快了一个0!Meta祭出150亿参数蛋白质大模型,碾压AlphaFold2
![]()
新智元报道
新智元报道
【新智元导读】Meta的蛋白质预测模型ESMFold来了!整整150亿参数,堪称又大又快又好。
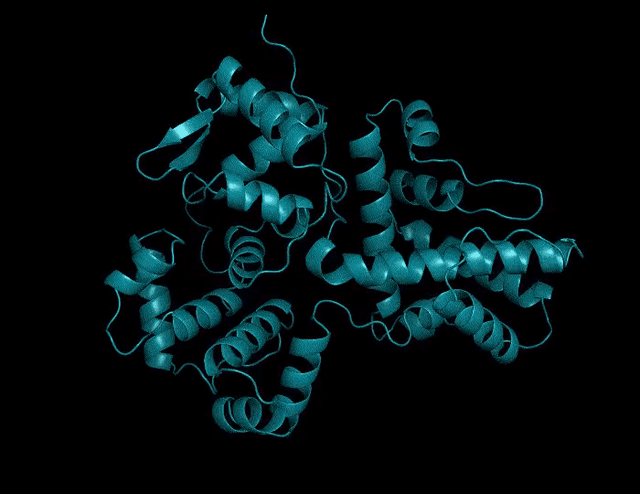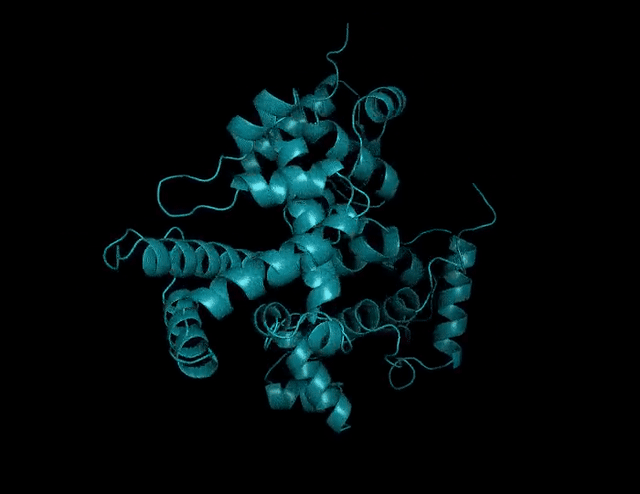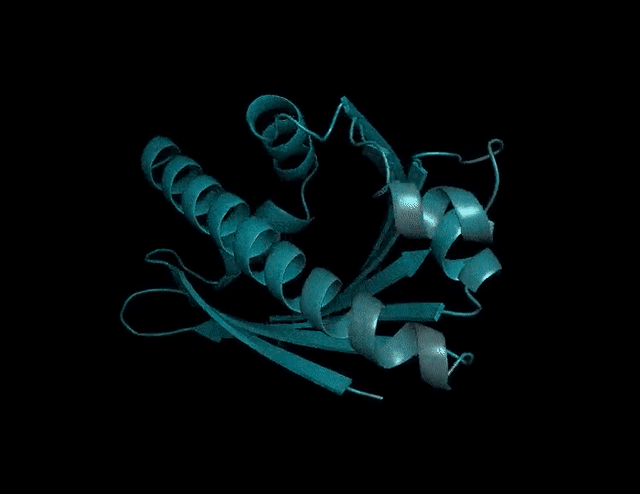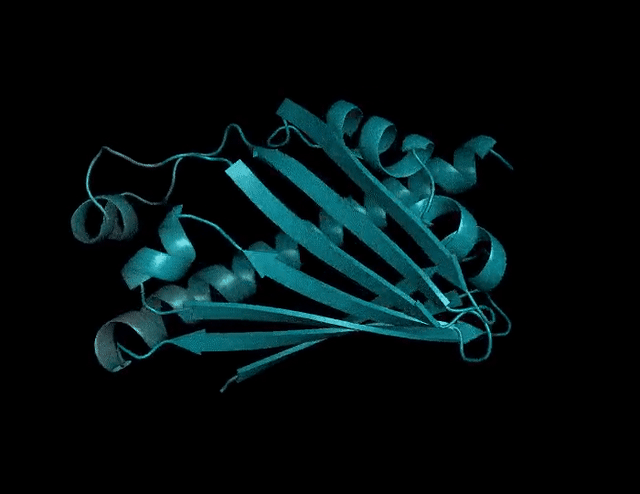

又大又快!

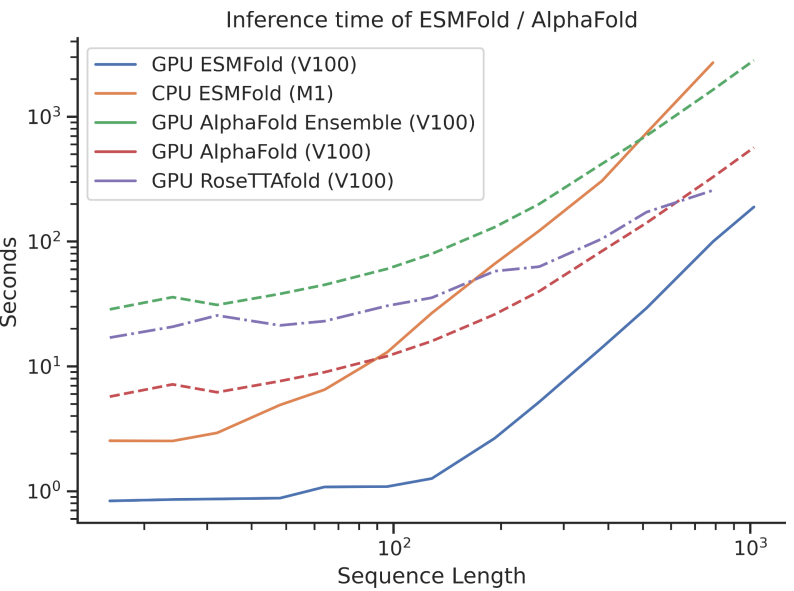
有啥区别?
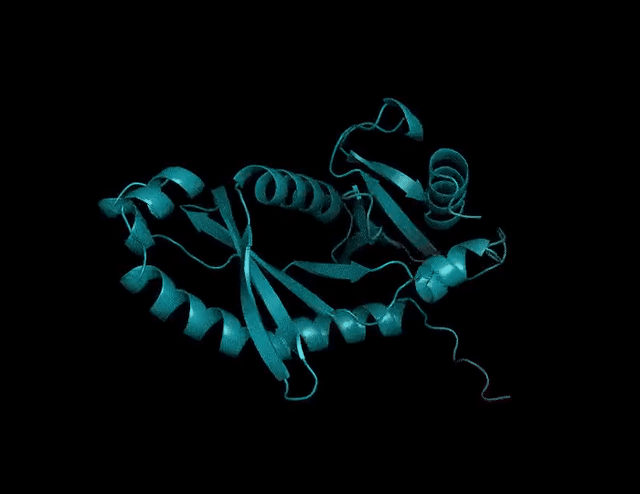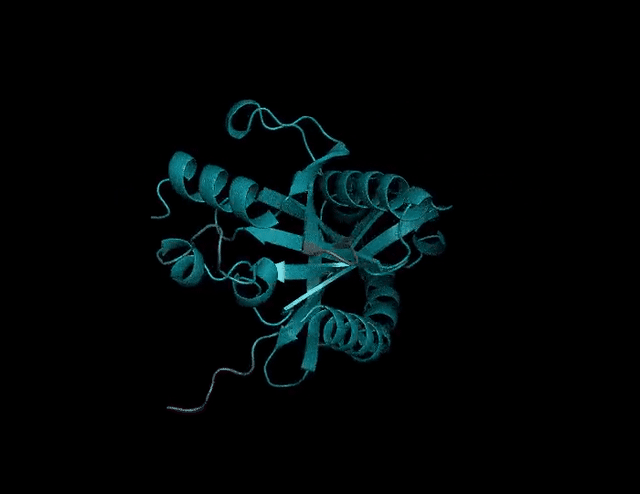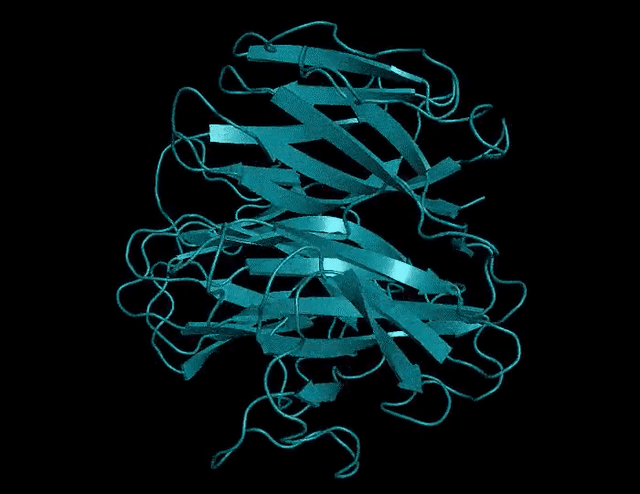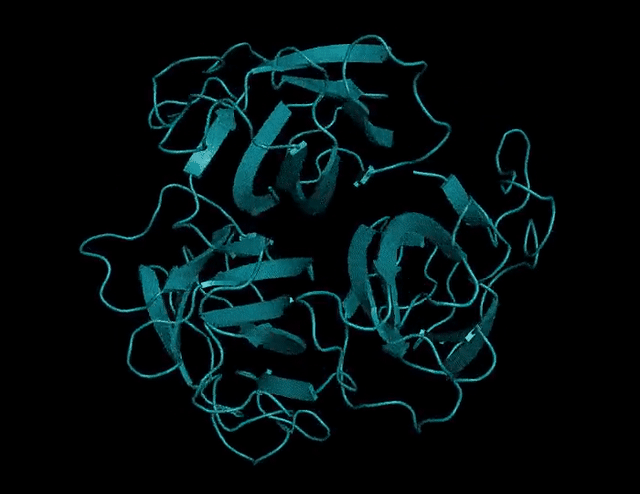
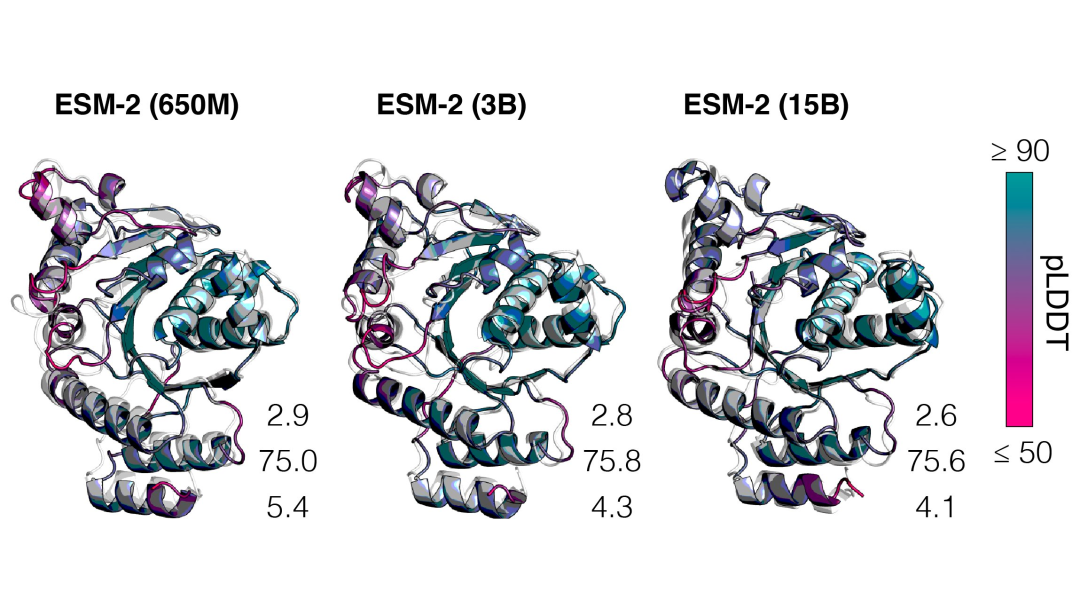
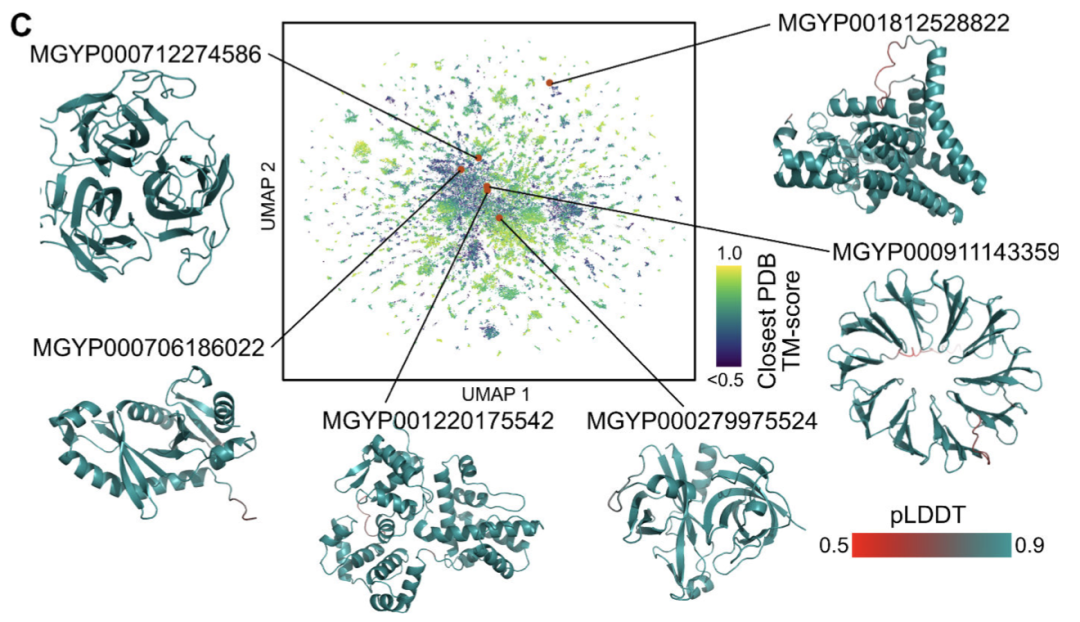
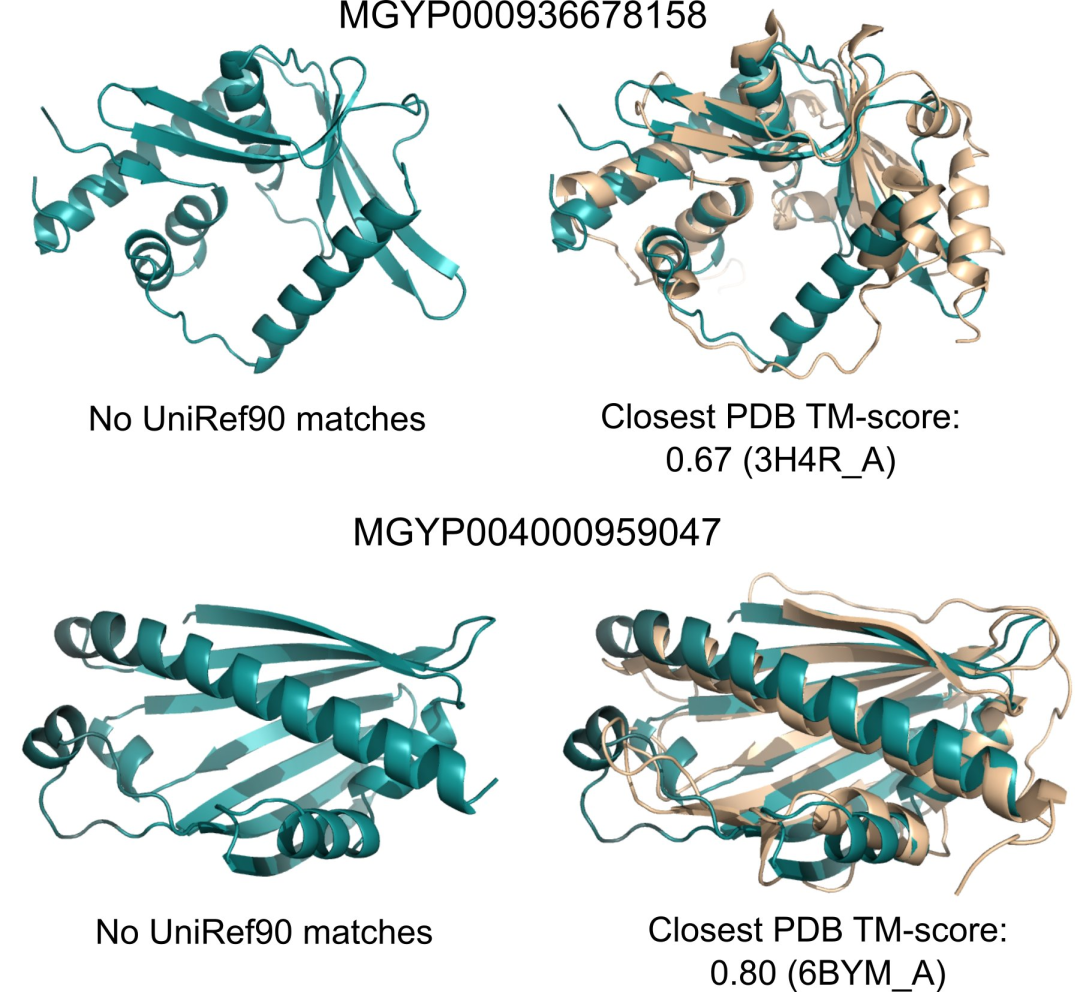
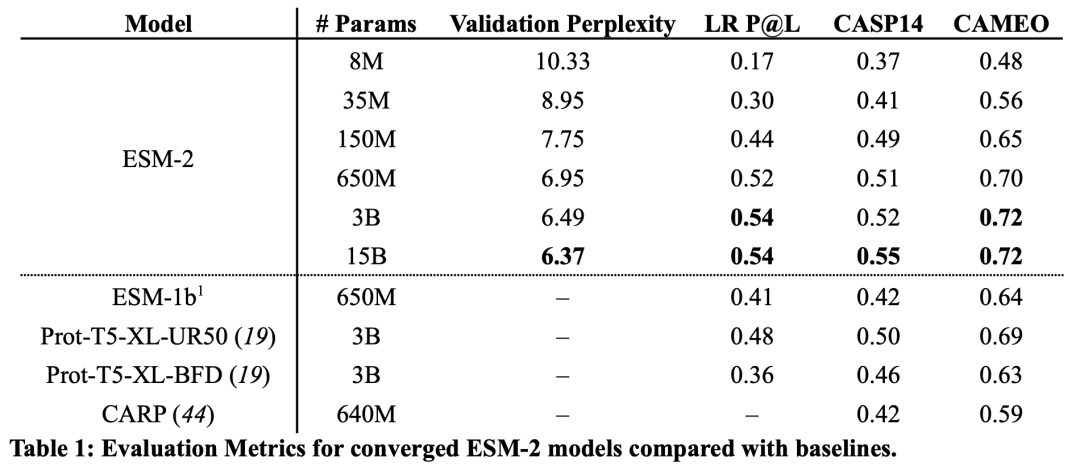
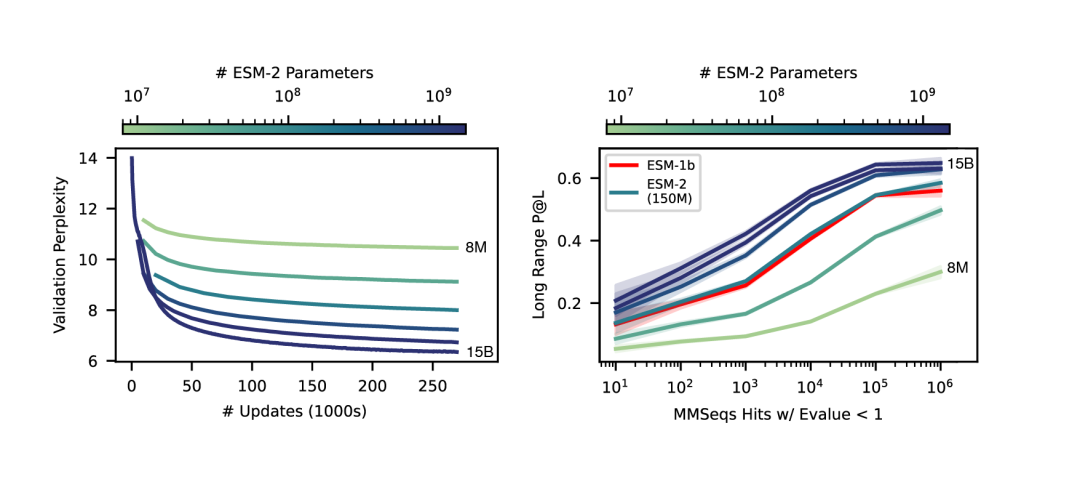
150亿参数的蛋白质语言模型
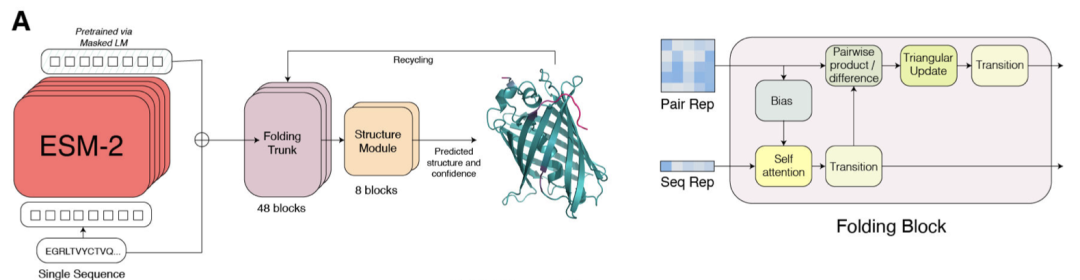
端到端的单序列结构预测
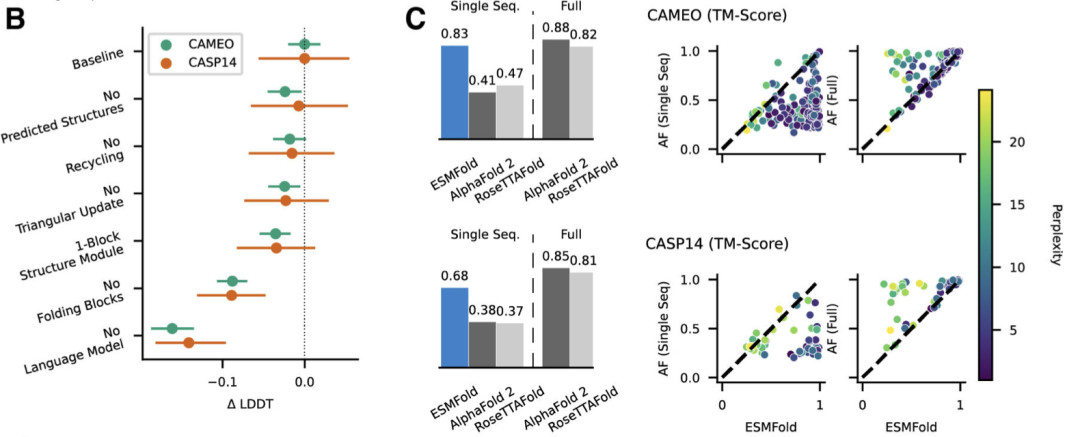
结论
作者介绍



登录查看更多
相关内容
专知会员服务
21+阅读 · 2022年3月14日
Arxiv
0+阅读 · 2022年9月19日


相关VIP内容
专知会员服务
21+阅读 · 2022年3月14日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月19日