详解立体匹配系列经典SGM: (6) 视差填充
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
作者李迎松授权发布,武汉大学 摄影测量与遥感专业 博士
https://ethanli.blog.csdn.net/article/details/105065660
科学是一个精益求精的过程。
详解立体匹配系列经典SGM: (1) 框架与类设计 详解立体匹配系列经典SGM: (2) 代价计算
详解立体匹配系列经典SGM: (3) 代价聚合
详解立体匹配系列经典SGM: (4) 视差计算、视差优化 详解立体匹配系列经典SGM: (5) 视差优化
代码已同步于Github开源项目: https://github.com/ethan-li-coding/SemiGlobalMatching
抱歉同学们,视差优化的完结篇被我安排成了一个系列篇,实在是SGM太过经典,每一点我都想拿出来单独成篇,作者在视差优化模块的确安排了很多子模块,每个模块都有其存在的意义。上一篇我们学习了怎么做一些常规的视差优化操作:一致性检查、唯一性约束、去除小连通区等。本篇我们来说一说视差填充。
我们再次整理下整个优化的子模块,让大家思路更清晰一些:
1. 子像素拟合(Subpixel)
2. 一致性检查(Left/Right Consistency Check)
3. 唯一性约束(Uniqueness)
4. 剔除小连通区(Remove Peaks)
5. 中值滤波(Median Filter)
6. 弱纹理区优化
7. 填补空洞
本篇我们讲的是第7点。即填补空洞,也就是视差图填充。
先看看本篇最后的实验成果,让大家有个初探的兴趣:

上图一看,大家就明白What is 视差填充了,那我们就进主题吧。
视差填充,即给视差图的无效区域像素分配一个有效值。填充之前要问两个问题:
1. 无效区是否一视同仁?
2. 有效值哪里来?
本文前两个小节就是回答这两个问题。
遮挡区和误匹配区
回答第一个问题,无效区是否一视同仁? 答案是NO!需要区分遮挡区和误匹配区。
遮挡区:由于前景遮挡而在左视图上可见但在右视图上不可见的像素区域。
误匹配区:位于非遮挡区域的错误匹配像素区域。
从定义可以看出,其实两者都是错误匹配像素区域,我们的主要目的是为了把遮挡区拿出来单独成一类,因为遮挡区比较特殊,它们位于视差非连续区域,一侧是前景,视差值较大,一侧是背景,视差值较小,它理应和背景像素视差更为接近,而和前景视差相差较大,所以填补时应该尽量选择周围背景像素的视差,避免选择前景像素。
误匹配区则不同,它们并不在遮挡区,邻域像素都位于一个连续的视差表面,视差是连续的,所以填补时可以考虑邻域内的所有像素。
总之,在填充前,我们要做个判断,哪些像素是遮挡区,哪些像素是误匹配区。
作者是通过如下方法来判断遮挡区的:
(1)像素是通过各种优化操作而判定的无效像素。
(2)左影像像素在右影像上的匹配像素为
q=p−d,像素在右视差图上的值为
dr,通过
dr找到左影像的匹配点
p′,获取
p′的视差
d′,若
d′>d,则
p为遮挡区。
第二条有点绕,因为是两次对应,左找到右,右又反过来找左,换句话描述:假设 q是 p通过视差 d找到的同名点,如果在左影像存在另外一个像素也和是同名点而且它的视差比 d要大,那么就是遮挡区。
原文描述:A pixel p is occluded, if another pixel with higher disparity maps to the same pixel q in the match image1.
这个判定所基于的两个假设是:
(1)
p的视差值和周围的背景像素视差值比较接近。
(2)
p因为遮挡而在右影像上不可见,所以它会匹配到右影像上的前景像素,而前景像素的视差值必定比背景像素大,即比的视差大。
有人问,既然像素是无效像素,那么为啥还有视差值呢,答案就是在给无效值之前判断,这一步可以在一致性检查步骤里完成,实际上遮挡区主要都是通过一致性检查来使其无效的,因为遮挡区存在明显的左右差异性(左可见,右不可见),所以一致性检查大概率会让这些区域的像素无效。我们在一致性检查让的视差值无效之前,判断p是否是遮挡区和误匹配区。
【遮挡区和误匹配区判断代码】
// 判断两个视差值是否一致(差值在阈值内)
if (abs(disp - disp_r) > threshold) {
// 区分遮挡区和误匹配区
// 通过右影像视差算出在左影像的匹配像素,并获取视差disp_rl
// if(disp_rl > disp)
// pixel in occlusions
// else
// pixel in mismatches
const sint32 col_rl = static_cast<sint32>(col_right + disp_r + 0.5);
if(col_rl > 0 && col_rl < width){
const auto& disp_l = disp_left_[i*width + col_rl];
if(disp_l > disp) {
occlusions.emplace_back(i, j);
}
else {
mismatches.emplace_back(i, j);
}
}
else{
mismatches.emplace_back(i, j);
}
// 让视差值无效
disp = Invalid_Float;
}
有区别填充
回答第二个问题:有效视差从哪里来?
我们已经把无效像素分为了遮挡区和误匹配区,填充的有效视差来源也要区别分析。
首先,两者的共同点是,有效视差都来自于周围有效像素的视差值,区别在于如何从周围的有效视差中选出最合适的一个。
对于遮挡区像素,因为它的身份是背景像素,所以它是不能选择周围的前景像素视差值的,应该选择周围背景像素的视差值。由于背景像素视差值比前景像素小,所以在收集周围的有效视差值后,应选择较小的几个,具体哪一个呢?SGM作者选择的是次最小视差。
对于误匹配像素,它并不位于遮挡区,所以周围的像素都是可见的,而且没有遮挡导致的视差非连续的情况,它就像一个连续的表面凸起的一小块噪声,这时周围的视差值都是等价的,没有哪个应选哪个不应选,这时取中值就很适合。
文章中的公式是这样的:
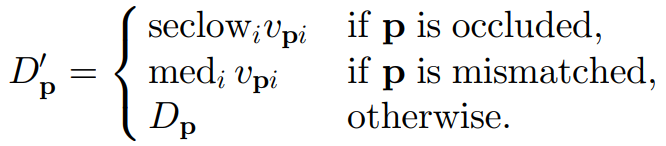
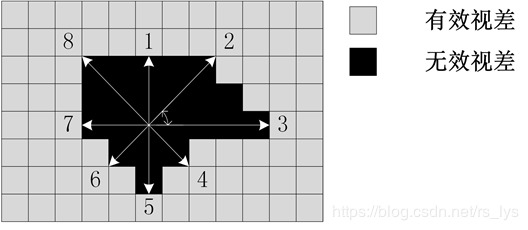
另一个关键点是如何找到周围的有效像素,博主提供一种思路:以像素为中心,等角度往外发射8条射线,收集每条射线碰到的第一个有效像素,如图所示:
至此,可以编写视差填充代码:
void SemiGlobalMatching::FillHolesInDispMap()
{
const sint32 width = width_;
const sint32 height = height_;
std::vector<float32> disp_collects;
// 定义8个方向
float32 pi = 3.1415926;
float32 angle1[8] = { pi, 3 * pi / 4, pi / 2, pi / 4, 0, 7 * pi / 4, 3 * pi / 2, 5 * pi / 4 };
float32 angle2[8] = { pi, 5 * pi / 4, 3 * pi / 2, 7 * pi / 4, 0, pi / 4, pi / 2, 3 * pi / 4 };
float32 *angle = angle1;
float32* disp_ptr = disp_left_;
for (int k = 0; k < 3; k++) {
// 第一次循环处理遮挡区,第二次循环处理误匹配区
auto& trg_pixels = (k == 0) ? occlusions_ : mismatches_;
std::vector<std::pair<int, int>> inv_pixels;
if (k == 2) {
// 第三次循环处理前两次没有处理干净的像素
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
if (disp_ptr[i * width + j] == Invalid_Float) {
inv_pixels.emplace_back(i, j);
}
}
}
trg_pixels = inv_pixels;
}
// 遍历待处理像素
for (auto& pix : trg_pixels) {
int y = pix.first;
int x = pix.second;
if (y == height / 2) {
angle = angle2;
}
// 收集8个方向上遇到的首个有效视差值
disp_collects.clear();
for (sint32 n = 0; n < 8; n++) {
const float32 ang = angle[n];
const float32 sina = sin(ang);
const float32 cosa = cos(ang);
for (sint32 n = 1; ; n++) {
const sint32 yy = y + n * sina;
const sint32 xx = x + n * cosa;
if (yy<0 || yy >= height || xx<0 || xx >= width) {
break;
}
auto& disp = *(disp_ptr + yy*width + xx);
if (disp != Invalid_Float) {
disp_collects.push_back(disp);
break;
}
}
}
if(disp_collects.empty()) {
continue;
}
std::sort(disp_collects.begin(), disp_collects.end());
// 如果是遮挡区,则选择第二小的视差值
// 如果是误匹配区,则选择中值
if (k == 0) {
if (disp_collects.size() > 1) {
disp_ptr[y*width + x] = disp_collects[1];
}
else {
disp_ptr[y*width + x] = disp_collects[0];
}
}
else{
disp_ptr[y*width + x] = disp_collects[disp_collects.size() / 2];
}
}
}
}
实验
实验如前言所见,博主做了视差填充前后的对比,如图:

可以看到,填充后视差图更加完整,视差估计也更加稠密。
但不得不讨论的是,视差填充始终是不精确的,无论是取最小值还是取中值,它只能说是通过周围的有效值来预测,所以精确程度是有限的,换句话说,遮挡区像素都看不见,何以预测出十分精确的值?所以我们通常会根据应用需求来决定是否执行视差填充,如果实际要求每个点足够准确,而不太要求是否足够完整,那么就不需要做视差填充;而如果要求视差图足够完整,而对填充精度要求不高,则可以执行视差填充。
代码已同步于Github开源项目:
https://github.com/ethan-li-coding/SemiGlobalMatching
大家可自行下载,点击项目右上角的star,有更新会实时通知到你的个人中心!
从0到1学习SLAM,戳↓
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life


