论文报告 | Semi-supervised Word Sense Disambiguation

链接:https://arxiv.org/pdf/1603.07012.pdf
简介:
本文解决的问题是自然语言处理领域里的经典任务之一:语义消歧(Word Sense Disambiguation, WSD)。作者提出首先通过LSTM在大规模数据集上训练语言模型,然后有语义标注的数据集上学习得到每个词在不同上下文的语义。接下里,第一种方法可以通过无监督的最近邻方法获得测试数据中每个单词的sense;第二种方法使用了较为复杂的标签传播模型(Label propagation)。本文另一个贡献是开源了一个较大的带标注的语义消歧数据集。
模型
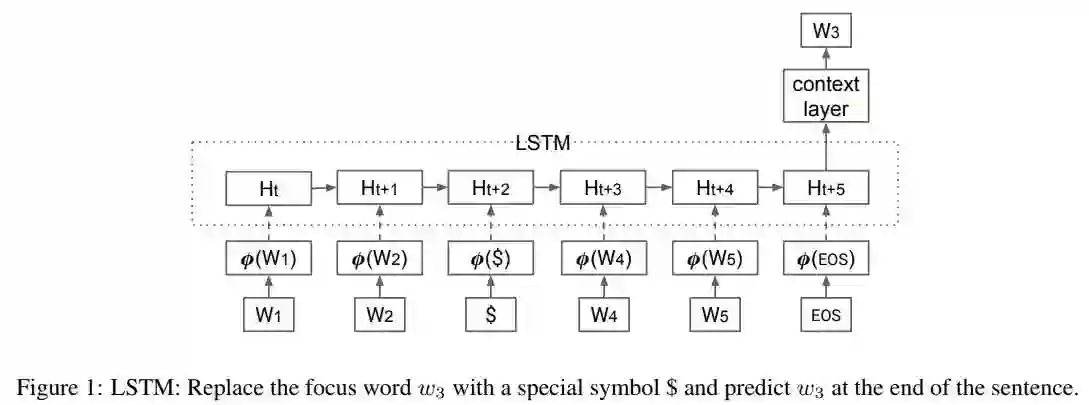
如上,本文的模型结构非常简单--LSTM。首先,作者提出使用大规模的无标签语料训练一个语言模型,本文使用的语料包涵100B个词(未开放此语料)。在经过预训练后,使用LSTM来获得待消歧词的上下文信息。具体做法是使用特殊字符 $ 取代待消歧词,然后用LSTM对整个句子进行编码,LSTM的最后一个输出即为当前待消歧词的上下文信息。接下来,作者提出了 两种方法来进行消歧。
方法一
最近邻(NN)方法。首先使用上面的LSTM学习获得带标注训练语料中的每个词的每个sense的embedding,然后将同一个词同一个sense的embedding进行取平均,取平均之后的embedding即为该词该sense的embedding。在测试阶段,我们使用LSTM获得待测试词的上下文信息,然后计算该embedding与该词所有sense的embedding的余弦相似度。取相似度最大的为该词在当前context中的sense。
方法二
方法二使用了标签传播算法,其中引入了大量未标注语料进行辅助。由于作者未开源本文的代码和语料数据,很难理解这块是怎么做的。包括后面的一些文章也说难以复现本文这部分实验。
实验:
作者在传统的Senseval2, Senseval3, SemEval-7, SemEval-10和SemEval-2013上做了大量的实验,都取得了STOA结果。同时,作者还在Google自己标注的大型数据集上进行了实验,也取得了很好的实验结果。
思考
语义消歧问题非常经典,之前受制于训练数据集太小,很多深度学习方法表现并不好,本文提出使用大规模语料预训练语言模型,然后使用该语言模型获得每个词的context embedding,取得了很好的效果。其它很多论文的实验也表明,大规模无监督语料非常重要.语义消歧的本质还是对上下文的理解,能否找到一种合适的方法构建一个图结构,然后每个上下文对应图上的一种信号。使用类似GCN的方法来解决。
作者:宋卫平,北京大学在读博士,研究方向为深度学习,推荐系统,网络表示学习。


