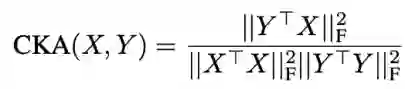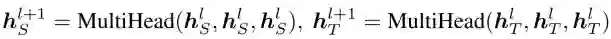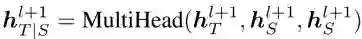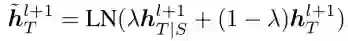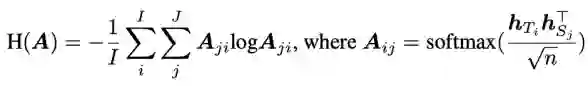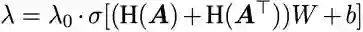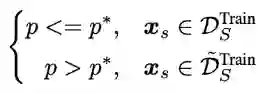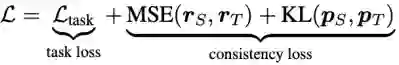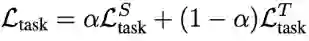字节跳动人工智能实验室、加利福尼亚大学圣塔芭芭拉分校
字节跳动人工智能实验室和加利福尼亚大学圣塔芭芭拉分校的研究者提出了跨语言流形混合(X-Mixup)方法为目标语言提供 “折衷” 的表示,让模型自适应地校准表示差异。此方法不仅显著地减少了跨语言表示差异,同时有效地提升了跨语言迁移的效果。
基于多语言预训练语言模型(比如 mBert、XLM-R 等),各种跨语言迁移学习方法取得了不错的迁移效果,但其中许多目标语言的性能仍然远远落后于源语言。字节跳动人工智能实验室和加利福尼亚大学圣塔芭芭拉分校通过分析发现这种跨语言性能差异和跨语言表示差异有很强的相关性,为了实现更好的跨语言迁移学习,本文提出了跨语言流形混合(X-Mixup)方法为目标语言提供 “折衷” 的表示,让模型自适应地校准表示差异。实验证明,X-Mixup 方法显著地减少了跨语言表示差异,同时提升了多个跨语言理解任务的性能。
![]()
深度模型在众多任务上取得了令人振奋的效果,但这些模型往往依赖足量的标注数据,这在多语言场景中很难满足。目前大部分标注数据通常来自流行语言(比如英文、中文等),很多小语种很难获取到足量的标注数据来进行有监督训练。跨语言迁移 (cross-lingual transfer) 可以从高资源的源语言 (source language) 迁移知识到低资源或零资源的目标语言 (target language),适用于当前标注资源不均衡的现状。
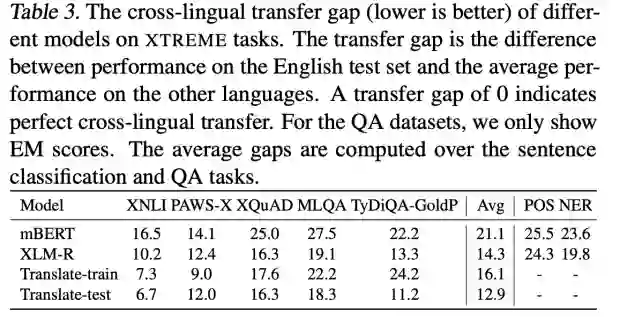
当前,多语言预训练模型基于不同语言的联合数据进行预训练,提供了不同语言统一的表示空间,在多种跨语言任务上取得了不错的效果。此外,Translate-train 方案从训练数据角度,通过机器翻译将源语言训练数据翻译到目标语言来构造伪标注数据,是一种简单有效的跨语言数据增强方案。Translate-test 方案从测试数据角度,直接将目标语言的测试集数据翻译到源语言,可以直接用源语言模型进行预测。尽管这些方案已经在跨语言迁移任务上取得了出色效果,但源语言和目标语言之间仍然有显著的性能差异。下表 [2] 展示了 XTREME 任务上基线模型在不同任务上的跨语言迁移性能差异 (cross-lingual transfer gap,源语言性能和目标语言平均性能差异) 。
![]()
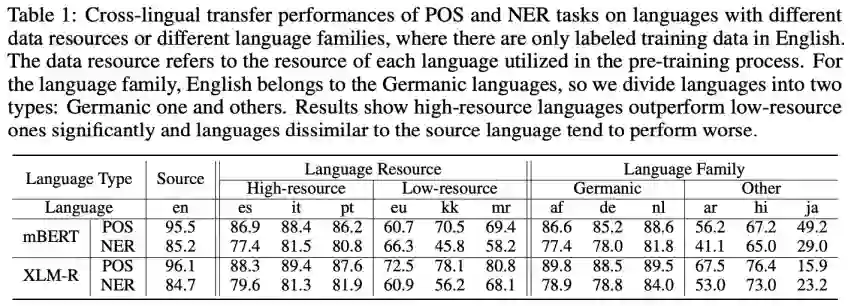
为了探究这种跨语言迁移性能差异的成因,本文首先对具体任务各语言的性能进行观察分析。Table 1 将语言按照预训练语言资源和语系进行了划分,结果表明:(1) 低资源语言性能远远落后于高资源语言;(2) 和源语言来自不同语系的语言性能远远落后于来自同一语系的语言。
![]()
在预训练过程中,由于训练数据的不平衡,高资源语言主导了表示学习过程,低资源语言表示往往不能被很好地训练[3][4]。此外,来自不同语系的语言常常表现出不同的语言特性(比如词表、词序等)。以上两者均会导致源语言和目标语言的表示差异。因此,作者尝试分析跨语言表示差异 (cross-lingual representation discrepancy) 和跨语言迁移效果的相关性。
本文使用 linear centered kernel alignment (CKA, [5]) 分数来度量跨语言表示差异,其中 X 和 Y 是来自源语言和目标语言的平行序列,更高的 CKA 分数意味着更小的跨语言表示差异。
![]()
Table 2 计算了在不同任务上跨语言迁移效果和跨语言表示差异的 Spearman 相关系数,Figure 3 展示了随着 CKA score 的下降,跨语言迁移的准确率有明显的下降趋势。以上相关系数和趋势都表明了跨语言迁移效果和跨语言表示差异有很强的相关性。
![]()
![]()
前面的分析提供了一个增强跨语言迁移效果的思路——减少跨语言表示差异。为了减少跨语言表示差异,一个直接的想法是在源语言表示和目标语言表示之间寻找折衷点。然而不同语言之间存在不同程度的差异,这个折衷点寻找起来相当困难。基于 Translate-train,可以得到源语言训练数据和对应的目标语言训练数据(翻译),基于 Translate-test,可以得到目标语言测试数据和源语言测试数据(翻译),这种成对的序列往往含有相同的语义,为折衷点的寻找提供了可能。Mixup [7][8] 通过对表示空间线性插值来获得中间表示,是一种流行的数据增强方案,同时,这种方法也提供了一种减少表示差异的直接思路。
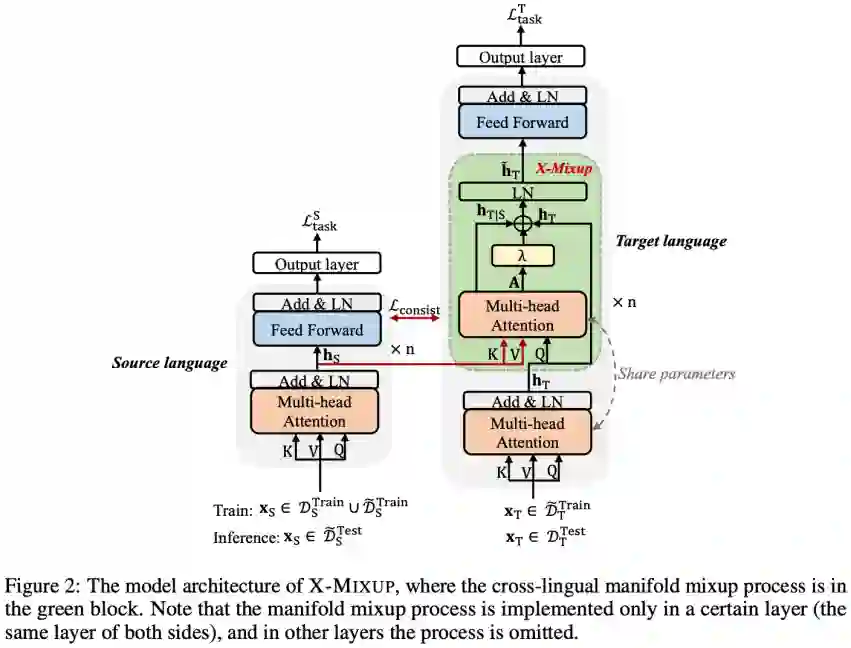
基于以上分析,本文提出 Cross-lingual Manifold Mixup (X-Mixup) 方案,通过跨语言流形混合为目标语言构造 “折衷” 的表示,从而直接减少跨语言表示差异,进而提升跨语言迁移效果。模型的整体框架见 Figure 2,左边为源语言的 encoder,右边为目标语言的 encoder,X-Mixup 过程主要在绿色部分实现。
![]()
X-Mixup 以 mBERT 和 XLM-R 为基线模型。其中,每层 encoder 都有两个子层:multi-head attention 层和 feed-forward 层(在以下公式中为了简便省略了 feed-forward 层)。S 表示源语言序列,T 表示目标语言序列,MutiHead 函数表示 multi-head attention 层,其中的三个输入分别为 query,key 和 value。在第 l+1 层,源(语言)序列和目标(语言)序列的隐层表示为:
![]()
为了从源序列的隐层表示中获取目标序列相关信息,本文把目标序列的隐层表示作为 query,源序列的隐层表示作为 key 和 value,整个过程为:
![]()
流形混合过程基于 mixup ratio lambda 来混合目标语言相关的两个表示:
![]()
问题 1:机器翻译在一些语向上性能不佳,导致翻译过程引入了不同程度的噪声。
解决方案:引入翻译质量建模到 X-Mixup 过程中来缓解数据噪声问题,基于注意力熵 [8] 来得到 mixup ratio:
![]()
![]()
问题 2:在训练和预测过程中,源语言序列来自不同的数据分布。在训练中,源语言序列为真实文本,而在预测中,源语言序列为翻译文本。
解决方案:在训练过程中对源语言序列进行动态采样 (Scheduled Sampling [9]) ,以概率 p 来选择从真实文本还是翻译文本中采样源语言序列,p * 在训练过程中逐渐减小以适应预测场景:
![]()
整体的损失函数包含两部分:任务损失 (task loss) 和一致性损失 (consistency loss),前者为源语言序列和目标语言序列的任务损失之加权和,后者为表示一致损失和预测结果一致损失之和,其中仅分类任务有预测结果一致损失。
![]()
![]()
本文在 XTREME 数据集上对 X-Mixup 的效果进行验证。XTREME 数据集包含分类、结构化预测、QA 等跨语言理解任务,覆盖了 40 种语言。
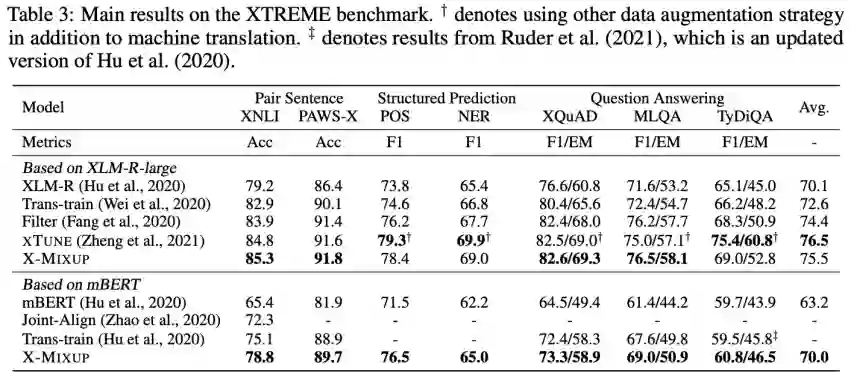
1. 相比 Translate-train,X-Mixup 显著地提升了各跨语言迁移任务的效果。
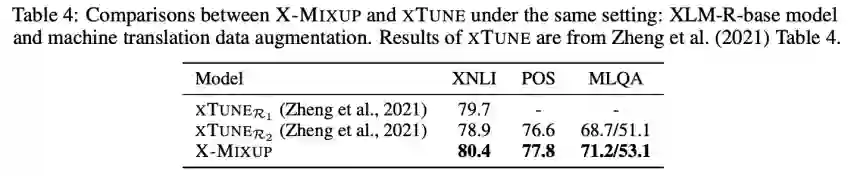
2.X-Mixup 取得了 XTREME 七个任务中四个任务的最好效果 (Table 3)。其中,相关工作 XTUNE 使用了除 translate-train 外的其他三种跨语言数据增强方法,在 translate-train 相同设定中,X-Mixup 优于 XTUNE (Table 4)。
![]()
![]()
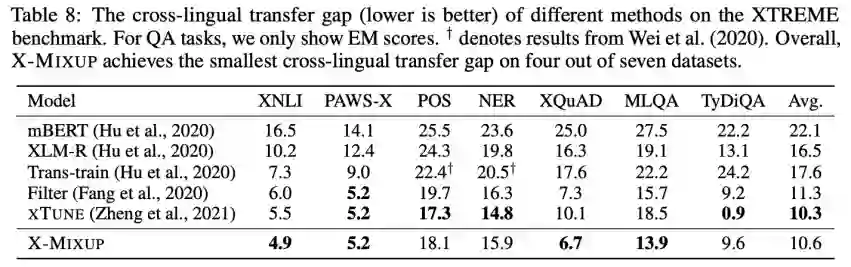
Table 8 展示了各方法的跨语言迁移性能差异,其中 TyDiQA 为低资源 QA 任务(源语言训练数据仅 3696 条),XTUNE 提出的跨语言数据增强方案十分有效。在分类任务 XNLI、PAWS-X,QA 任务 XQuAD、MLQA 上,X-Mixup 的跨语言迁移性能差异最小。
![]()
Figure 1 对 en、es、ar、sw 四种语言的句子表示进行了可视化,结果表明 X-Mixup 有效地减少了目标语言(低资源语言 sw、源语言不相似的语言 ar)和源语言的表示差异。
![]()
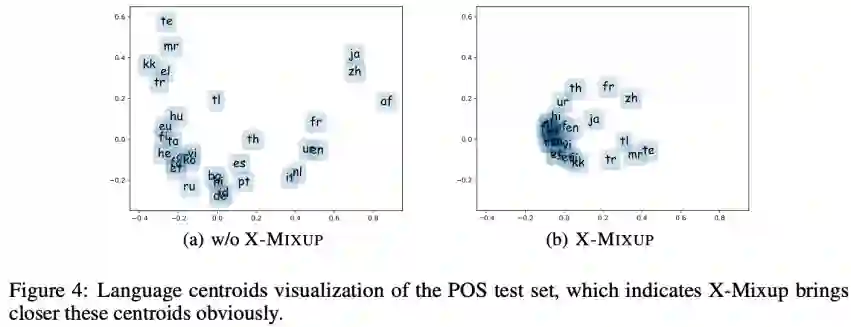
Figure 4 对各语言的 centroid(表示均值)进行了可视化,结果表明 X-Mixup 显著地减少了跨语言表示差异。
![]()
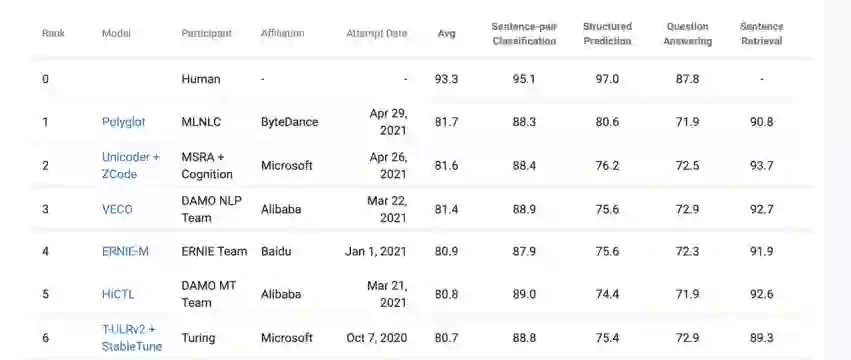
同时,X-Mixup 结合自研多语言表示的方案 Polyglot 在 XTREME leaderboard 上保持了 4 个月的第一名(2021.4~2021.8)。
![]()
关注于跨语言迁移中源语言和目标语言间巨大的性能差异,本文首先进行了相关分析,分析发现跨语言迁移效果和跨语言表示差异有很强的相关性。为了减少跨语言表示差异,本文提出了跨语言流形混合 (X-Mixup) 方法为目标语言提供 “折衷” 的表示,让模型自适应地校准表示差异。此方法不仅显著地减少了跨语言表示差异,同时有效地提升了跨语言迁移的效果。此外,本文关于跨语言迁移效果和跨语言表示差异的结论也为未来的跨语言迁移研究提供了相关思路。
[1] Yang et al. Enhancing Cross-lingual Transfer by Manifold Mixup. ICLR 2022.
[2] Hu et al. XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization. ICML 2020.
[3]Lauscher et al. From Zero to Hero: On the Limitations of Zero-Shot Language Transfer with Multilingual Transformers. EMNLP 2020.
[4]Wu & Dredze. Are All Languages Created Equal in Multilingual BERT? ACL 2020.
[5] Kornblith et al. Similarity of Neural Network Representations Revisited. ICML 2019.
[6] Zhang et al. mixup: Beyond Empirical Risk Minimization. ICLR 2018.
[7] Verma et al. Manifold Mixup: Better Representations by Interpolating Hidden States. ICML 2019.
[8]Fomicheva et al. Unsupervised Quality Estimation for Neural Machine Translation. TACL 2020.
[9]Bengio et al. Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks. NeurIPS 2019.
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com