MaxCompute 交互式分析(Hologres)如何完美支撑双11智能客服实时数仓?

阿里妹导读:在刚刚结束的2020天猫双11中,MaxCompute交互式分析(下称Hologres)+实时计算Flink搭建的云原生实时数仓首次在核心数据场景落地,为大数据平台创下一项新纪录。阿里巴巴客户体验事业部(CCO)基于Hologres,构建了集实时化、自助化、系统化于一体的用户体验实时数仓,全面助力双11。CCO在实时数据的应用上有哪些特点?随着数据量的剧增,实时技术架构在演进过程中面临哪些难点?为什么选择Hologres?本文分享CCO在实时技术上的经验沉淀,以及Hologres带来的业务价值。
文末福利:免费领阿里云盘内测邀请码。
CCO和Hologres合作构建用户体验实时数仓的故事得从4年前说起。
2016年,CCO开始将实时数据应用到业务中,主要支撑双11作战室(双11作战室又名光明顶,是阿里巴巴双11期间的总指挥室,其作战大屏承载了全集团双11期间的作战指挥系统,是阿里巴巴作战组织的技术、产品、服务串联起来的“作战指挥图”)大屏应用。
2017年,CCO实时数据应用出现了规模化的上涨,不再局限于大促,在日常的客服小二管理实时监控、对内运营数据产品、线上产品数据应用及算法模型在线应用场景中,也开始大规模应用。
2018年,整体实时数据任务高保障作业数已经接近400,大促中,双11指挥室大屏也全面取消了准实时的应用,全面实时化落地。
可以说,CCO和Hologres的合作取得了阶段性成功。
截止到目前,实时作业数已经超过800+。从作业的规模、各类引擎中间件的使用、业务场景的覆盖发展到非常多元化的一个阶段。
在多元化这个阶段,整体上CCO在实时数据的应用上呈现出几个新特点:
数据复杂度高,覆盖了从用户加购、下单、支付到售后退款等全渠道的业务场景及数据依赖。
数据量大,从手淘日志(千万/秒峰值)到交易(几百万/秒峰值)到咨询(几十万/秒峰值)。
应用场景丰富,实时监控大屏,实时交互式分析数据产品,To B/C类的线上应用。
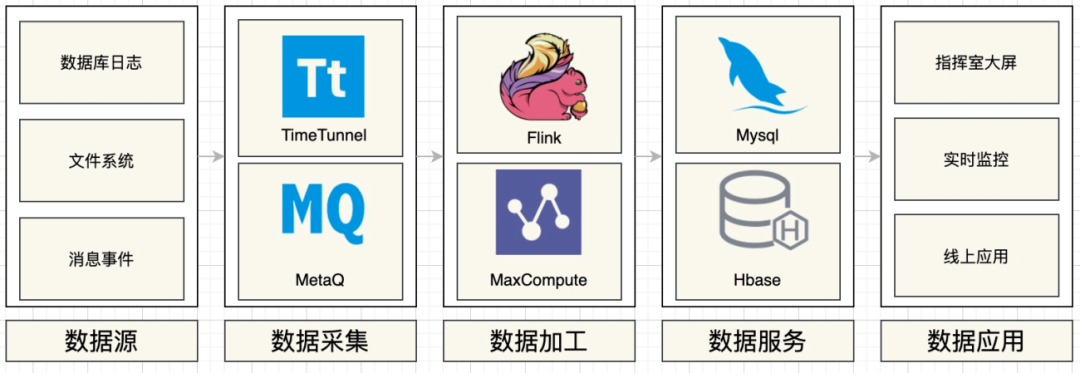
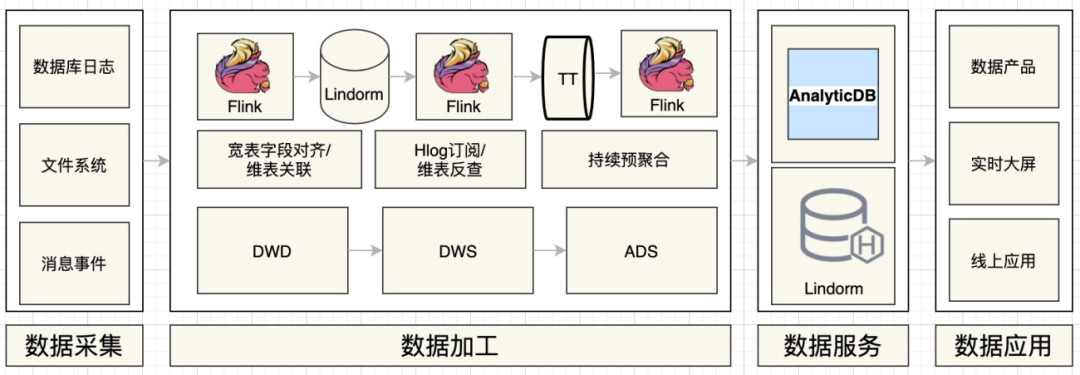
引入OLAP引擎:小数据量的明细、轻度汇总等数据统一存储到AnalyticDB,支持较高QPS的OLAP Query。
数据模型及任务加工分层:在DWD层按照主题将不同数据源数据整合,并且输出到Lindorm,然后通过Hlog订阅,触发流任务反查事实表,将宽表字段对齐输出到TT,做为DWD中间层存储。构建可复用的DWS层,将常用维度及指标按照主题建模,供下游复用,减少烟囱化。
常用的做法就是按照业务场景分拆实例,按照保障等级分拆实例,按照不同服务形式路由到不同的引擎,比如KV/OLAP。任务不得不重复建设,需要在重复建设和稳定性上做出权衡。在实践中,我们往往选择了第二或者第三种方式来优先保障稳定性,由于在同一任务中增加多个SINK到不同实例,任何一个实例有问题,都会造成整个任务背压或者failover,会影响到其它实例的稳定性。
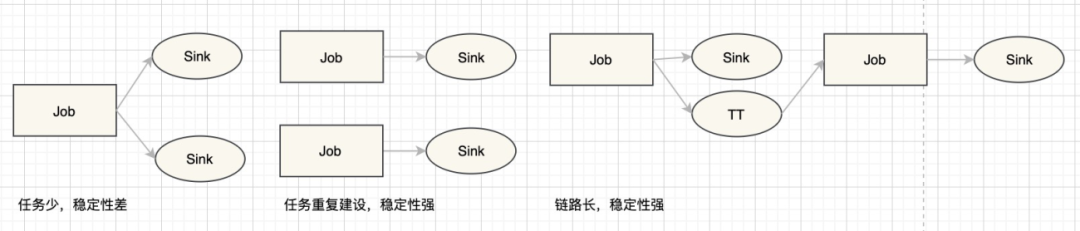
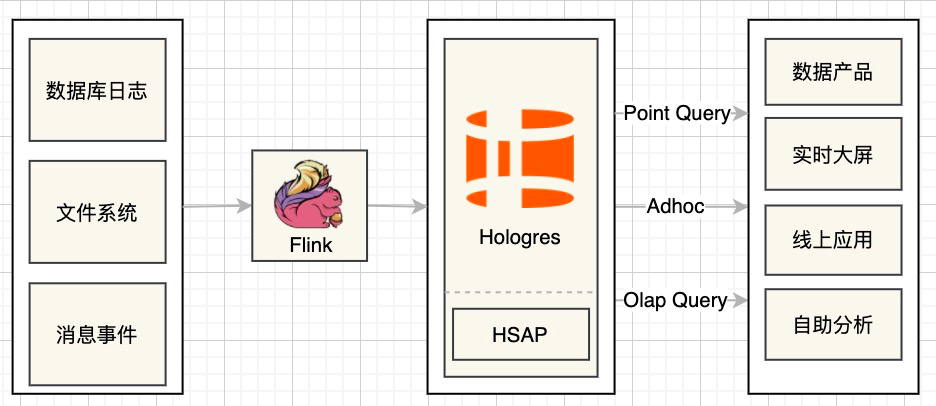
实际场景中,我们需要提供Point Query,Adhoc Query,Olap Query等多种服务形式,我们需要至少在KV存储和MPP存储中存放两份,造成非常多不必要存储,存储成本也只增不降。
支持行存列存,HSAP的混合服务能力:针对现有的Point Query的场景,可以采取行存方式存储,针对典型的OLAP场景,可以采取列存方式存储。
高吞吐的实时写入:经过实际测试,对于行存的写入,目前可以满足我们业务上千万/s的吞吐要求,在列存的OLAP场景上,可以轻松应对我们几十万/s的高聚合数据写入要求。
行存的日志订阅以及维表关联能力:我们写入Hologres行存表的数据,可以通过Binlog订阅,通过Hologres connector,轻松应用Flink的任务开发中,将公共层明细数据有选择的进行二次计算,并写入回Hologres,提供给不同的应用场景,一定程度上解决了Hologres引擎和Flink引擎计算的算力平衡和高QPS的相应问题。
云原生:支持弹性扩缩容和高度可扩展性,今年大促我们在几分钟内完成平时几倍资源的扩容,可以轻松应对日常和大促的弹性业务需求。
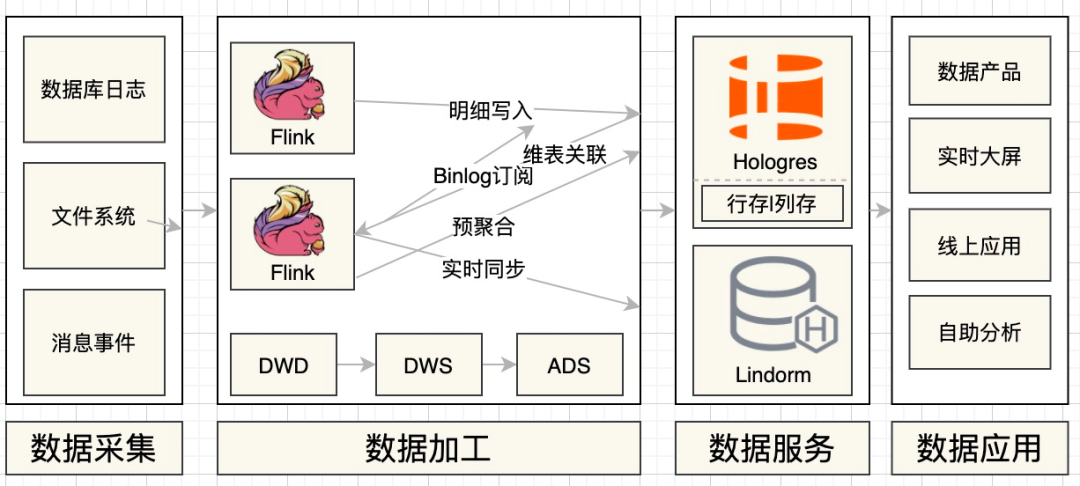
统一存储:需要Point Query的表在Hologres中使用行存模式,并且存放公共明细层、公共轻度汇总层,需要OLAP查询的表使用列存模式,存放于应用层明细、应用层汇总。
简化实时链路:Hologres行存集群存放的公共层数据,通过Binlog订阅,供应用层做二次消费,替代Lindorm订阅日志,再通过额外任务反查获取整行记录的链路。
统一服务:Point Query路由到行存表,Olap Query路由到列存表。
流批一体:小型维表的加速不再通过异构数据导入的方式加载,而是直接在Hologres中创建外表,通过外表与内表的联邦查询(join)能力,直接为线上OLAP应用场景提供服务。
服务SLA:希望Hologres可以有主备机制,在存储计算分离的架构上,计算引擎可以主备,存储可以在不同的Pangu集群存在多副本的能力,保证业务在写入和读取上,任何主链路故障的情况下,可以无感切换到备实例。
实例间实时同步:在实践中,由于不同业务场景的不同保障等级,拆分实例可能将是未来较长时间内的一个可行的解决方案,当前我们是通过Flink任务将数据做实例间同步,实例间互相实时同步数据的能力可以极大的降低业务开发成本和维护成本。
资源隔离:真正意义的行/列混存,可以在同一个表上支撑Point Query和Olap Query,独立的资源分配,又互不影响。
弹性变更:table group的shard count可以动态扩/缩,能够灵活应对峰值及日常的业务需要。
二级索引:对于Point Query支持海量数据的非PK point query,同时可应用于流计算中,可以极大降低模型建设的冗余度。
阿里云盘开启内测啦~识别下方二维码加「阿里妹」微信好友,备注【福利放送】,即可免费领取阿里云盘内测邀请码!