如何提取网络架构的先验知识?为它画幅素描吧!
选自谷歌博客
机器之心编译
参与:郭元晨、Geek AI
五花八门的深度神经网络看似结构各不相同,其内在学习逻辑实则有迹可循。 且看谷歌的研究人员如何通过「递归速写」方法提取知识、进行神经网络压缩,最终实现在未曾训练过的场景下的智能推理。
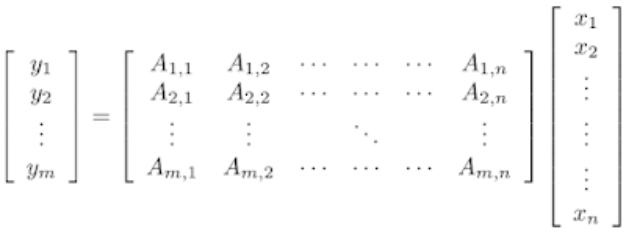
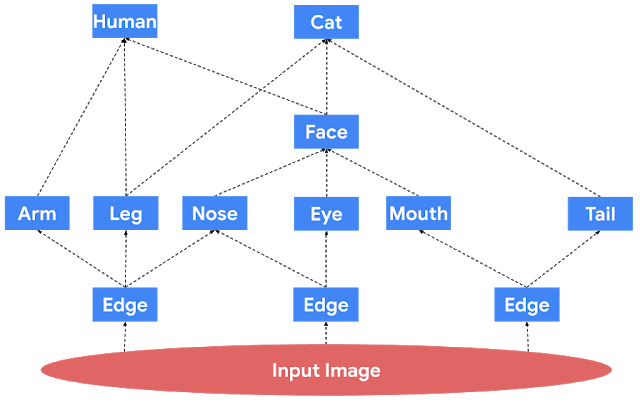
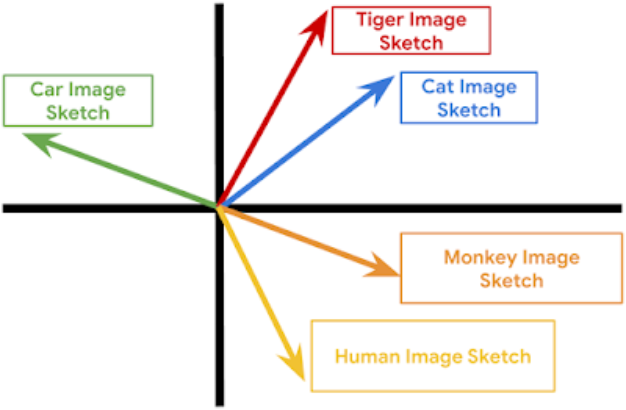
「速写」间的相似性:两个不相关的网络操作(无论从模块本身还是向量属性来说)的「速写」应当是非常不同的;同理,两个相似网络计算的「速写」应该很相像近。
属性恢复:属性向量(即图中任何结点的激活函数值),都可以根据顶层「速写」大致恢复。
概要统计量:如果有多个相似的物体,我们可以恢复出这些物体的概要统计量。比如,如果一张图像中有多只猫,那么我们可以数出有多少只。请注意,这些问题在训练中是不会出现的。
可擦除性:擦除顶层「速写」的后缀仍可以保留以上特性(但会稍微增大误差)。
网络恢复:给定足够多的(输入,「速写」)对,可以粗略地会付出网络边的连接方式以及「速写」函数。
登录查看更多
相关内容
专知会员服务
44+阅读 · 2020年3月26日
Arxiv
4+阅读 · 2018年9月11日
Arxiv
3+阅读 · 2018年8月2日
Arxiv
4+阅读 · 2018年5月29日
Arxiv
4+阅读 · 2018年1月25日



相关VIP内容
专知会员服务
44+阅读 · 2020年3月26日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年9月11日
Arxiv
3+阅读 · 2018年8月2日
Arxiv
4+阅读 · 2018年5月29日
Arxiv
4+阅读 · 2018年1月25日