ELECTRA中文预训练模型开源,仅1/10参数量,性能依旧媲美BERT




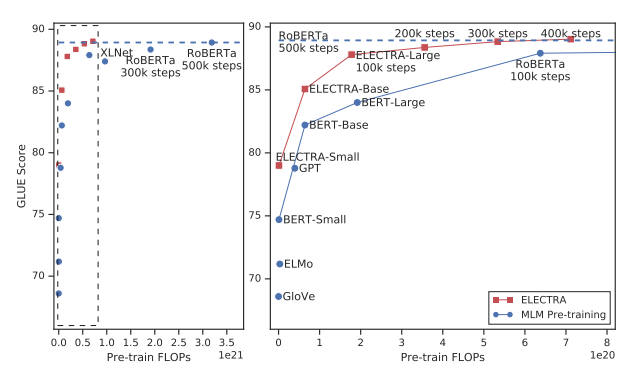
-
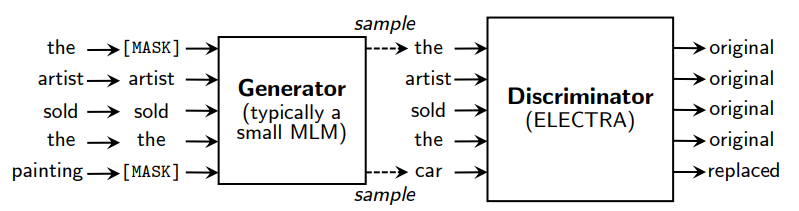
Generator: 一个小的MLM,在[MASK]的位置预测原来的词。Generator将用来把输入文本做部分词的替换。 -
Discriminator: 判断输入句子中的每个词是否被替换,即使用Replaced Token Detection (RTD)预训练任务,取代了BERT原始的Masked Language Model (MLM)。需要注意的是这里并没有使用Next Sentence Prediction (NSP)任务。
-
ELECTRA-base:12层,隐层768,12个注意力头,学习率2e-4,batch256,最大长度512,训练1M步 -
ELECTRA-small:12层,隐层256,4个注意力头,学习率5e-4,batch1024,最大长度512,训练1M步

-
CMRC 2018 (Cui et al., 2019):篇章片段抽取型阅读理解(简体中文) -
DRCD (Shao et al., 2018):篇章片段抽取型阅读理解(繁体中文) -
XNLI (Conneau et al., 2018):自然语言推断(三分类) -
ChnSentiCorp:情感分析(二分类) -
LCQMC (Liu et al., 2018):句对匹配(二分类) -
BQ Corpus (Chen et al., 2018):句对匹配(二分类)
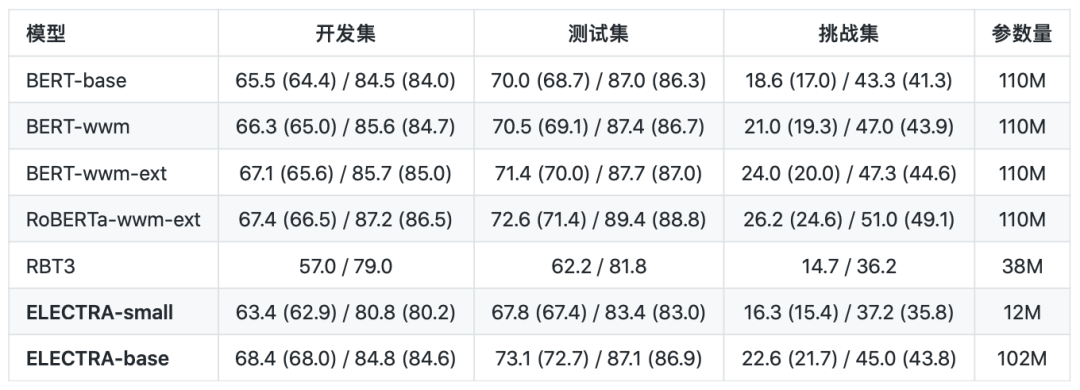
简体中文阅读理解:CMRC 2018(评价指标为:EM / F1)
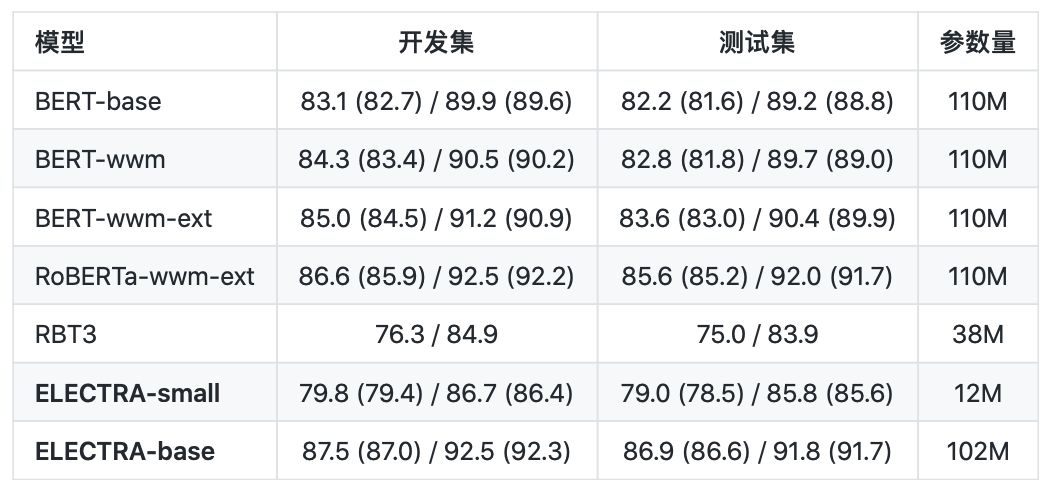
繁体中文阅读理解:DRCD(评价指标为:EM / F1)
自然语言推断:XNLI(评价指标为:Accuracy)
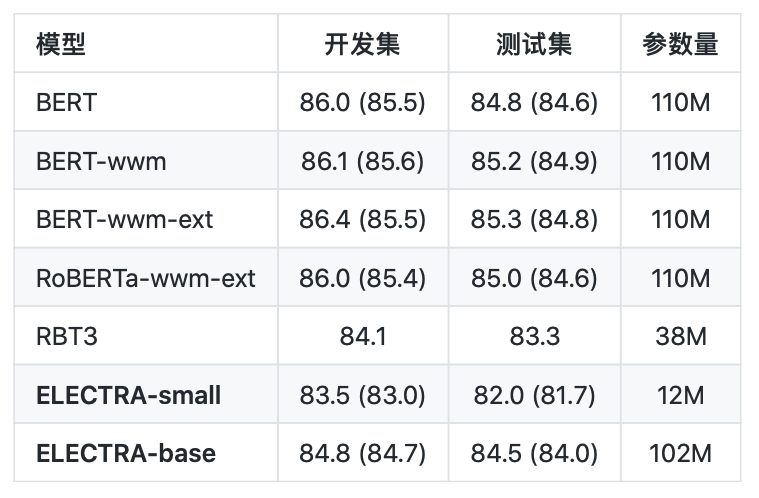
情感分析:ChnSentiCorp(评价指标为:Accuracy)
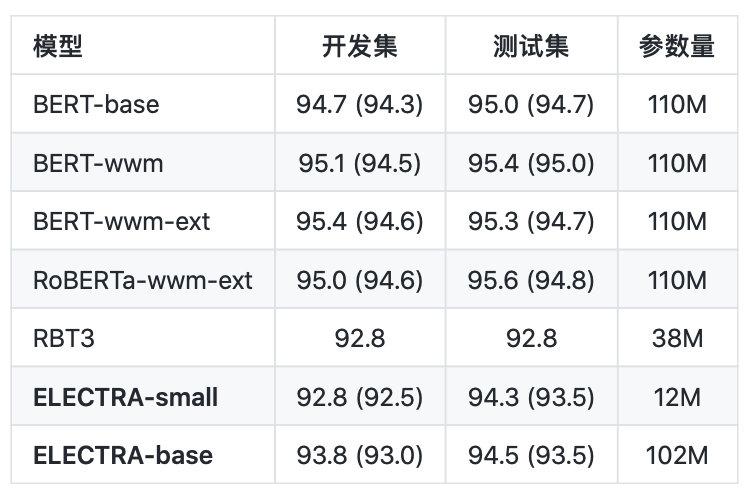
句对分类:LCQMC(评价指标为:Accuracy)
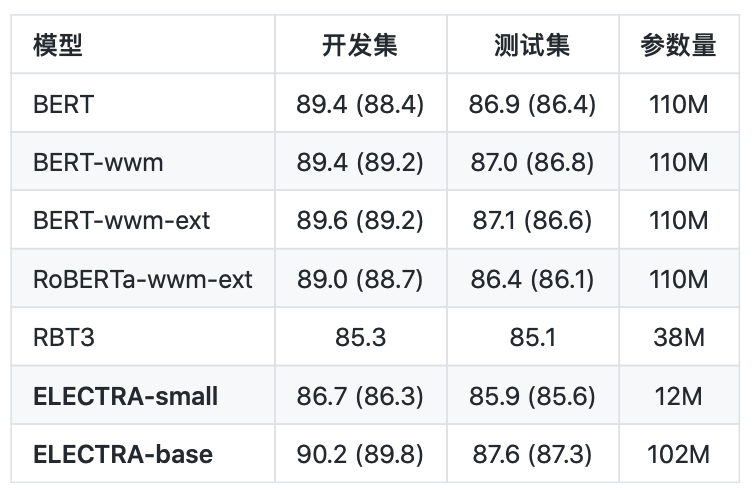
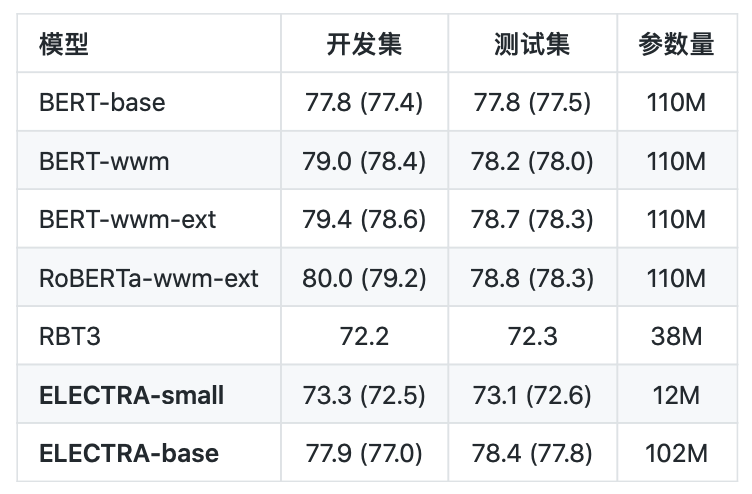
句对分类:BQ Corpus( 评价指标为:Accuracy)

 点击“
阅读原文” 查看 ICLR 系列论文解读
点击“
阅读原文” 查看 ICLR 系列论文解读
登录查看更多
相关内容

专知会员服务
79+阅读 · 2019年12月29日
Arxiv
15+阅读 · 2018年10月11日




相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日