成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
数据仓库
关注
1060
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。 数据仓库是决策支持系统和联机分析应用数据源的结构化数据环境。数据仓库研究和解决从数据库中获取信息的问题。其特征在于面向主题、集成性、稳定性和时变性。
综合
百科
VIP
热门
动态
论文
精华
精品内容
实时数仓赋能金融业务的落地实践
专知会员服务
21+阅读 · 2022年7月24日
知识图谱如何落地?Neo4j这本《知识图谱:数据业务应用》书为你讲述如何构建和使用知识图谱及其对创新的重要性
专知会员服务
176+阅读 · 2022年2月18日
【2020新书】现代数据仓库,297页pdf,The Modern Data Warehouse in Azure
专知会员服务
59+阅读 · 2020年6月17日
【2020新书】如何构建数据团队?:设计集成的技能、需求和解决方案,257页pdf
专知会员服务
115+阅读 · 2020年3月11日
参考链接
父主题
交互分析平台
商业智能(BI)
数据挖掘
子主题
Shark
Hive
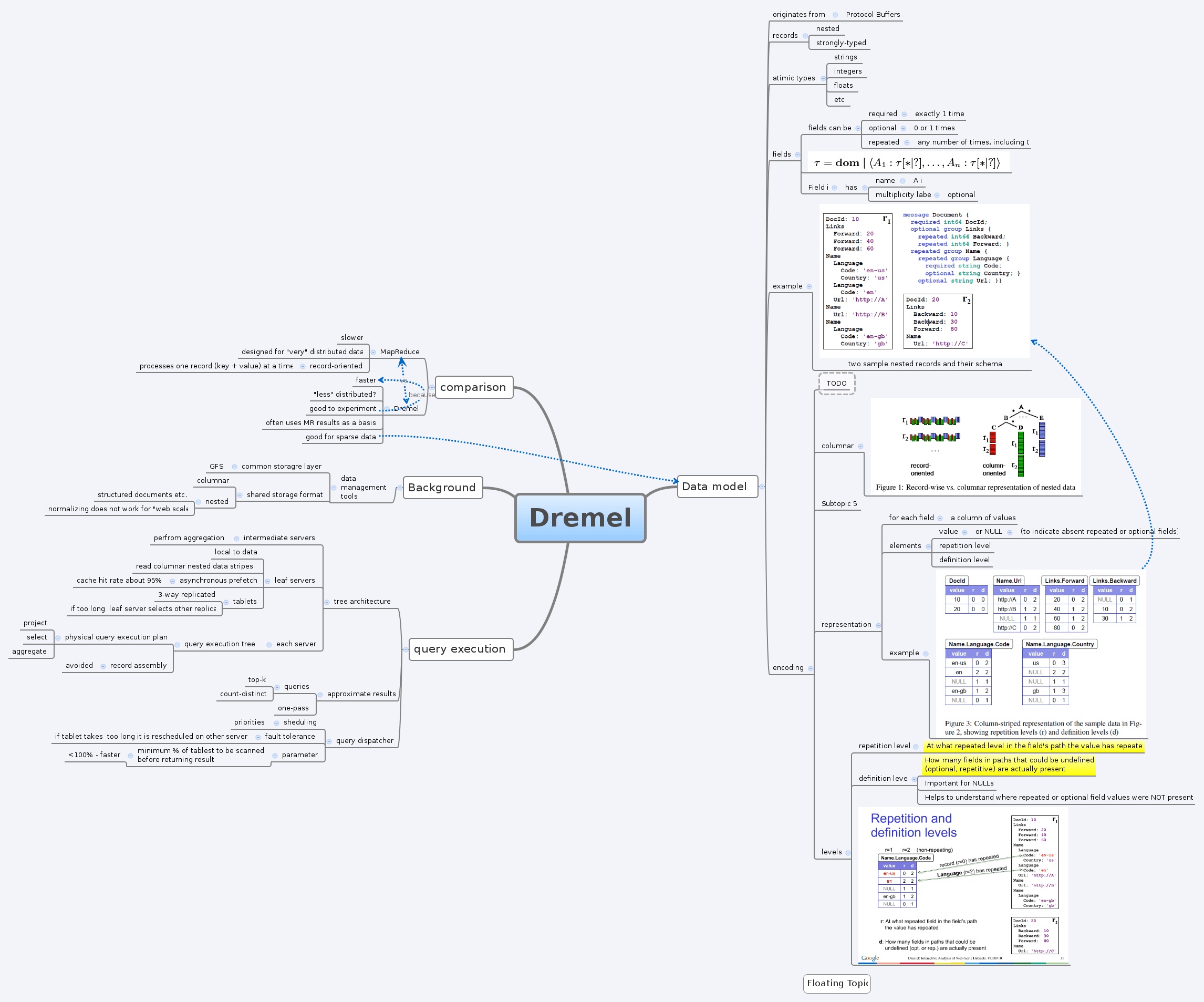
Dremel
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top