方法
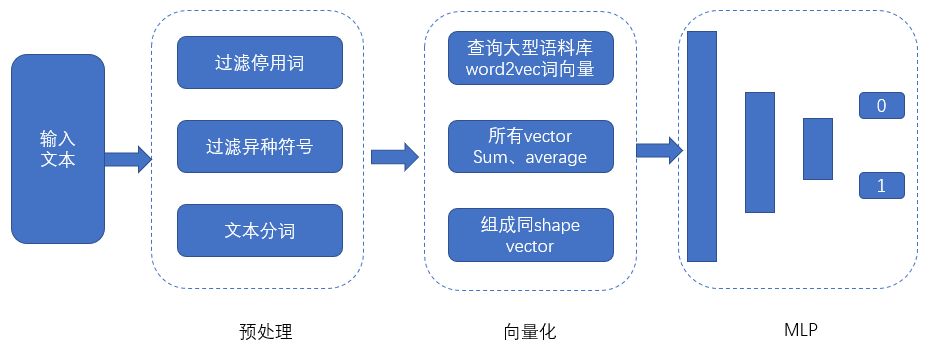
一般来讲传统机器学习文本分类任务过程包括文本预处理、特征提取、文本表示、训练分类器和分类性能评估。其中构建特征工程和分类建模方法是文本分类任务中最重要的两个环节。
文本的预处理包括文本分词、去除停用词(包括标点、数字和一些无意义的词)、词义消歧、统计等处理。中文与英文相比,在中文文本预处理过程中,首先要进行分词处理,而英文文本单词与单词之间通过空格即可分割,无需进行分词处理。
特征提取和文本表示目的就是将文本转化为计算机可以理解的向量形式。词袋模型 (Bag of Words) 是用于文本表示的最简单的方法, BoW把文本转换为文档中单词出现次数的矩阵,只关注文档中是否出现给定的单词和单词出现频率,而舍弃文本的结构、单词出现的顺序和位置。词频-逆向文件频率 (TF-IDF) 是一种在文本挖掘中广泛使用的特征向量化方法,主要衡量一个文档中词语在语料库中的重要程度。Word2vec 采用一系列代表文档的词语来训练 word2vec 权重矩阵,将每个词语映射到一个固定大小的向量。
分类器用的比较多的是 LR,SVM,MLP,GBDT 等,当然还有其他一些分类算法,这里不多赘述。
2、基于CNN的文本分类方法
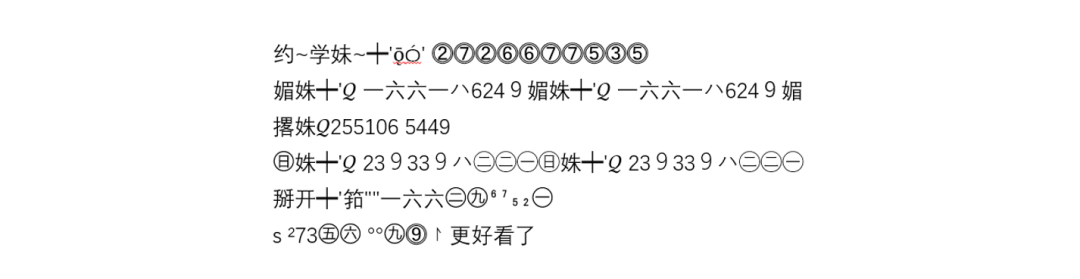
随着互联网的普及,一些用户为求彰显个性,开始大量使用同音字、音近字、特殊符号等异形文字(火星文)。由于这种文字与日常使用的文字相比有明显的不同并且文法也相当奇异,目前平台上遇到的难以识别样本大多是数字、QQ、微信的变种、多是象形字符,不含语义、分词模型对这些符号无法处理而且文本都很简短。
2.1、Bad case 样本示例
2.2、传统文本分类方法所存在的问题
这些文字如果使用常规的分词方法会导致分词失败
即使能成功分词,也很难查找到大规模语料库对词语进行向量表示
过滤异种符号和文字,导致抓不住火星文特征
因此需要一种不借助分词的模型,以单个字词为原子进行词向量表示,并且可以挖掘学习词与词之间的语序及语义信息。
传统文本分类方法除了上述问题之外,还存在数据稀疏和维度爆炸等问题,对分类器非常不友好,并且模型泛化能力有限。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,从文本中自动学习提取特征,降低了人工设计特征的难度,使用深度学习进行文本分类其效果往往要好于传统的方法。
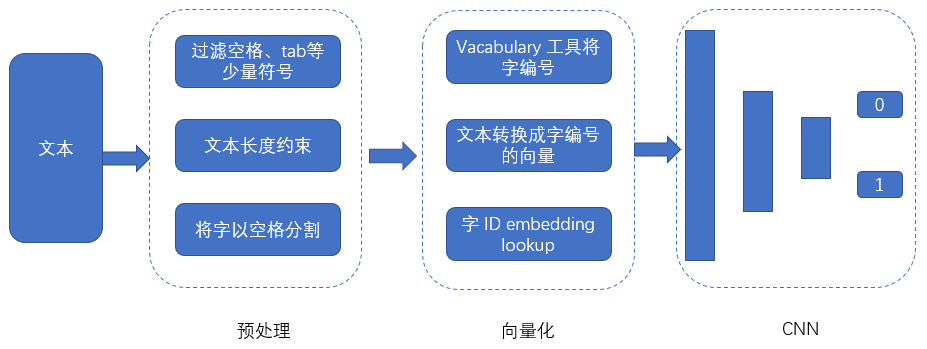
2.3、TextCNN 原理
-
避免分词,以字符为单位的文本向量表示 -
CNN 能捕捉局部区域的词序及语义信息,所表达的特征更加丰富 -
采用不同尺寸的卷积核,可以提取到 n-gram 的特征 卷积结构运算速度快,模型响应时长控制在 50ms 以下
2.4、模型结构
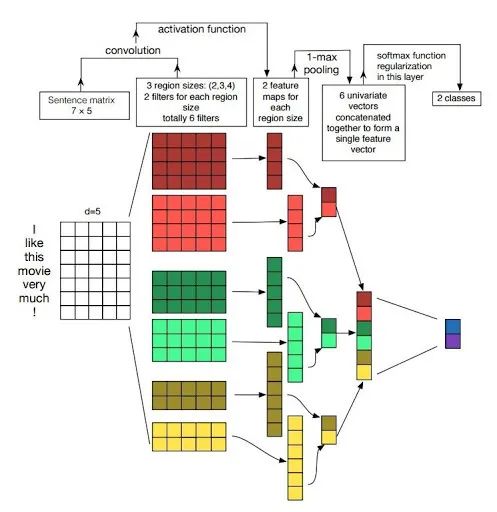
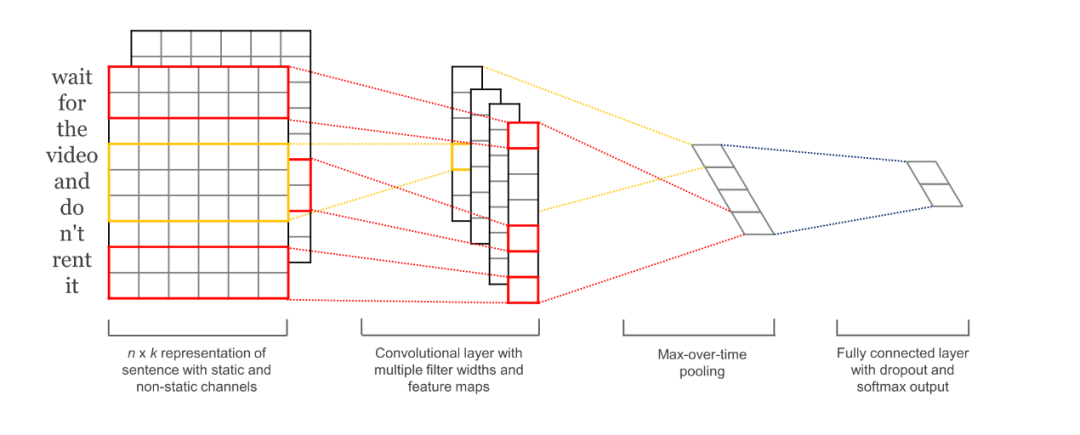
TextCNN 模型采用交叉熵损失函数,即将文本处理建模为一个二分类问题。该模型先将文本进行词嵌入 (Embedding) 获得词向量,然后采用不同尺寸卷积核进行卷积运算提取特征,接着进行最大池化 (Max pooling) 得到显著特征,最后接一个概率输出层 (Softmax) 进行文本分类。
2.5、卷积部分
例如有一个样本 T={"我","爱","花","椒","直","播"},样本输入长度为 N= ,词向量空间维度为 ,假设滑动窗口尺寸 ,则卷积核尺寸为 。
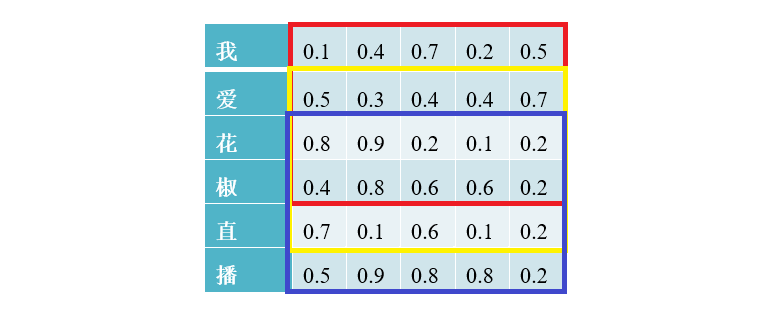
输入数据

同理,假设采用 三种尺寸卷积核,每种尺寸对应有 m 个卷积核,这样经过卷积运算后,每个尺寸的卷积核对应有 个 的卷积特征。
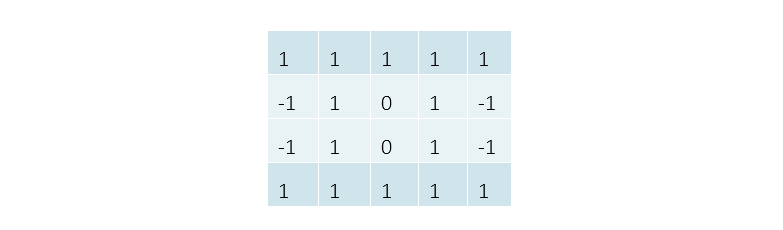
2.6、池化层
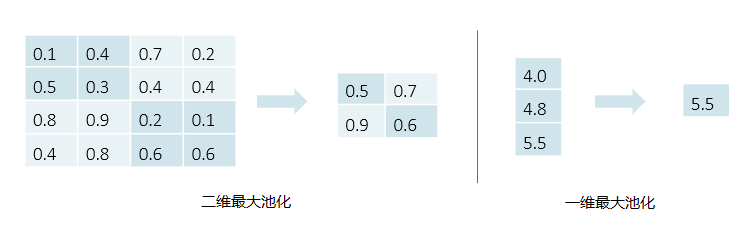
最大池化即对领域内特征点取最大值,通常情况下 max-pooling 能减小卷积层参数误差造成估计均值的偏移,更多的保留显著特征信息,最大池化的定义及示例如下:
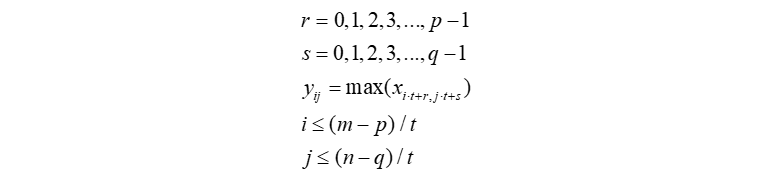
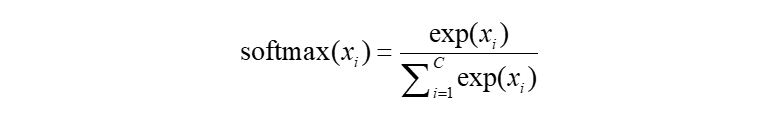
#coding:utf-8
import tensorflow as tf
import numpy as np
class TextCNN(object):
def __init__(self, sequence_length, num_classes, vocab_size, embedding_size,
filter_sizes, num_filters, l2_reg_lambda=0.0):
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
l2_loss = tf.constant(0.0)
#Embedding
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.get_variable('lookup_table',
dtype=tf.float32,
shape=[vocab_size, embedding_size],
initializer=tf.random_uniform_initializer())
self.W = tf.concat((tf.zeros(shape=[1, embedding_size]), self.W[1:, :]), 0)
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
#Convolution
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1,shape=[num_filters]), name="b")
conv = tf.nn.conv2d(self.embedded_chars_expanded,W,strides=[1, 1, 1, 1],
padding="VALID",name="conv")
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
pooled = tf.nn.max_pool(h,ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],padding='VALID',name="pool")
pooled_outputs.append(pooled)
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
#Output
with tf.name_scope("output"):
W = tf.get_variable("W",shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
#Loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
#Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
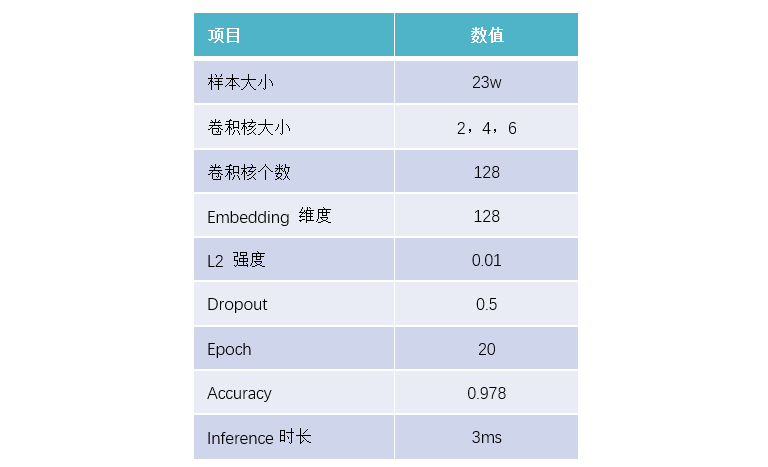
3、训练结果
4、训练部分小结
本节简要地介绍了传统方法在文本分类方法任务中的基本流程以及存在的问题,并且阐述了深度学习方法在文本分类任务中优势,以及 TextCNN 以单个字符为单位,采用卷积提取局部特征,对于处理类似火星文的文本更加鲁棒。此外之所以选用 CNN 而没有选用像 word2vec 以及没有提到的 RNN 等深度学习方法,是因为 CNN 相对于 word2vec 能获得更好的局部的语序信息及语义信息;相比于 RNN 而言,CNN 是分层架构,CNN 更适合提取关键特征,对于分类问题效果更好,而 RNN 是连续结构,更适合顺序建模,此外 CNN 适合并行计算,还可以采用 GPU 加速计算,响应时间短,inference 只有 3ms,非常适合垃圾文本检测速度的要求。
四、文本反垃圾模型线上部署流程
1、服务架构
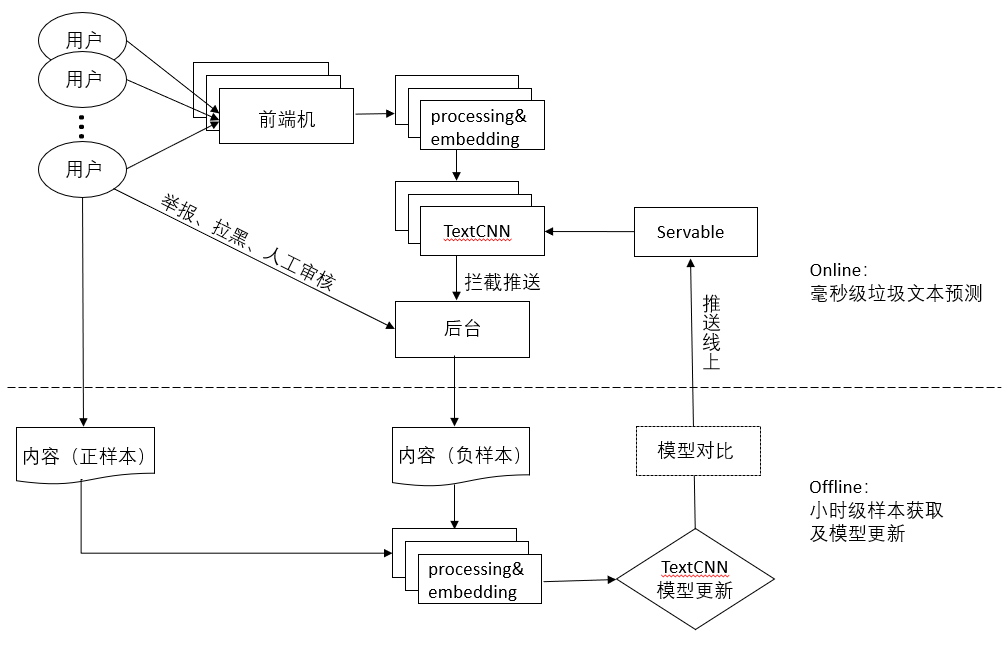
反垃圾服务分为线上与线下两层。线上实时服务要求毫秒级判断文本是否属于垃圾文本,线下离线计算需要根据新进的样本不断更新模型,并及时推送到线上。垃圾文本识别是一个长期攻防的过程,平台上的垃圾文本会不断演变,模型的效果也会随之变化。
2、 TensorFlow Serving模型部署
TensorFlow Serving 是一个灵活、高性能的机器学习模型服务系统,专为生产环境而设计。使用 TensorFlow Serving 可以将训练好的机器学习模型轻松部署到线上,并且支持热更新。它使用 gRPC 作为接口接受外部调用,服务稳定,接口简单。能检测模型最新版本并自动加载。这意味着一旦部署 TensorFlow Serving 后,不需要为线上服务操心,只需要关心线下模型训练。
3、客户端调用
TensorFlow Serving 通过 gRPC 服务接受外部调用。gRPC 是一个高性能、通用的开源 RPC 框架, gRPC 提供了一种简单的方法来精确地定义服务和自动为客户端生成可靠性很强的功能库。
在使用 gRPC 进行通信之前,需要完成两步操作:
定义服务
-
生成服务端和客户端代码
定义服务这块工作 TensorFlow Serving 已经帮我们完成了。TensorFlow Serving 项目中 model.proto、predict.proto 和 prediction_service.proto 这个三个 .proto 文件定义了一次预测请求的输入和输出。
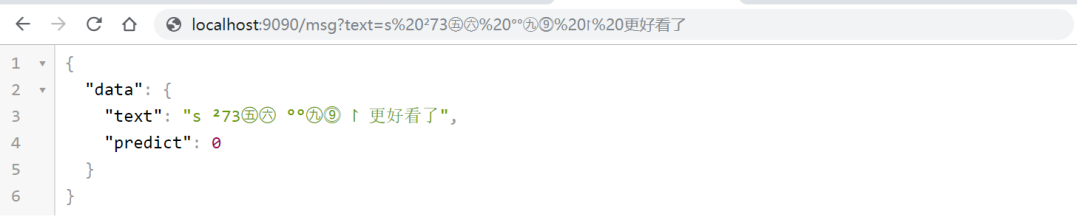
接下来用写好的客户端程序来调用部署好的模型,启动服务后,访问下面地址可以查看识别结果,说明模型部署成功且可以正常使用。
参考资料
[1] Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[2] http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture11-convnets.pdf
[3] https://www.cnblogs.com/ljhdo/p/10578047.html
[4] https://tensorflow.google.cn/tfx/serving/architecture
[5] https://baike.baidu.com/item/火星文/608814



加入案例分享,请点击 “阅读原文” 填写您的用例与相关信息,我们会尽快与你联系。





