论文浅尝 | KnowEdu: 一个自动构建教育知识图谱的系统
笔记整理 | 崔凌云,天津大学硕士

链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8362657
动机
基于知识图的广泛应用和在教育领域日益增长的需求,作者提出了一个名为KnowEdu的系统,以自动构建教育知识图。通过利用教育领域的异构数据(如教学数据和学习评估数据),该系统首先提取科目或课程的概念,然后确定这些概念之间的教育关系。更具体地说,它在教学数据上使用神经序列标记算法来提取教学概念,并在学习评估数据上使用概率关联规则挖掘来识别具有教育意义的关系。
亮点
MCCF的亮点主要包括:(1)提出了一个新的和实用的系统来自动构建教育知识图,它利用异构数据,通常包括教学数据和学习评估数据,以提取教学概念和识别重要的教育关系;(2)考虑到教学概念的教育目的,作者建议将递归神经网络模型应用于教学数据(如递归神经网络模型)来完成教学概念提取任务。这是第一次将神经序列标记应用于教育领域的实体提取中的工作;(3)所期望的教育关系与可以从文本语料库中正确识别的通用知识图中的传统关系有很大上的区别。在这项工作中,作者特别利用了基于概念的学生评估数据,在其上执行概率关联规则挖掘来推断所需的关系;
概念及模型
KnowEdu系统层次结构主要由教学概念提取模块和教学关系识别模块两个模块组成过拟合问题并加速优化。
模型整体框架如下:
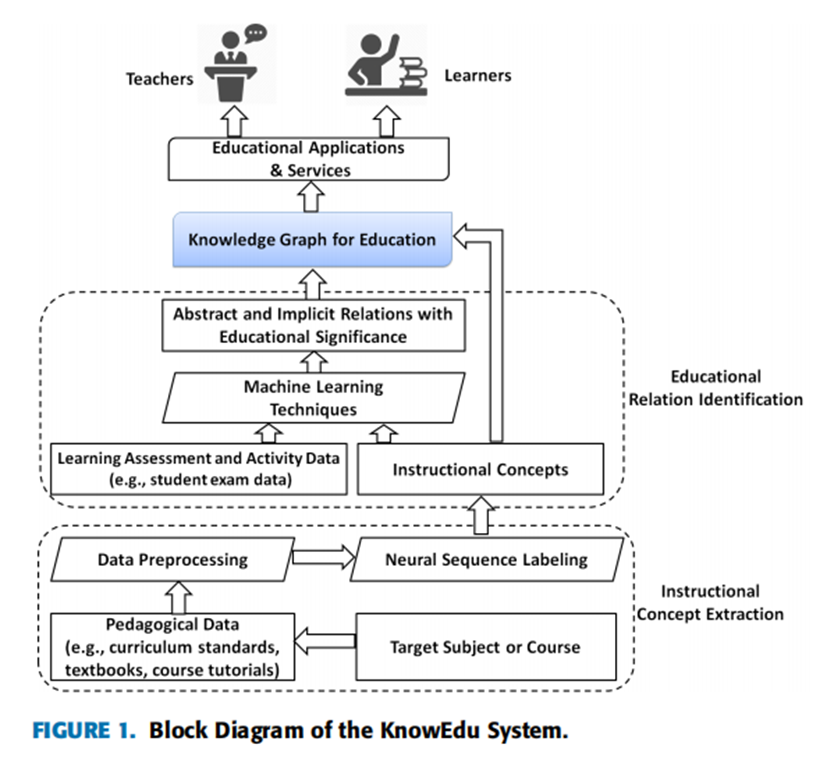
教学概念提取模块
本模块的主要目标是提取给定主题或课程的教学概念。本模块主要利用教学数据,通常包括课程标准、教科书和课程教程,这些数据通常是为了教学目的,并从教育领域收集。它们可能需要首先从打印的文档转换为机器可读的文本格式。在数据选择和格式转换后,可以部署命名实体识别技术,特别是神经序列标记来提取教学概念,该模块的关键输出是所提取的概念,它们是所构建的知识图的基石。
教育关系识别模块
本模块的主要目标是识别将教学概念互联的教育关系,以直接帮助学习和教学过程。由于教育关系更隐更抽象,本模块主要利用反映学习者认知和知识获取过程的学习评估和活动数据,采用最新的数据挖掘技术,如概率关联规则挖掘。最后,这些确定的关系将教学概念联系起来,以形成教育所需的知识图,可用于支持学习者和教师的各种应用和服务。
理论分析
实验
数据集和预处理程序
教学概念提取的数据集通常来自教学和教育来源,如课程标准、教科书和课程手册。这些材料通常被用作教学和教学实践的官方指导。作者选择了由中国教育部公布的国家中小学数学课程标准,作为主要的数据来源。
对于数据预处理步骤,系统首先使用Tika从课程标准的官方版本中提取文本,然后根据章节、段落和标点符号的特定符号进行句子分割,此外,非文本信息将自动删除图像和表的边界。随后,该系统利用一个中文分词的开源库进行分字。最后,从原始数据集中获得了1847个句子和36697个单词。
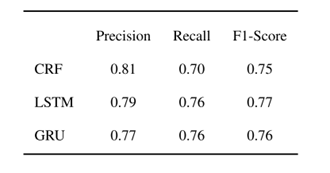
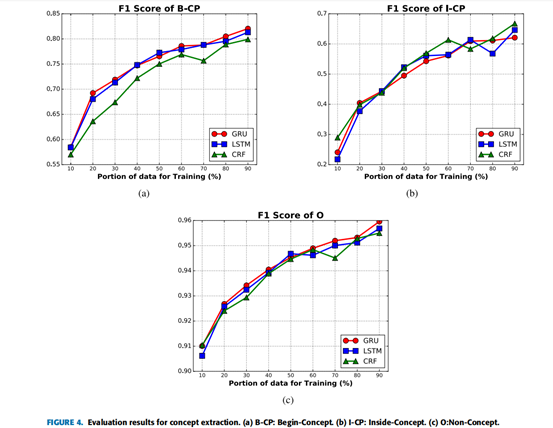
对概念提取的评价
为了获得模型评估的基本真相,作者邀请了北京师范大学两位参与起草国家课程标准的领域专家来标记所有的教学概念。共有4251个单词标记为B-CP,969个单词标记为I-CP。两位专家的标签与相应的kappa值为0.945。
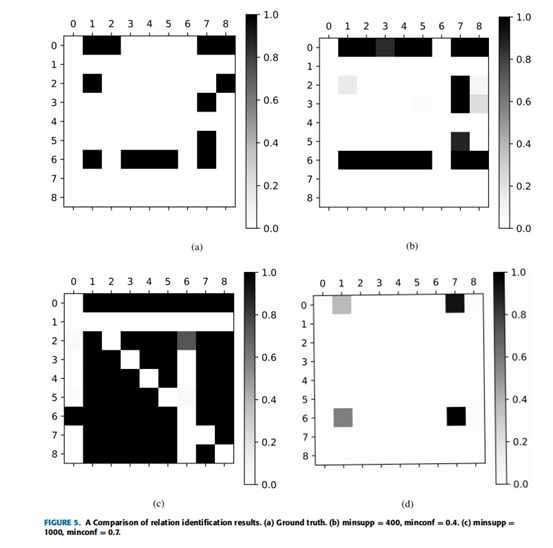
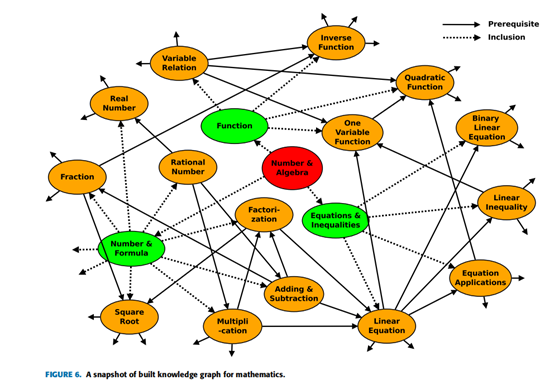
如果先决条件关系存在从概念A到概念B,我们称之为积极的关系,而如果没有先决条件关系,我们称之为负关系。只有当两个专家都注释它为正关系,并且kappa值为0.896时,才会确定正关系。
总结
我们介绍并实现了知识图系统,它可以自动构建教育知识图。它从异质数据源中提取教学概念和隐式教育关系,主要包括标准课程数据和学习评估数据。针对教学概念的提取,采用了神经网络模型,并针对前提关系的识别,引入了概率关联规则的挖掘。我们通过建立一个数学知识图来证明了该系统的前景,当50%的训练数据时,B-CP提取的F1分数超过0.75,AUC达到0.95。在更广泛的画布上,这个KnowEdu系统已经证明了为不同学科或课程自动构建专用知识图的可行性和有效性。各种个性化的教学和学习服务,如学习障碍的在线诊断和学习资源的智能推荐,可以使用这些个性化的知识图来开发,特别是针对下一代的MOOC平台。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


