全球1000名科学家组成BigScience,超大NLP模型BLOOM来了!

新智元报道
新智元报道
【新智元导读】最近,由1000多位科学家组成的团队历时117天,搞出来了个超大的开源NLP模型。



算力:蹭了价值300万欧元的
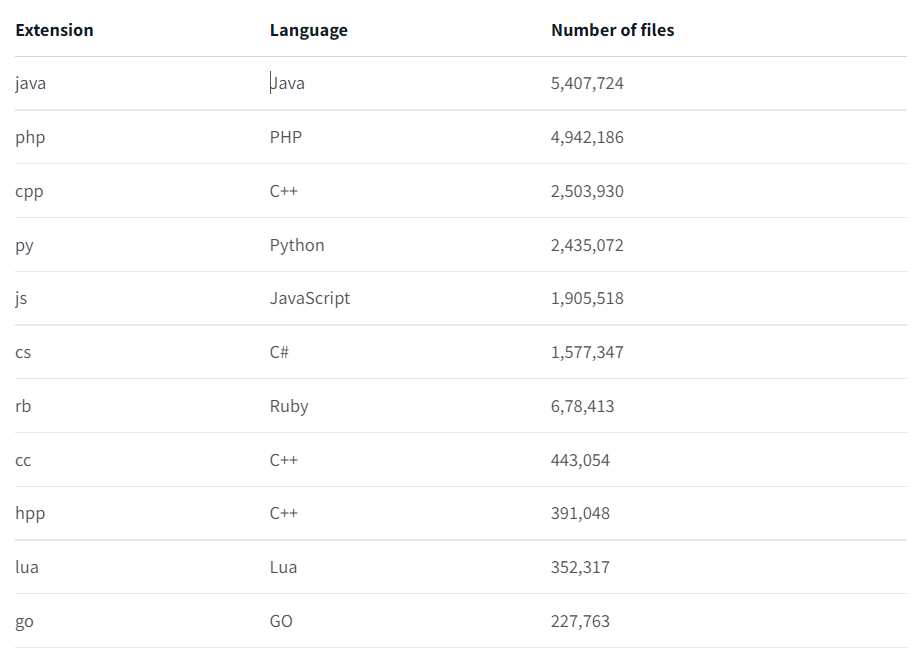
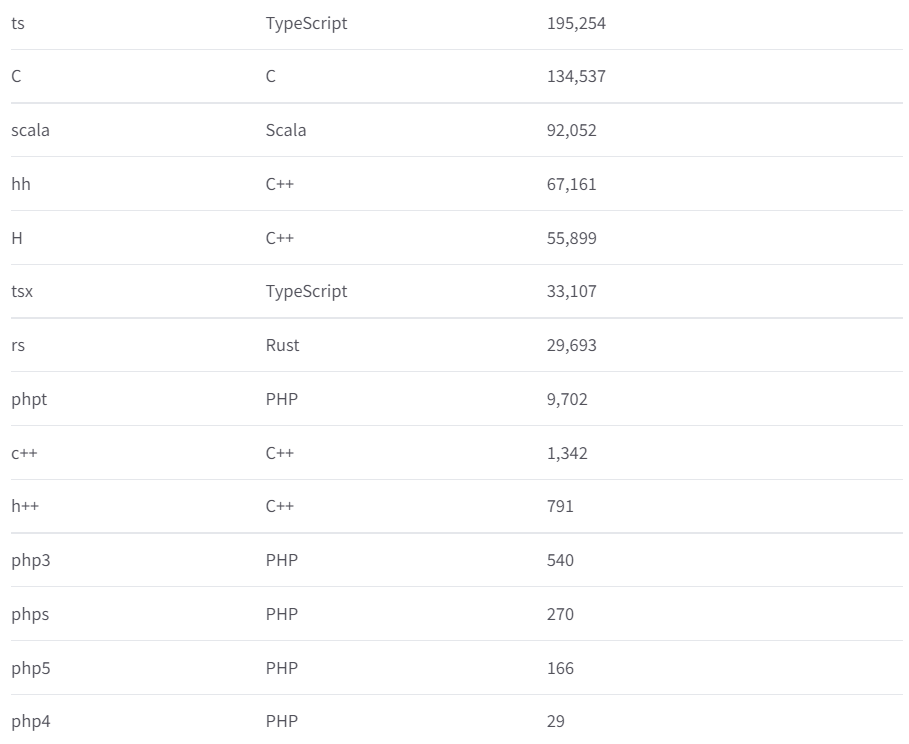
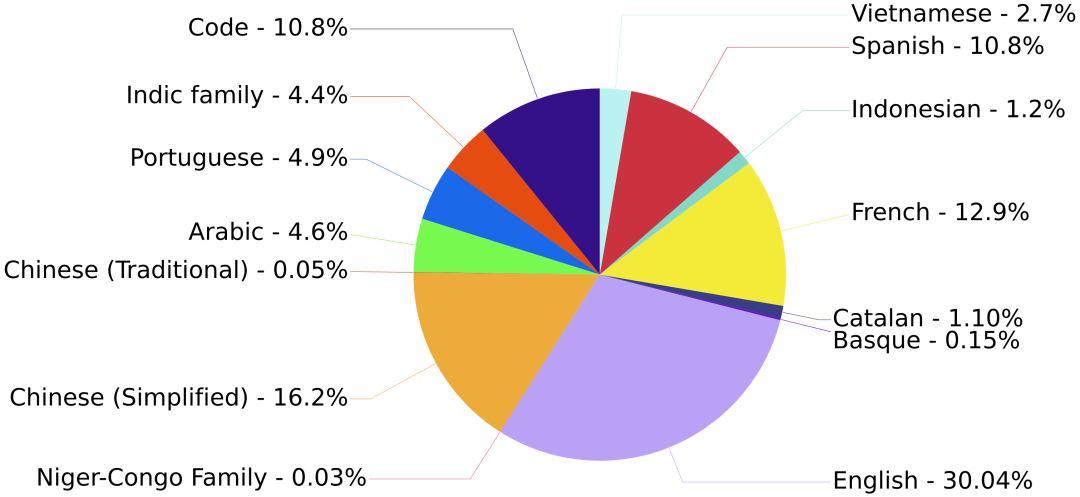
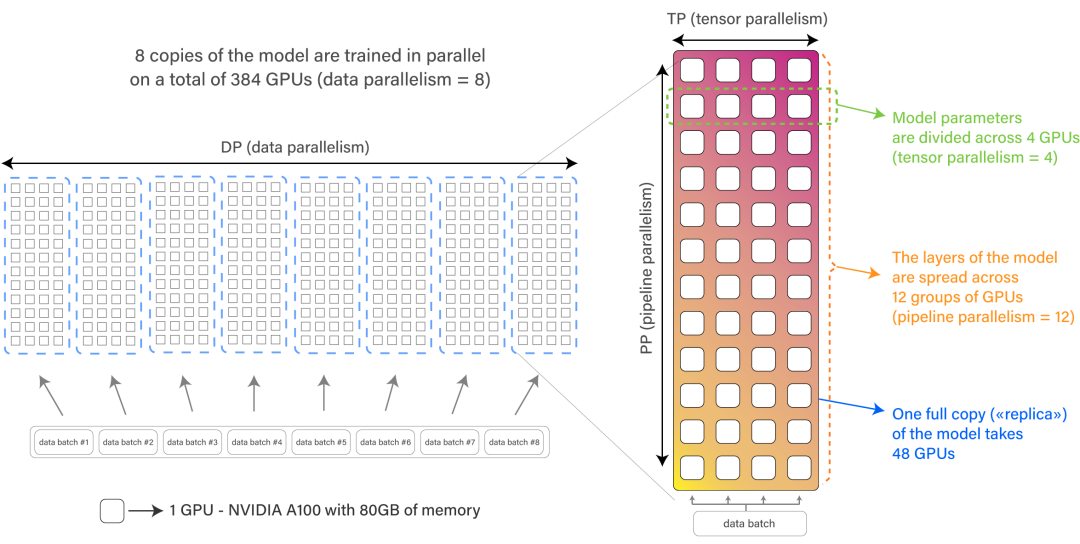




数据集:自己手搓的才靠谱

开源:但会随时调整


登录查看更多
相关内容

Arxiv
14+阅读 · 2021年2月14日
Arxiv
10+阅读 · 2019年9月15日



相关VIP内容
相关资讯
相关论文
Arxiv
14+阅读 · 2021年2月14日
Arxiv
10+阅读 · 2019年9月15日