
一 前言
二 质量建设痛点
-
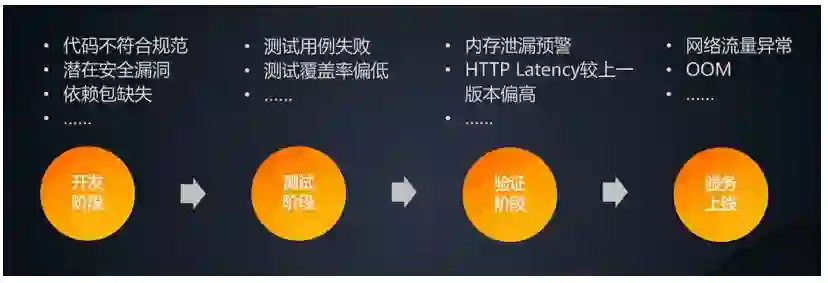
开发阶段:重点需要关注代码的质量,例如静态代码扫描以及依赖检查会发现潜在的代码缺陷和安全风险,由此我们可以统计千行代码缺陷率或者严重缺陷比例,从而来衡量一个系统的代码质量是否符合要求
-
测试阶段:在此阶段需要重点关注测试的质量,例如测试覆盖率,以及测试用例的失败率等指标
-
灰度验证:需要关注系统的稳定性以及不同版本之间的差异,因此也会有一系列的业务指标,例如HTTP Error 比例,不同版本的延迟等指标的对比
-
线上运行:此时需要重点关注系统的稳定性以及业务的稳定性,因此各种线上的性能指标、业务指标、应用日志、Trace等各种数据都是非常重要的
-
海量的异构数据:在系统开发、测试、验证、上线等各个阶段产生了大量的日志、时序、Trace 等数据,这些数据产生的位置、数据格式、以及存储的位置,都有可能是不一样的。如何从这些数据中快速精准地挖掘出潜在的质量问题比较困难。
-
依赖规则,缺乏智能:质量监控比较依赖于人的经验,很大程度上受限于人为设定的规则和阈值,无法做到数据自适应,因此无法发挥出真正的数据价值。另一方面就是随着系统的发展和演进,需要大量的人工干涉和不断调整,才能够让监控比较有效。
-
告警风暴与告警误报:为了不错过细微的问题,我们可能会配置大量的监控,从而导致在完整的软件生命周期中可能产生大量的告警,难以从其中识别出有效信息。另外大量的告警也带了很大程度上的误报问题,从而导致“狼来了”效应,于是真正的问题反而很容易又被忽略掉。这就陷入了恶性循环。
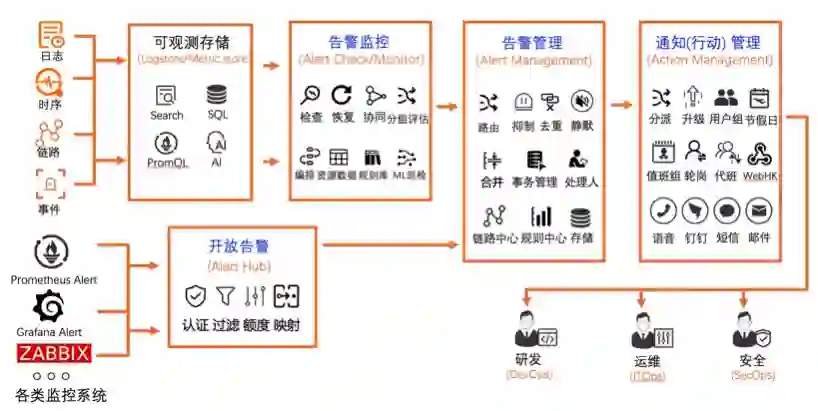
三 数据统一接入和管理
1 海量数据管理痛点
-
运维成本高:完整的质量系统需要数个甚至十多个软件的协同,从而也带了极高的运维成本。
-
学习成本高:每个软件都有自己的使用插件、插件系统,有些还会有自己的DSL语法,学习成本非常高,很难完全掌握使用。
-
扩展困难:随着数据规模的增长,软件的扩展能力、性能、稳定能力等方面都会有很大的挑战。
-
数据孤岛:不同的数据处于不同的系统中,协同困难。例如想要将 ES 中的日志和 Prometheus 中的指标进行一个 Join 查询就无法实现,除非做额外的二次开发。
2 数据统一接入和管理
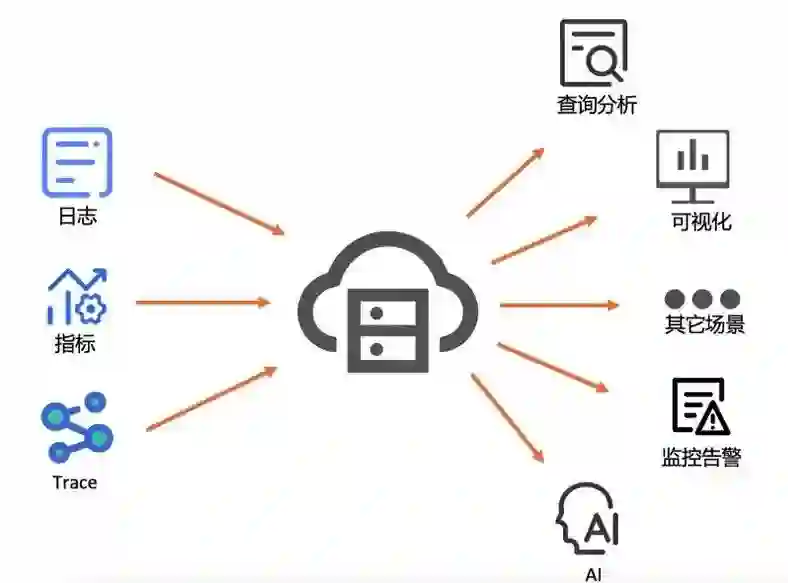
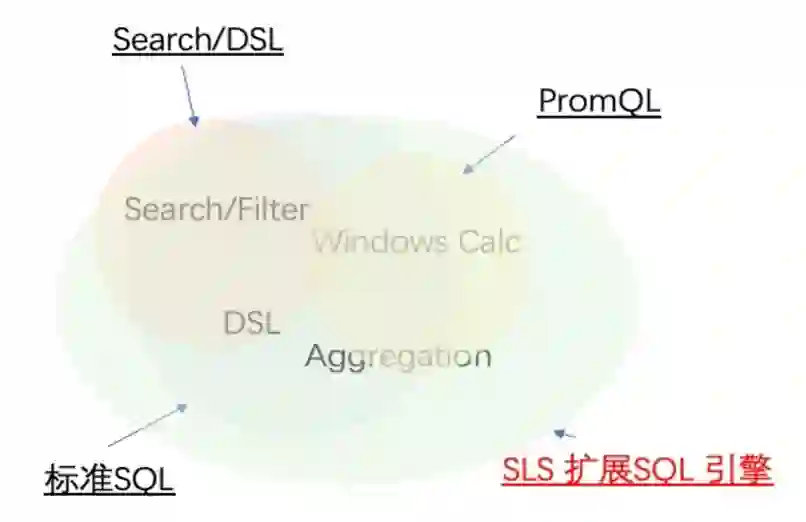
-
我们可以通过标准 SQL 语句对日志进行分析 -
还可以通过 PromQL 扩展的 SQL 函数对指标数据进行分析
-
还可以通过嵌套查询,对指标数据的分析结果进行再聚合 -
此外还可以再通过机器学习函数,给查询和分析赋予 AI 的能力

四 智能巡检
1 传统监控的困难和挑战
-
监控对象爆炸式增长:随着云原生的普及,服务部署越来越从以“主机”为中心向“容器化”方向转化,容器本身的轻量化以及短生命周期等特点,导致监控对象和监控指标急剧增加。如果要全方位的覆盖这些监控对象和指标,需要配置大量的监控规则,并且它们的阈值也可能是各不相同的,因此会有很大的工作量。

-
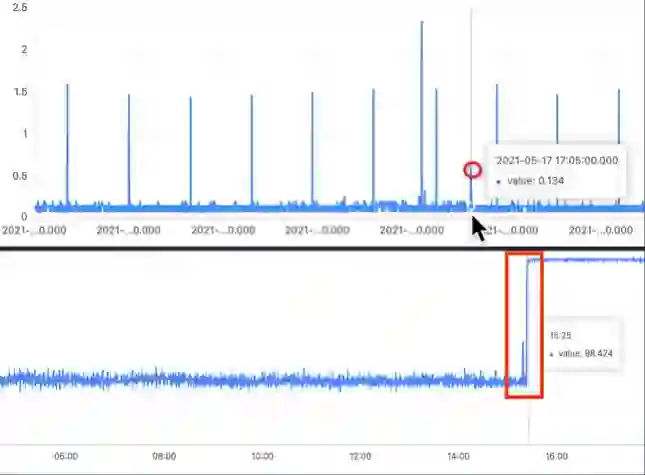
监控规则无法自适应:基于人为定义的阈值,很大程度上依赖于人的经验,随着系统的演化和业务的发展,这些规则往往不能很好地适应,由此不可避免地导致漏报、误报等问题。无法做到数据的自适应,因此需要人为介入,不断调整阈值。例如下图:
-
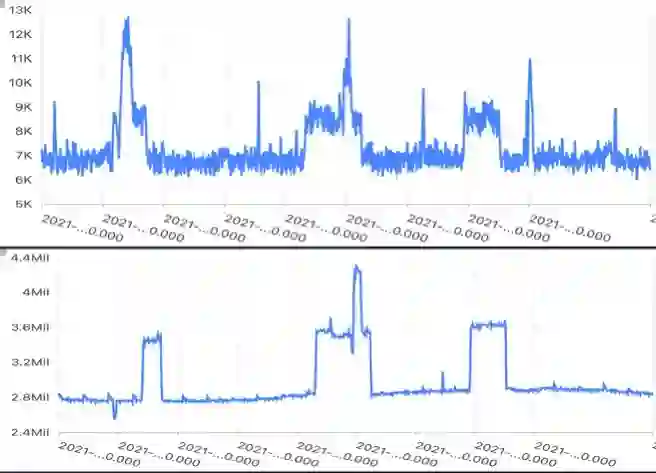
上面是一个指标,有规则性的毛刺。如果通过阈值来判断是否需要告警,当一个毛刺点异常的时候,可能由于不满足阈值,导致告警漏报。
-
下面是另一个指标,可能随着系统的进化,新版本发布之后,该指标的值会发生一个陡增。此时如果是固定阈值告警的话,会将陡增之后的所有数据都认为是异常点,导致告警频繁触发。此时需要人为介入去调整阈值。
-
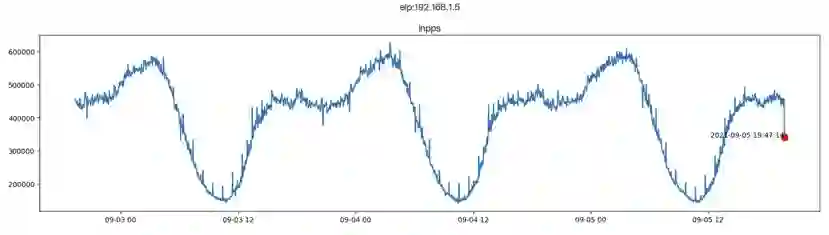
监控规则泛化能力弱:不同的业务、甚至同一业务的不同版本,指标的规律性、阈值都有可能是不同的。因此我们需要为不同的业务、不同的版本去做监控规则的适配。例如下图,虽然两个指标整体上有着比较相似的波动规律,但是由于它们的取值范围、以及局部的抖动情况会有差异,因此需要分别去做监控。
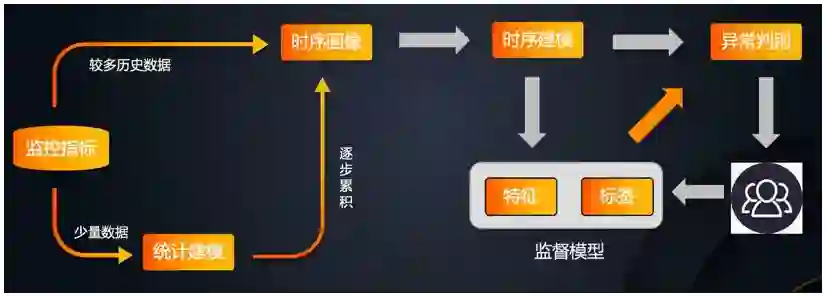
2 智能巡检
-
智能前置:现在有很多系统是在告警触发后,进行智能的管理,但是这无法避免告警误报、漏报等问题。智能巡检可以将 AI 的能力前置到监控层,从而在源头上避免潜在的告警问题,挖掘出真正有效的数据价值。
-
监控自适应:可以基于历史数据自动学习和进化,进行动态的阈值判断,从而让告警更加精准。另外对数据的学习也是实时的,可以更加快速地发现异常问题。
-
动态反馈:除了自动学习之外,还可以通过用户的反馈,对告警进行确认或者误报标记,将 AI 能力与人的经验相结合,相辅相成,进一步完善模型,减少误报。
3 智能巡检实现思路
五 告警智能管理
1 告警管理痛点
-
多套工具难维护:在不同的阶段可能使用了不同的工具,每个工具可能都提供了一部分的告警能力,最终导致难以维护。好在通过统一的数据接入和管理,我们可以统一去配置监控和管理告警。
-
海量告警无收敛:另一个问题就是,海量的告警难以收敛,尤其是当告警之间有相互依赖关系的时候。例如主机负载高,导致该主机上服务异常、接口延迟高、HTTP Error 报错多等多种问题并发,从而段时间内有大量的告警触发,以及大量的告警消息通知。缺乏合理的降噪机制。
-
通知管理能力弱:许多告警管理系统只是简单地将告警消息发送出去,存在着通知渠道不完善、通知内容不符合用户需求、无法支持值班需求等等问题。
2 告警智能管理

-
自动去重:每个告警会根据告警自身的关键特征计算出一个告警指纹,然后根据告警指纹自动去重。例如:某主机每一分钟触发CPU使用率过高告警,1小时触发60次,但对于告警管理系统来说,这只是一个告警的60个快照,而不是60个独立的告警;同时假如通知设置为30分钟重复,则一共只会发送两次通知,而不是每一分钟就发送一次通知。
-
路由合并:相关的告警合并起来,一并进行通知,而不是针对每个告警分别通知,从而减少通知的数量。例如:根据告警所在集群进行合并,假如某集群短时间内产生了10个告警,则只会发送一条通知,包含这10个事件。
-
告警抑制:主要用于处理告警之间的互相影响。例如:某一k8s集群发生OOM严重告警,可以暂时忽略同一集群的低级别告警。
-
告警静默:满足特定条件的告警无需通知。例如:测试集群在凌晨有计划内变更,期间服务会有短暂不可用,触发预期内告警,该告警可以忽略。
-
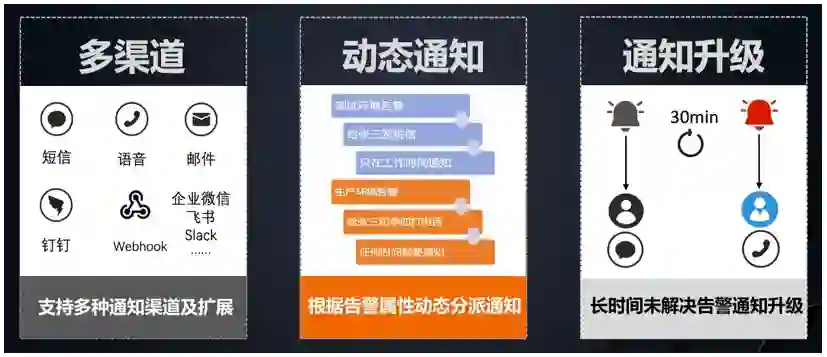
多渠道:支持短信、语音、邮件、钉钉等多种通知渠道,同时还支持通过自定义 Webhook 进行扩展。同一个告警,支持同时通过多个渠道、每个渠道使用不同的通知内容进行发送。例如通过语音和钉钉来进行告警通知,既可以保证触达强度,又可以保证通知内容的丰富程度。
-
动态通知:可以根据告警属性动态分派通知。例如:测试环境的告警,通过短信通知到张三,并且只在工作时间通知;而生产环境的告警,通过电话通知到张三和李四,并且无论何时,都要进行通知。
-
通知升级:长时间未解决的告警要进行升级。例如某告警触发后,通过短信通知到了某员工,但是该问题长时间未被处理,导致告警一直没有恢复,此时需要通知升级,通过语音的方式通知到该员工的领导。

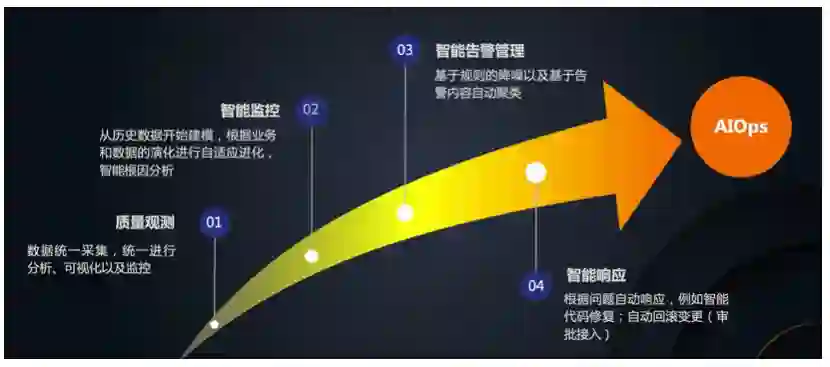
六 总结和展望
-
目前质量观测,数据的统一采集和管理,分析、可视化、监控等能力已经都相对完善
-
从监控角度来说,智能巡检已经可以比较好的自适应数据,另外就是进行智能根因分析,自动发现问题的根源,加快问题溯源,减轻排障困难
-
告警的智能管理,除了基于规则的降噪,还会加入更多的算法支持,根据告警内容自动进行聚类,减少告警通知风暴
-
最后一步是问题的后续响应,目前我们已经可以通过对接自定义的Webhook来进行一些简单的操作,后续还会加入更多自动化的能力,例如代码故障自动修复,自动回滚变更等。
链接:
