机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括上海交大发布的医疗版 MNIST 数据集,以及陈丹琦在关系抽取方面的新探索。
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
A Survey on Multi-source Person Re-identification
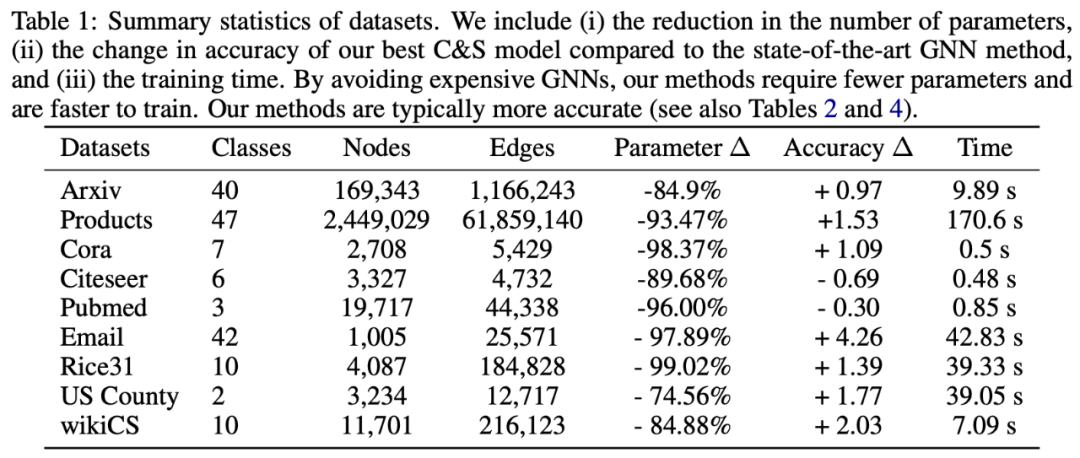
Combining Label Propagation and Simple Models out-performs Graph Neural Networks
A Frustratingly Easy Approach for Joint Entity and Relation Extraction
Self-training and Pre-training are Complementary for Speech Recognition
A Survey on Contrastive Self-supervised Learning
Image Sentiment Transfer
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
摘要:
在 AI 技术的发展中,数据集发挥了重要的作用。然而,医疗数据集的创建面临着很多难题,如数据获取、数据标注等。近期,
上海交通大学的研究人员创建了医疗图像数据集 MedMNIST,共包含 10 个预处理开放医疗图像数据集(其数据来自多个不同的数据源,并经过预处理)
。和 MNIST 数据集一样,MedMNIST 数据集在轻量级 28 × 28 图像上执行分类任务,所含任务覆盖主要的医疗图像模态和多样化的数据规模。
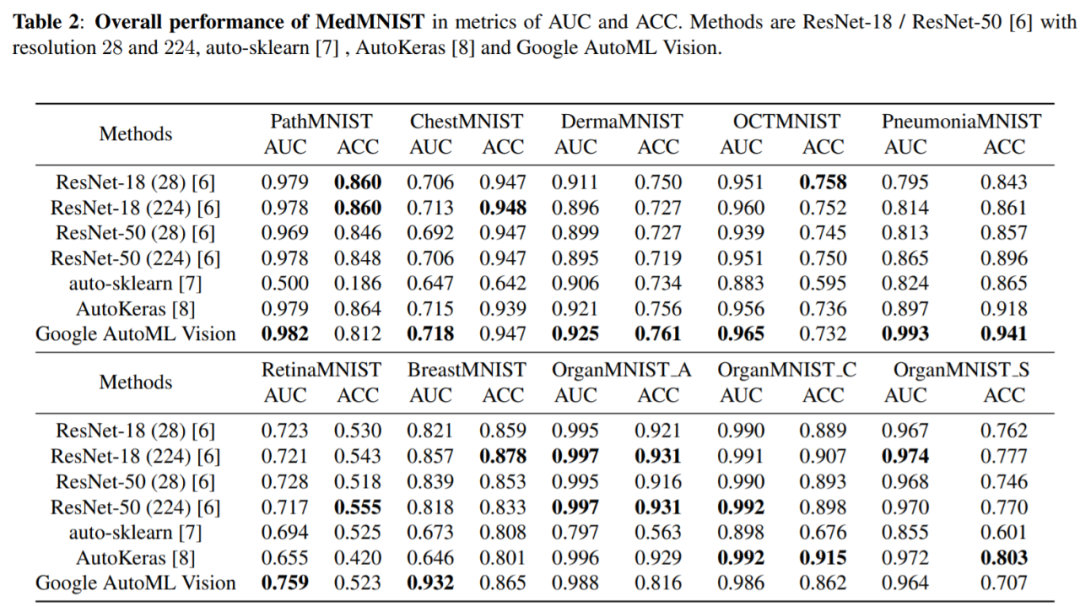
它在全部 10 个数据集上评估 AutoML 算法的性能,且不对算法进行手动微调。研究人员对比了多个基线方法的性能,包括早停 ResNet [6]、开源 AutoML 工具(auto-sklearn [7] 和 AutoKeras [8]),以及商业化 AutoML 工具(Google AutoML Vision)。研究人员希望 MedMNIST Classification Decathlon 可以促进 AutoML 在医疗图像分析领域的研究。
![]()
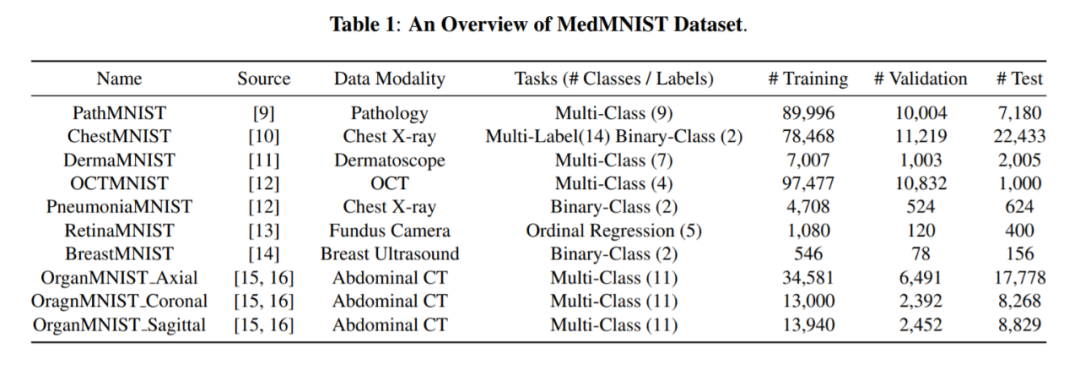
MedMNIST 数据集概览,涵盖数据集的名称、来源、数据模态、任务和数据集分割情况。
![]()
![]()
推荐:
上海交大研究人员创建新型开放医疗图像数据集 MedMNIST,并设计「MedMNIST 分类十项全能」,旨在促进 AutoML 算法在医疗图像分析领域的研究。
论文 2:A Survey on Multi-source Person Re-identification
摘要:
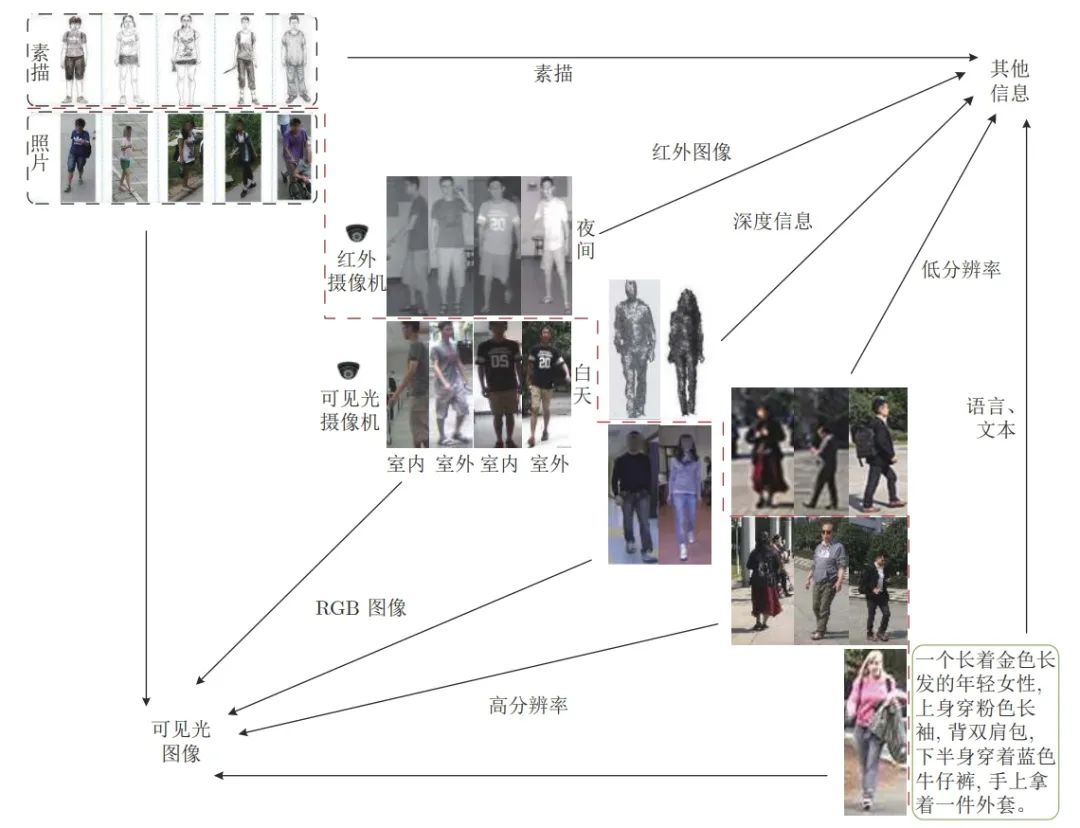
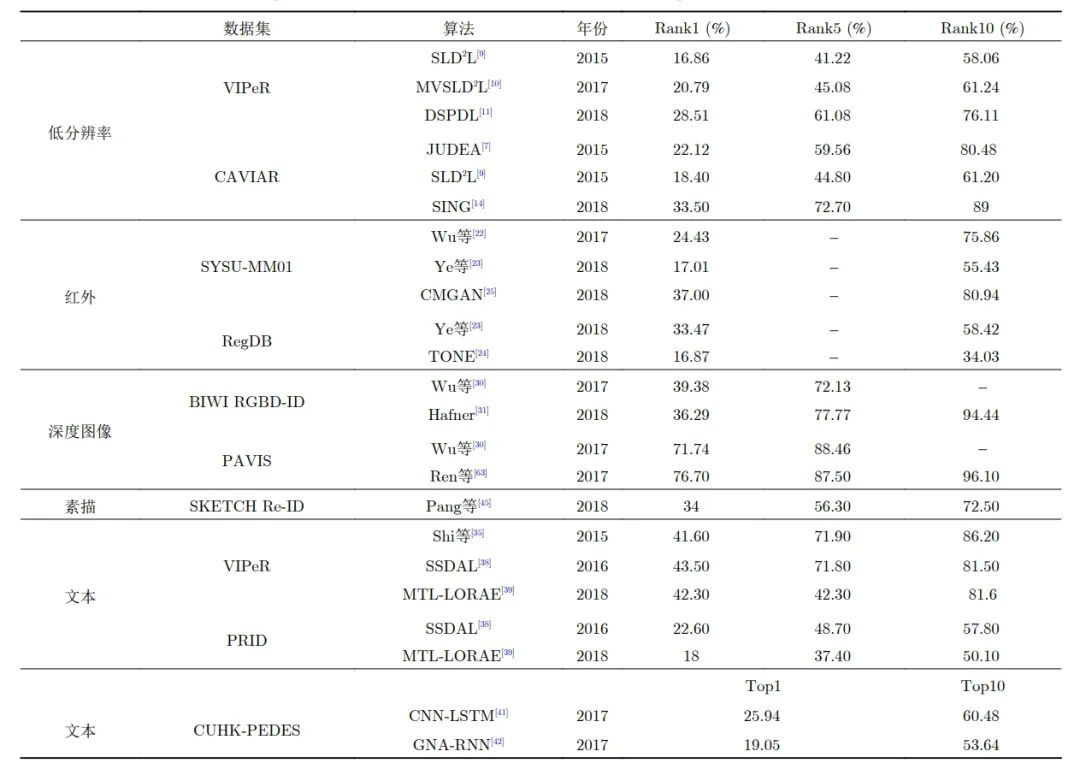
行人重识别是近年来计算机视觉领域的热点问题,经过多年的发展,基于可见光图像的一般行人重识别技术已经 趋近成熟。然而,目前的研究多基于一个相对理想的假设,即行人图像都是在光照充足的条件下拍摄的高分辨率图像。因此 虽然大多数的研究都能取得较为满意的效果,但在实际环境中并不适用。多源数据行人重识别即利用多种行人信息进行行 人匹配的问题。除了需要解决一般行人重识别所面临的问题外,多源数据行人重识别技术还需要解决不同类型行人信息与 一般行人图片相互匹配时的差异问题,如低分辨率图像、红外图像、深度图像、文本信息和素描图像等。因此,
与一般行人重 识别方法相比,多源数据行人重识别研究更具实用性,同时也更具有挑战性
。
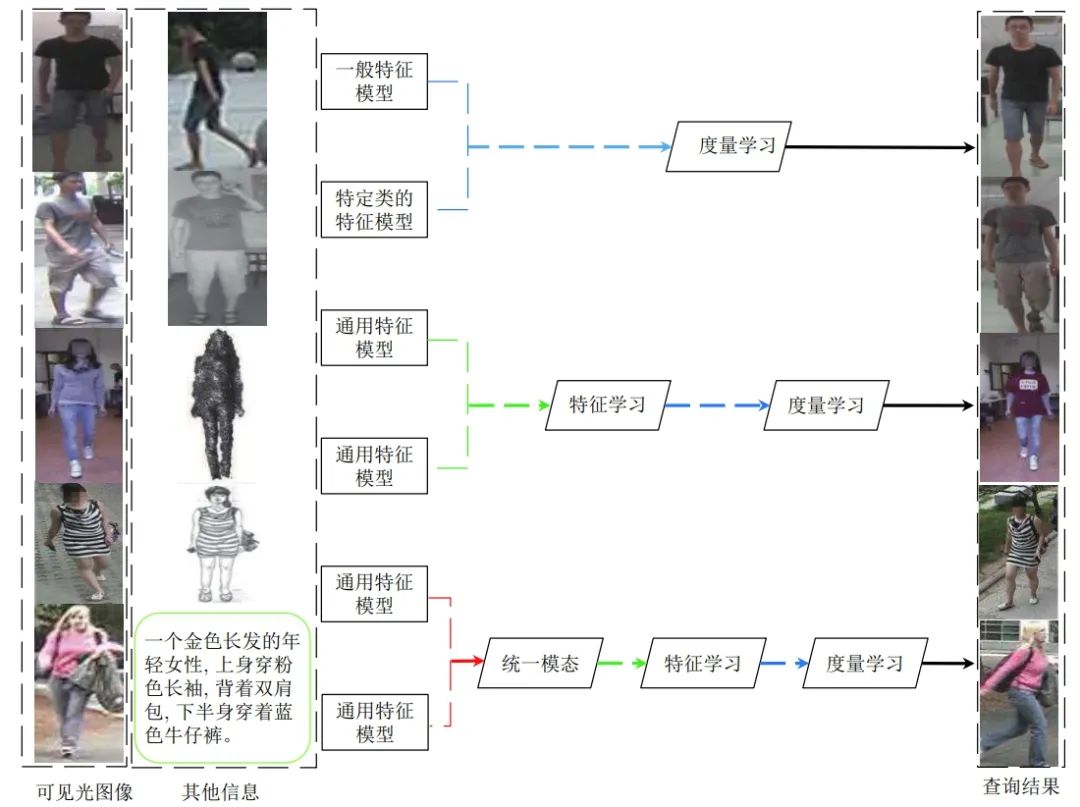
本文首先介绍了一般行人重识别的发展现状和 所面临的问题,然后比较了多源数据行人重识别与一般行人重识别的区别,并根据不同数据类型总结了 5 类多源数据行人 重识别问题,分别从方法、数据集两个方面对现有工作做了归纳和分析。与一般行人重识别技术相比,多源数据行人重识别 的优点是可以充分利用各类数据学习跨模态和类型的特征转换。最后,本文讨论了多源数据行人重识别未来的发展。
![]()
![]()
![]()
几种多源数据行人重识别方法在常用的行人数据集上的识别结果。
论文 3:Combining Label Propagation and Simple Models out-performs Graph Neural Networks
摘要:
图神经网络(GNN)是图学习方面的主要技术。但是我们对 GNN 成功的奥秘以及它们对于优秀性能是否必然知之甚少。近日,
来自康奈尔大学和 Facebook 的一项研究提出了一种新方法,在很多标准直推式节点分类(transductive node classification)基准上,该方法超过或媲美当前最优 GNN 的性能
。
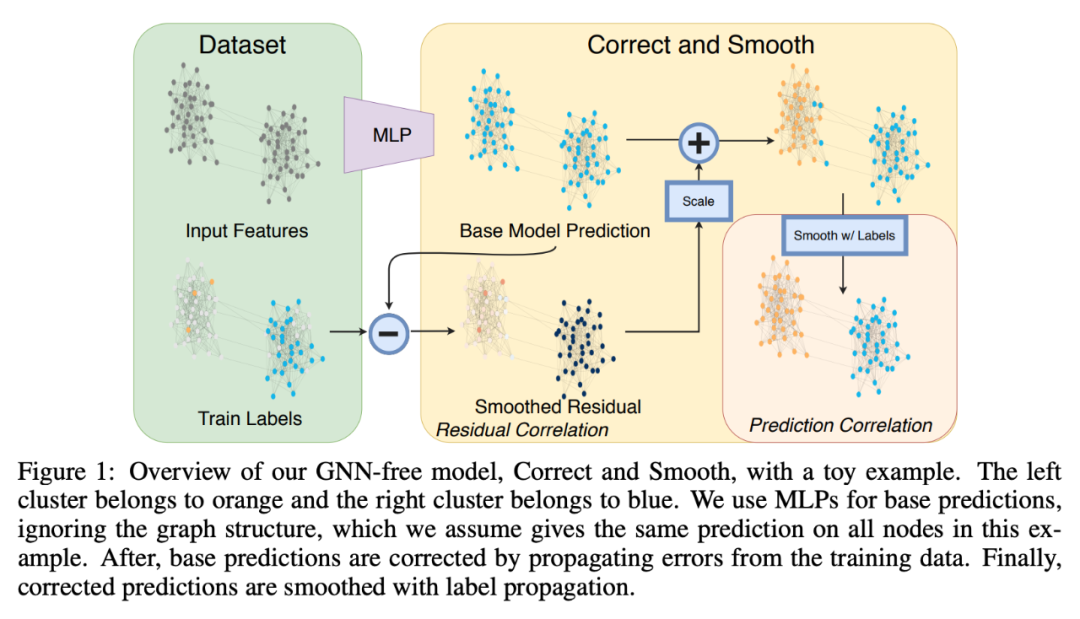
这一方法将忽略图结构的浅层模型与两项简单的后处理步骤相结合,后处理步利用标签结构中的关联性:(i) 「误差关联」:在训练数据中传播残差以纠正测试数据中的误差;(ii) 「预测关联」:平滑测试数据上的预测结果。研究人员将这一步骤称作 Correct and Smooth (C&S),后处理步骤通过对早期基于图的半监督学习方法中的标准标签传播(LP)技术进行简单修正来实现。
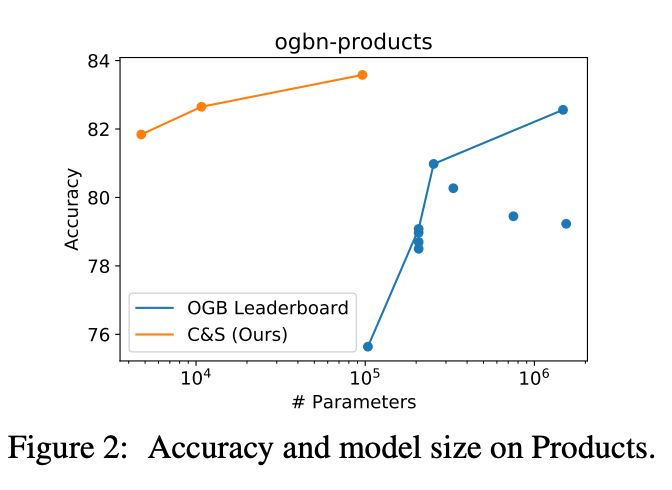
该方法在多个基准上超过或接近当前最优 GNN 的性能,而其参数量比后者小得多,运行时也快了几个数量级。例如,该方法在 OGB-Products 的性能超过 SOTA GNN,而其参数量是后者的 1/137,训练时间是后者的 1/100。该方法的性能表明,直接将标签信息纳入学习算法可以轻松实现显著的性能提升。这一方法还可以融入到大型 GNN 模型中。
![]()
![]()
![]()
OGB-Products 数据集上参数与性能(准确率)的变化曲线图。
推荐:
将传统标签传播方法与简单模型相结合即在某些数据集上超过了当前最优 GNN 的性能。
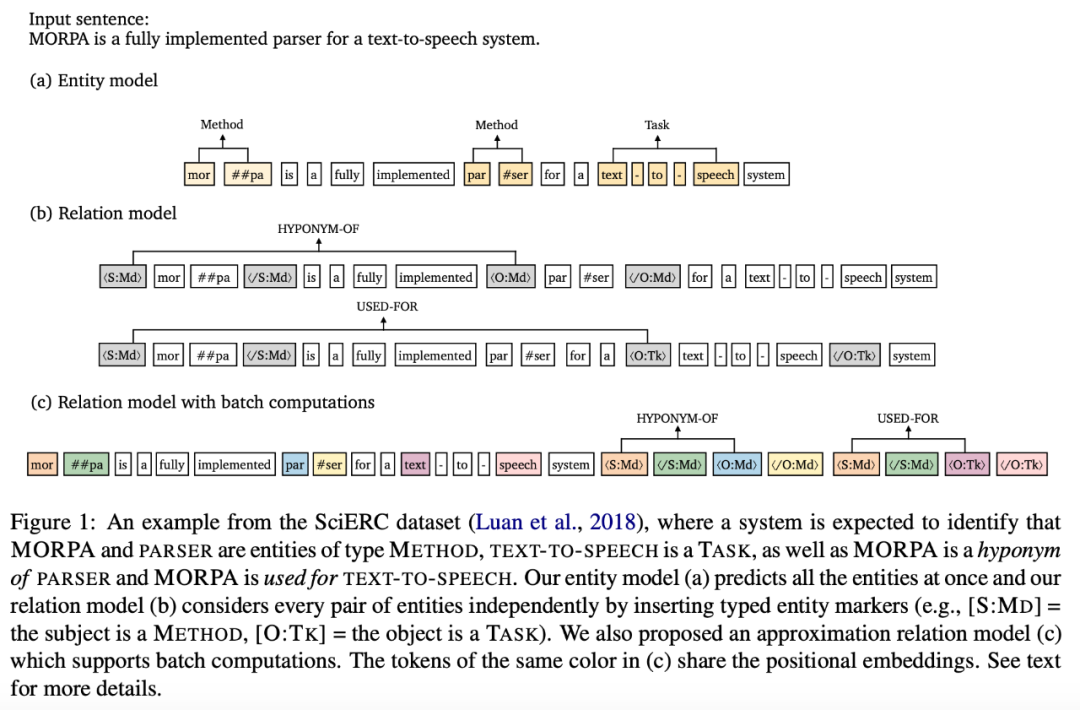
论文 4:A Frustratingly Easy Approach for Joint Entity and Relation Extraction
摘要:
端到端关系抽取旨在识别命名实体,同时抽取其关系。近期研究大多采取 joint 方式建模这两项子任务,要么将二者统一在一个结构化预测网络中,要么通过共享表示进行多任务学习。
而近期
来自普林斯顿大学的 Zexuan Zhong、陈丹琦介绍了一种非常简单的方法,并在标准基准(ACE04、ACE05 和 SciERC)上取得了新的 SOTA 成绩
。该方法基于两个独立的预训练编码器构建而成,只使用实体模型为关系模型提供输入特征。通过一系列精心检验,该研究验证了学习不同的语境表示对实体和关系的重要性,即在关系模型的输入层融合实体信息,并集成全局语境信息。
此外,该研究还提出了这一方法的高效近似方法,只需要在推断时对两个编码器各执行一次,即可获得 8-16 倍的加速,同时准确率仅小幅下降。
![]()
![]()
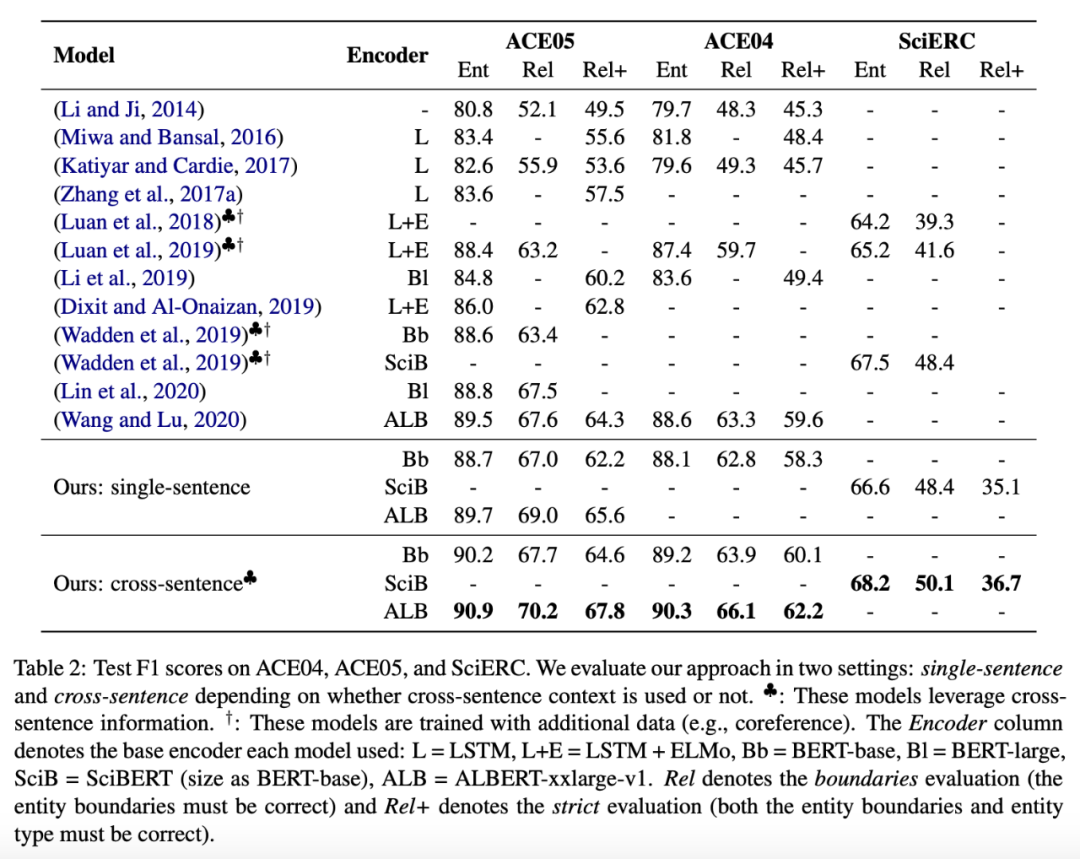
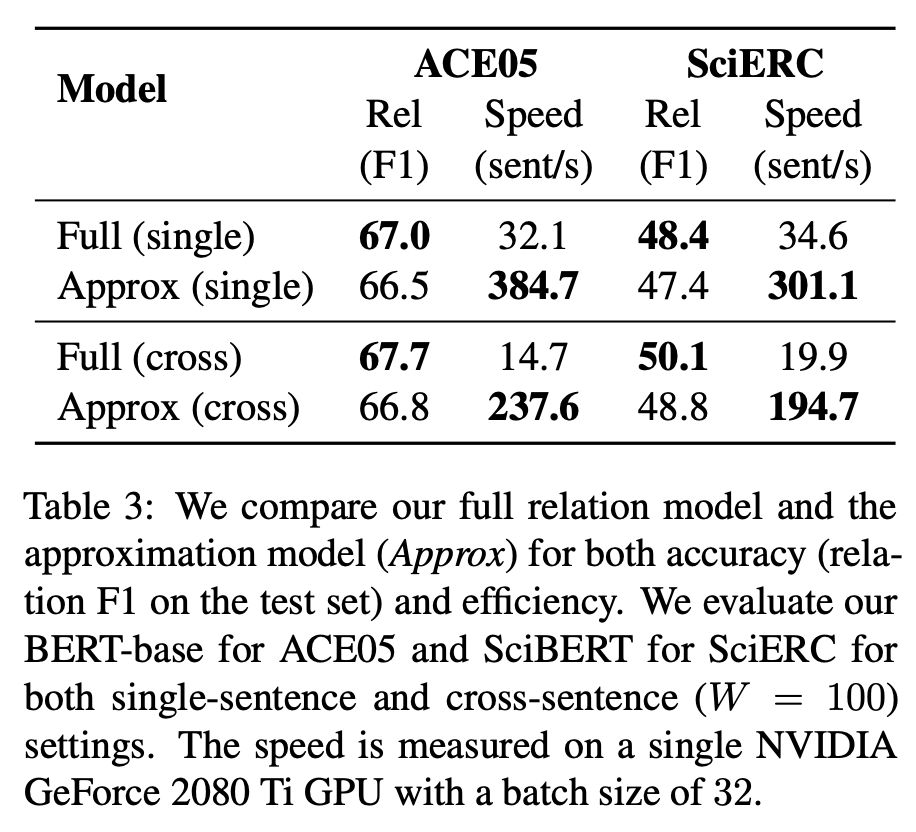
研究人员在三个端到端关系抽取数据集 ACE04、ACE054 和 SciERC 上进行方法评估,使用 F1 分数作为评估度量指标。不同方法的对比结果。
![]()
推荐:
端到端关系抽取任务中,pipeline 方法重回巅峰?
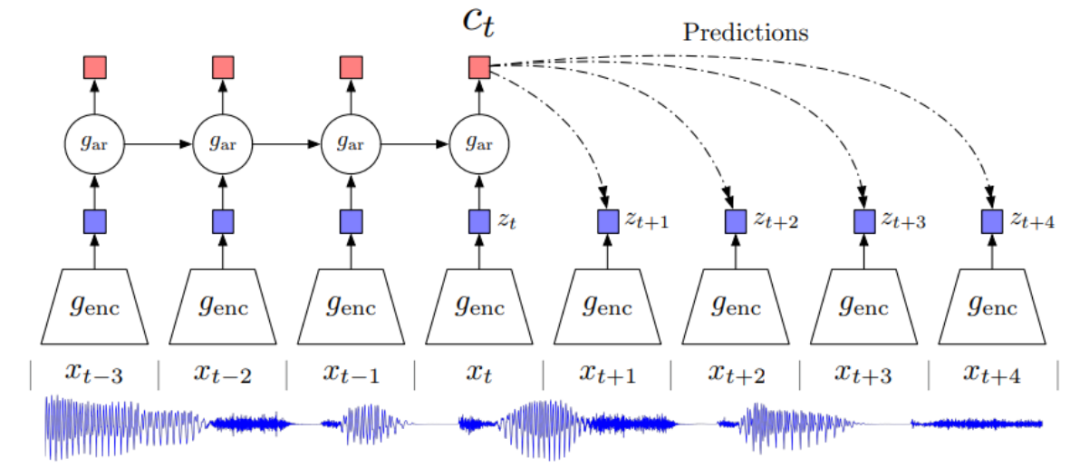
论文 5:Self-training and Pre-training are Complementary for Speech Recognition
摘要:
自训练和无监督预训练成为使用无标注数据改进语音识别系统的有效方法。但是,我们尚不清楚它们能否学习类似的模式,或者它们能够实现有效结合。
最近,
Facebook 人工智能研究院(FAIR)一项研究展示了,伪标注和使用 wav2vec 2.0 进行预训练在多种标注数据设置中具备互补性
。
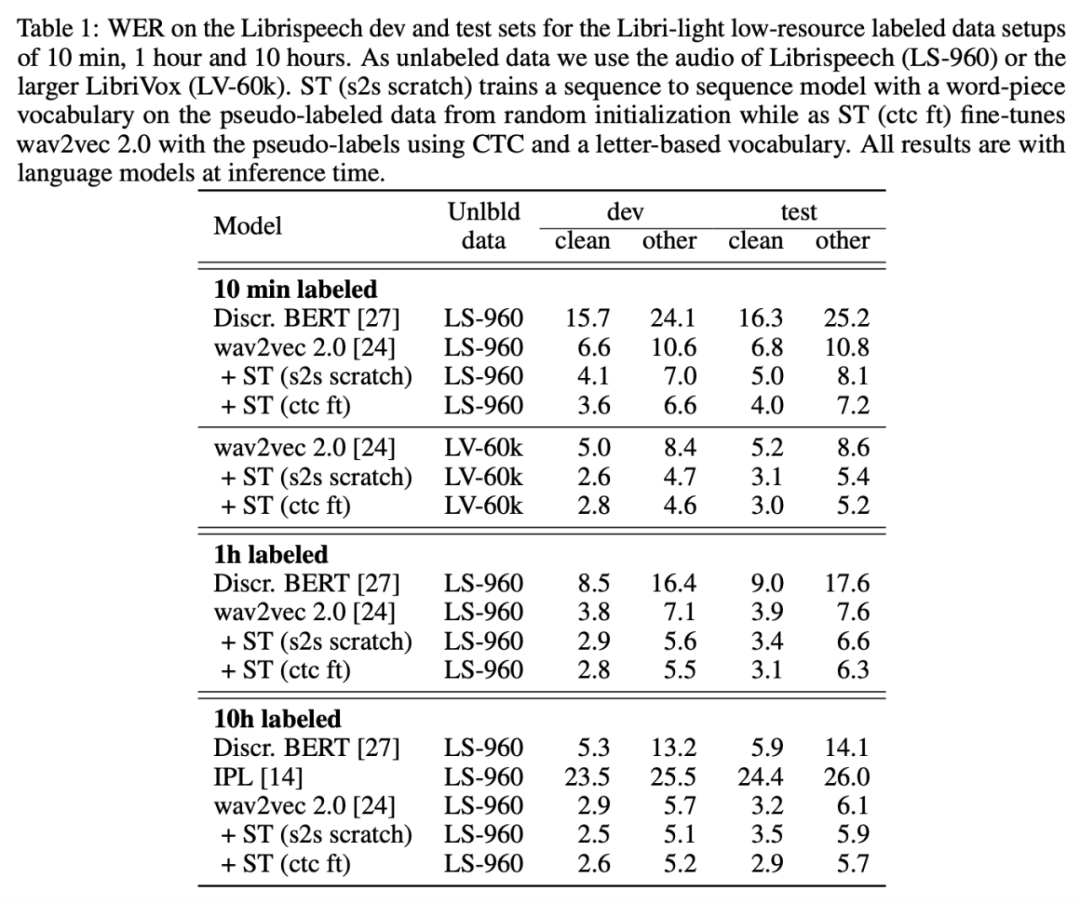
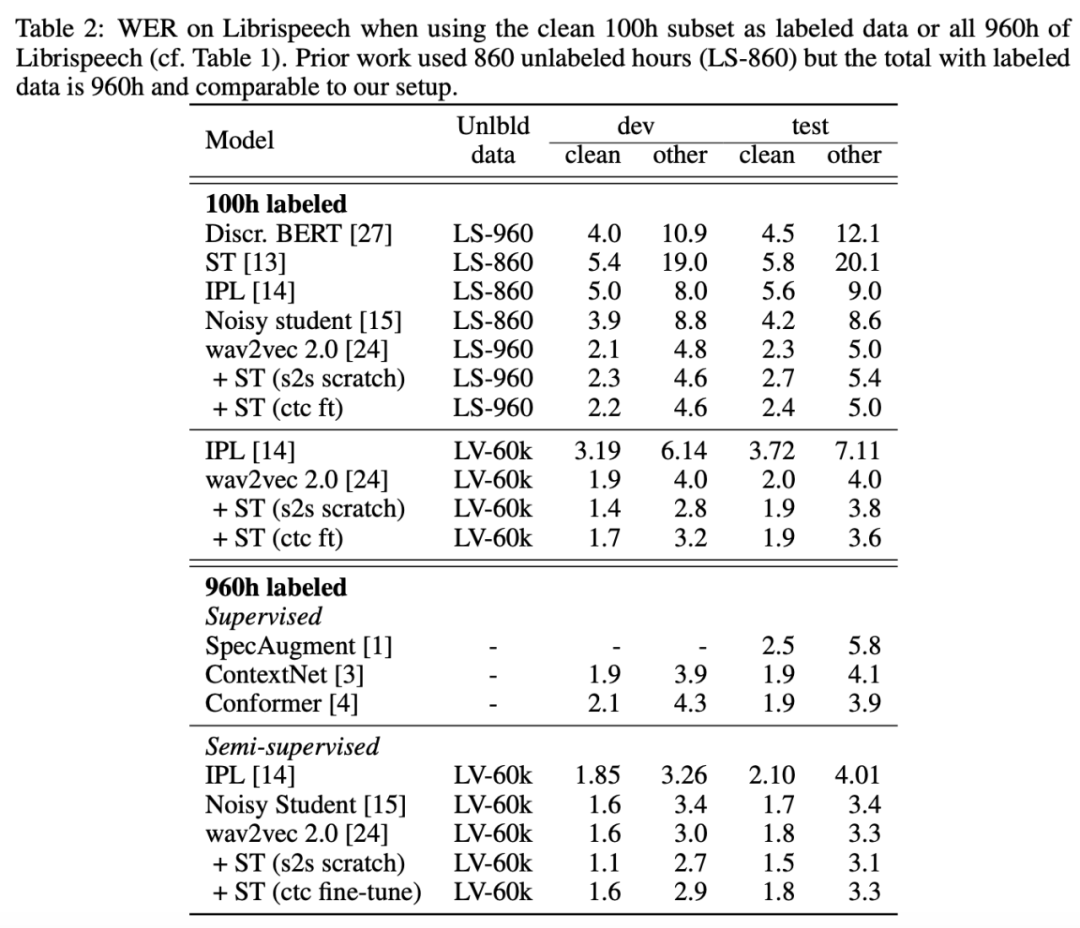
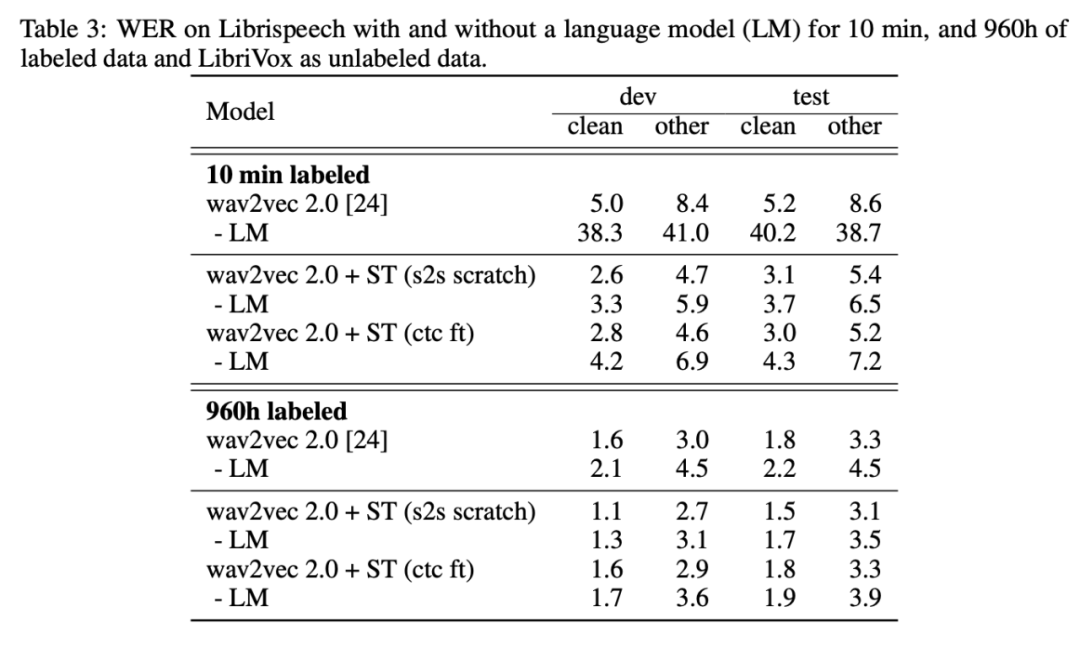
只需来自 Libri-light 数据集的 10 分钟标注数据和来自 LibriVox 数据集的 5.3 万小时无标注数据,该方法就能在 Librispeech clean 和 other 测试集上取得 3.0%/5.2% 的 WER(词错率),甚至打败了仅仅一年前基于 960 个小时标注数据训练的最优系统。在 Librispeech 所有标注数据上训练后,该方法可以达到 1.5%/3.1% 的词错率。
![]()
在所有低资源数据设置中,结合预训练和自训练 (wav2vec 2.0 + ST) 后的性能超过仅使用预训练 (wav2vec 2.0) 的性能。在 10h labeled 设置中,该方法相比迭代伪标注方法 [14] 有大幅提升。
![]()
在 100h labeled 设置下,LS-960 作为无标注数据时该研究提出的方法无法超过基线模型。但是使用更大规模的 LV-60k 作为无标注数据时,该方法性能有所提升,在 test-other 测试集上的词错率比 wav2vec 2.0 降低了 10%。
![]()
在没有语言模型的 10 min labeled 设置下这一效应尤其显著:在 test-other 数据集上,wav2vec 2.0 + ST (s2s scratch) 将基线方法 (wav2vec 2.0 - LM) 的词错率降低了 83%。
推荐:
来自 FAIR 的研究者提出结合自训练和无监督预训练执行语音识别任务,证明这两种方法存在互补性,并取得了不错的结果。
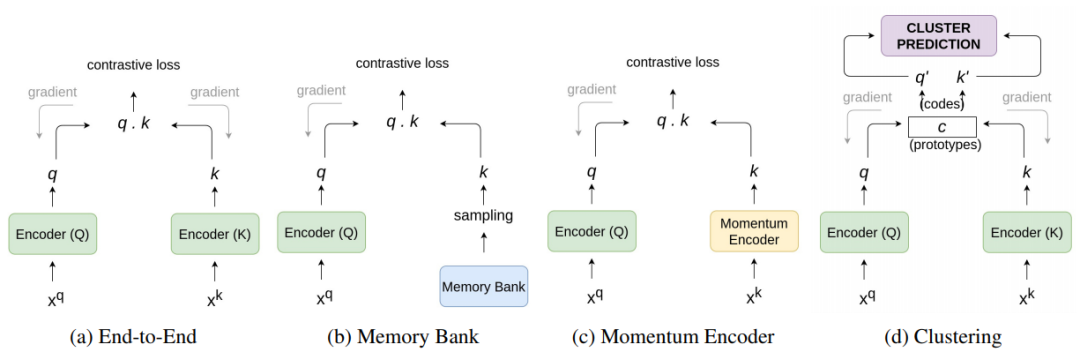
论文 6:A Survey on Contrastive Self-supervised Learning
摘要:
在本文中,来自
德州大学阿灵顿分校的研究者解释了对比学习设置中常用的自监督任务以及截止目前提出的不同架构
,然后对图像分类、目标检测和动作识别等多个下游任务的不同方法进行性能比较,最后总结了目前方法的局限性和未来的发展方向。
![]()
![]()
![]()
推荐:
论文一作 Ashish Jaiswal 为 UT Arlington 二年级博士生。
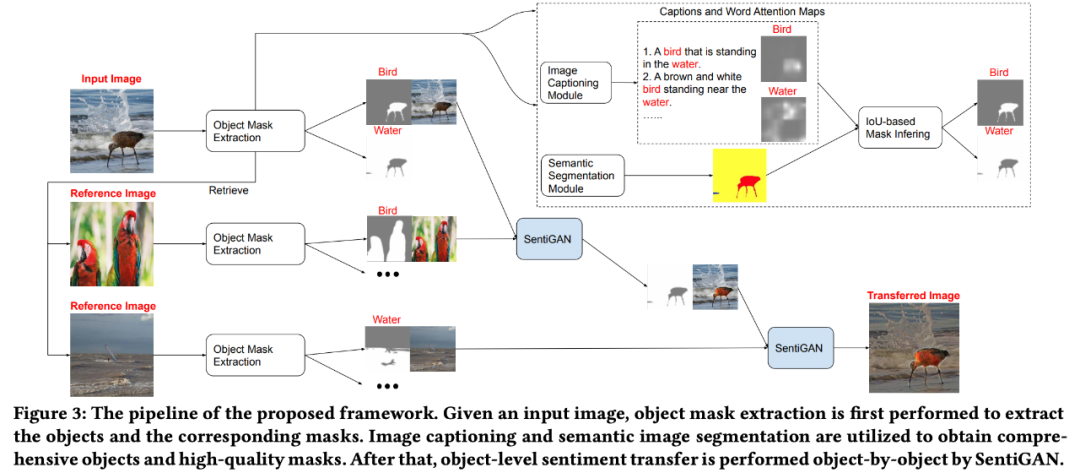
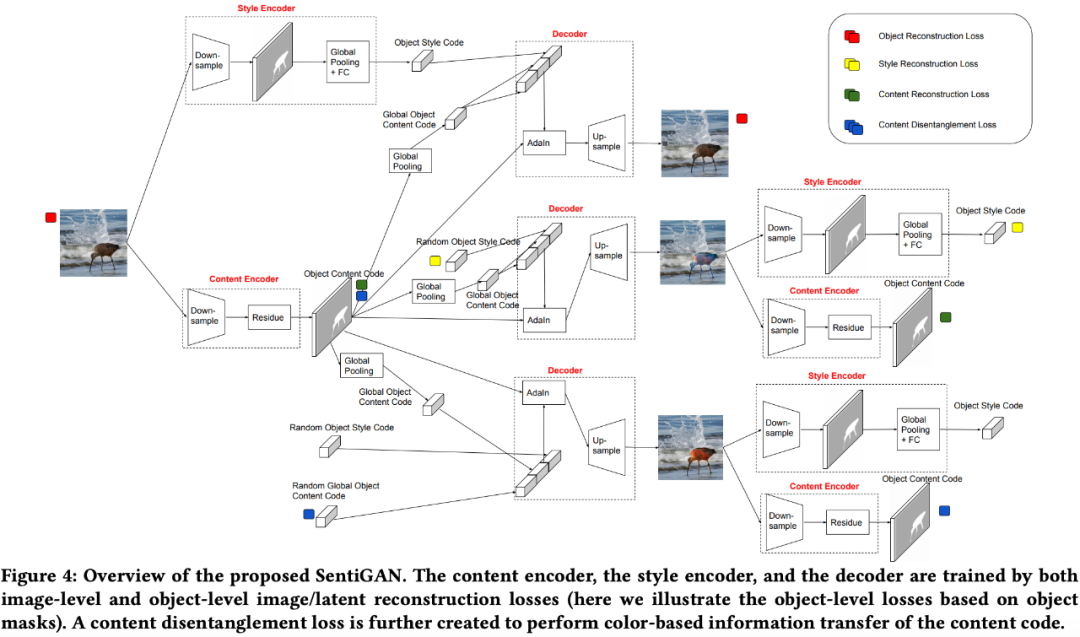
论文 7:Image Sentiment Transfer
摘要:
计算机视觉领域中有很多任务,如目标检测、图像转换、风格迁移等,但
你听说过「图像情感迁移」吗?罗切斯特大学罗杰波团队提出了这项研究任务
。与其他计算机视觉任务相比,图像情感迁移更有挑战性,需要对图像中的每个物体进行不同的情感迁移。该研究提出一种灵活有效的物体级图像情感迁移框架和新模型 SentiGAN,实验证明该框架可以有效执行物体级图像情感迁移。
![]()
![]()
![]()
推荐:
图像风格迁移?语音情感迁移?不,是图像情感迁移。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Semi-supervised Relation Extraction via Incremental Meta Self-Training. (from Philip S. Yu)
2. SLM: Learning a Discourse Language Representation with Sentence Unshuffling. (from Christopher D. Manning)
3. Phoneme Based Neural Transducer for Large Vocabulary Speech Recognition. (from Hermann Ney)
4. Topic-Preserving Synthetic News Generation: An Adversarial Deep Reinforcement Learning Approach. (from Huan Liu)
5. SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation. (from Philipp Koehn)
6. Cross-Domain Sentiment Classification With Contrastive Learning and Mutual Information Maximization. (from Kurt Keutzer)
7. Improving Event Duration Prediction via Time-aware Pre-training. (from Claire Cardie)
8. Automatic Detection of Machine Generated Text: A Critical Survey. (from Laks V.S. Lakshmanan)
9. Artificial Intelligence (AI) in Action: Addressing the COVID-19 Pandemic with Natural Language Processing (NLP). (from Zhiyong Lu)
10. Warped Language Models for Noise Robust Language Understanding. (from Dilek Hakkani Tür)
1. Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples. (from Elliot K. Fishman, Alan L. Yuille)
2. Learning unbiased registration and joint segmentation: evaluation on longitudinal diffusion MRI. (from Wiro J. Niessen, Meike W. Vernooij)
3. Learning a Generative Motion Model from Image Sequences based on a Latent Motion Matrix. (from Hervé Delingette, Nicholas Ayache)
4. Out-of-Distribution Detection for Automotive Perception. (from Roland Siegwart)
5. Can the state of relevant neurons in a deep neural networks serve as indicators for detecting adversarial attacks?. (from Tinne Tuytelaars)
6. End-to-end Animal Image Matting. (from Stephen J. Maybank, Dacheng Tao)
7. Muti-view Mouse Social Behaviour Recognition with Deep Graphical Model. (from Dacheng Tao, Xuelong Li)
8. Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers. (from Russell H. Taylor)
9. VEGA: Towards an End-to-End Configurable AutoML Pipeline. (from Tong Zhang)
10. A spatial hue similarity measure for assessment of colourisation. (from Paul F. Whelan)
1. Comprehensible Counterfactual Interpretation on Kolmogorov-Smirnov Test. (from Jian Pei)
2. Handling Missing Data with Graph Representation Learning. (from Jure Leskovec)
3. AgEBO-Tabular: Joint Neural Architecture and Hyperparameter Search with Autotuned Data-Parallel Training for Tabular Data. (from Isabelle Guyon)
4. Human versus Machine Attention in Deep Reinforcement Learning Tasks. (from Mary Hayhoe, Dana Ballard, Peter Stone)
5. Data Augmentation via Structured Adversarial Perturbations. (from Samy Bengio)
6. Autoencoding Features for Aviation Machine Learning Problems. (from Keith Campbell)
7. Towards a Unified Quadrature Framework for Large-Scale Kernel Machines. (from Johan A.K. Suykens)
8. Augmenting Organizational Decision-Making with Deep Learning Algorithms: Principles, Promises, and Challenges. (from Georg von Krogh)
9. ControlVAE: Tuning, Analytical Properties, and Performance Analysis. (from Tarek Abdelzaher)
10. Bayesian Variational Optimization for Combinatorial Spaces. (from Alán Aspuru-Guzik)
![]()