工程设计+算法规模化真的是AI突破吗?DeepMind唇读系统ICLR遭拒
选自 OpenReview
机器之心编译
上周,ICLR 2019 接收论文名单放出,令人惊讶的是 DeepMind & Google 的论文《LARGE-SCALE VISUAL SPEECH RECOGNITION》未被接收。这篇论文的评审得分为:3,4,9,可谓是两极分化了。评审们认为即使它在工程上和数据上都非常突出,但大模型加上大数据会提升性能是共识,这类改进不能被看作是贡献。
这种情况不禁让人想起 2016 年引起热议的 LipNet 论文(牛津大学人工智能实验室、谷歌 DeepMind 和加拿大高等研究院 (CIFAR) 合作的研究),这篇论文同样与 ICLR 2017 失之交臂。此外,这两篇论文有三位共同作者 Brendan Shillingford、Yannis Assael 和 Nando de Freitas,两篇论文的一作都是 Brendan Shillingford 和 Yannis Assael,两篇论文的主题都是唇读。
LipNet 是一项利用机器学习实现句子层面自动唇读的技术,该技术将自动唇读技术的前沿水平推进到了前所未有的高度。那么 DeepMind 这次的论文主要是讲什么呢?
论文概要
论文链接:https://openreview.net/pdf?id=HJxpDiC5tX
该研究提出了一种新型唇读系统(如下图所示),它可以将原始视频转换成单词序列。该系统的第一个组件是数据处理流程,用于创建该研究使用的大规模视觉语音识别(LSVSR)数据集,其中的数据来自 YouTube 视频,包括说话视频片段及对应的音素序列,共包括 3886 小时的视频)。该数据集的创建需要结合计算机视觉和机器学习技术。该数据处理流程将原始音频和标注音频片段作为输入,然后进行过滤和预处理,最后输出音素和嘴唇帧对齐序列的集合。与之前的视觉语音识别研究相比,该研究的数据处理流程使用了 landmark smoothing、模糊度过滤器(blurriness filter)、改进版说话分类器网络和输出音素。
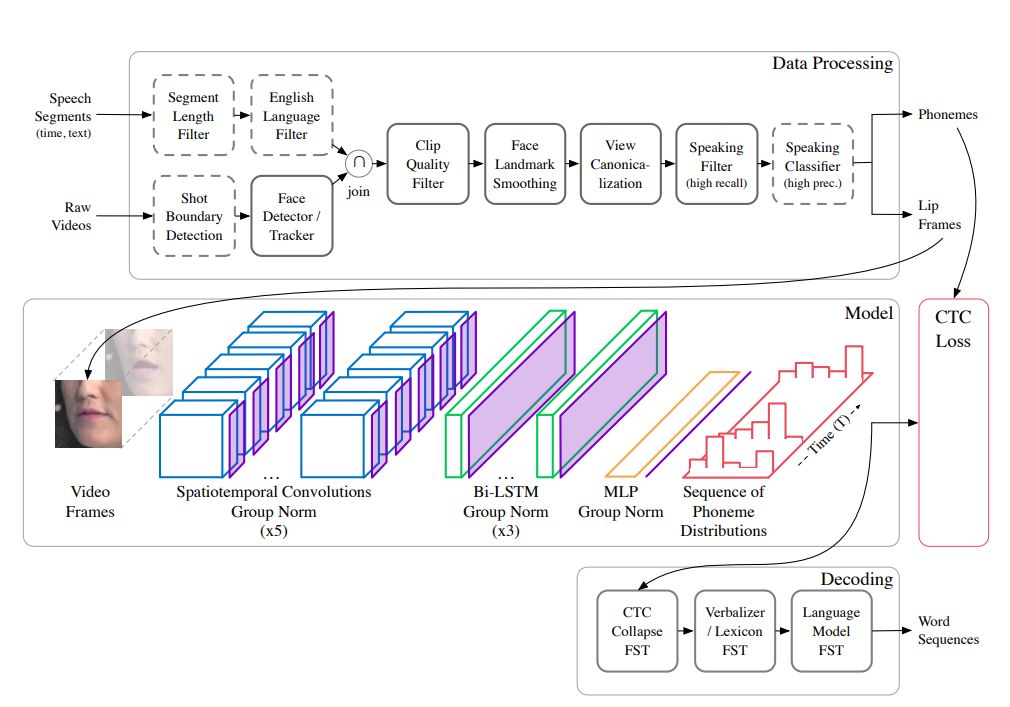
图 1:该研究的完整视觉语音识别系统概览,包括数据处理流程(基于 YouTube 视频生成嘴唇和音素帧)、用于识别音素的可扩展深度神经网络,以及用于推断的生产级词解码模块。
该研究提出的集成式唇读系统包括视频处理流程(将原始视频转换成音素和嘴唇帧序列的集合)、可扩展深度神经网络(将嘴唇视频与音素分布的序列进行匹配,即识别音素),以及生产级音频解码器(输出词序列)。据介绍,该系统在留出集上达到了 40.9% 的词错率(WER)。相比之下,专业唇读者在同样的数据集上的词错率为 86.4% 或 92.9%,且他们可以获取额外的语境信息。该方法相比之前的唇读方法有显著提升,包括 LipNet 和 Watch, Attend, and Spell (WAS) 的变体,二者的词错率分别为 89.8% 和 76.8%。
如前所述,该论文在评审阶段得到的分数分别为 3,4,9。为什么会出现这样的两极分化局面呢?我们来看一下评审人员的评审意见。
低分评审结果
领域主席(AC)在 reject 声明中发表了以下观点:
这篇论文很有争议,作者和评审人员进行了大量讨论,主要的争论焦点在于该论文是否适合 ICLR。这篇论文的所有评审人员都认可该研究的质量和研究结果,但是在该论文是否适合 ICLR 这个问题上存在很大分歧。
一位评审者认为适合,但其他两位持反对看法,他们认为要想被 ICLR 接收,这篇论文要么更加注重数据集的准备,包括数据集的公开发布,以便其他研究者可以从该研究中获益,将该研究提出的 V2P 模型作为唇读任务的(非常)强基线;要么更深入地探究该研究中关于表征学习的内容,如对比音素和视位单元、提供更多(当然也更费时费力)对照实验(ablation experiment),以便更深入地揭示该 V2P 架构的哪个组件带来了性能改进。
AC 认为两位持反对意见的评审者的论据充分,具备一定说服力。很明显,很多监督式分类任务(即使是唇读这样的结构化分类任务)可以通过足够灵活的学习架构和大规模标注数据集来解决,而这篇论文使用的建模技术本质上并不新颖,即使该技术的应用领域是唇读。此外,如果该研究创建的数据集不公开发布,则其他人无法基于该数据集进行研究。目前来看,该论文较适合偏重应用的会议。
匿名评审 1(评分 3)
很明显,该论文提出了一种大规模唇读系统。很好的一项工作,也可能是当前最强大、通用的唇读系统,但我觉得该工作与论文并不是很适合 ICLR。
论文作者收集了大量 YouTube 视频,并过滤和抽取能用于唇读的区域。然后他们设计了一种可扩展的预处理方法,并使用 CTC 方法训练基于音素的声学模型。不过他们似乎使用了 Miao 等人 2015 的研究《EESEN: END-TO-END SPEECH RECOGNITION USING DEEP RNN MODELS AND WFST-BASED DECODING》与谷歌 WFST 解码架构,并实现大约 40% 的词错率。结果很不错,但是我并没有看到任何创新性,论文中也充满了矛盾。
因此,匿名评审 1 从细节到概念提出了 10 个问题,包括:LipNet 和这个架构看起来很类似,也许你们可以指出哪些改变造成了这两个系统的性能差异?」
在论文作者回应后,匿名评审 1 表示:
在目前的版本中,作者指出这篇论文之所以重要,主要是因为(1)数据规模大/性能好;(2)能帮助听力受损的人;(3)与图像处理流程的相关性。这表明该论文适合大数据和/或偏工程的会议、 accessibility leaning 会议,或偏应用的语音/视觉(甚至多模态)会议。
就当前的论文版本而言,我仍然很难发现哪个或哪些修改可以令这篇论文适合 ICLR,我认为作者可以继续深挖模型为什么要这么做,以及解决一些问题(是否会公开发布数据集?为什么使用音素而不是视位?)
匿名评审 2(评分 4)
该研究收集的数据集无疑是一项贡献,但除此之外,技术创新不够,因为所有的技术在视频唇读或者语音识别中都被提出过。表 1 中的数值很惊人,但难以搞清楚提升来自哪里。因此,值得多做一些实验:a) 在标注数据集不变的情况下改变网络架构;b) 固定网络架构,改变标注数据集;c) 固定网络架构与标注数据集,改变 dropout 或组归一化。seq2seq 在此论文中就是一熊孩子,因为你无法拿它和其他设置对比。表 2 的数据也很惊人,但如果提出的系统能在 LRS3-TED 上训练,并与 TM-seq2seq 对比会更好。
现在大家的共识是,大模型加上大数据会提升表现,但这类改进不能被看作是贡献。作者有责任做一些综合实验,证明论文中的改进不是因为更大的模型、更多的数据。
在论文作者回应后,匿名评审 2 表示:
我认为该论文提出的数据集和系统都有很大贡献,也将会有很大的影响力。但是,我依然认为该研究技术创新有限,因为我读完之后没学到任何东西,除了这个任务很难。整体方法和 Miao 等人 2015 年的论文一致,网络架构也类似于 Sainath 等人 2015 年的论文。我同意评审 1 的观点,很难给这篇论文高分。如果这篇论文 focus 在数据集以及数据集准备流程且提供强大的基准上,我可能乐意给出一个高分。
高分评审结果
匿名评审 3(评分 9)
这是一篇好论文。首先,它提供了一个大规模视觉语音识别语料库。其次,它展示了一个基于开放词汇的视觉语音识别系统,且取得了当前最优的准确率。论文写作也很好,所有的技术细节非常明晰。我个人非常感谢作者把这一精细研究贡献给社区。这是我在 ASR/VSR 社区看到的最大的 VSR 数据集,也是表现最令人深刻的一项研究。读这篇论文,非常享受。
基于反馈,我再补充些评审意见。一些人认为这项工作在工程上很成功,但缺乏技术创新,因此不能被 ICLR 接收。但我不这么认为。首先,作者把创建大规模视觉语音识别数据集的技术设计流程描述的非常清楚,这对社区贡献就很大。(在评审论文时,我假设此数据集将会开放给社区,这可能不太对,我在此致歉。我真的希望该数据集能够公开,这是我给高分的主要原因。)其次,作者构建了一个在视觉语音识别任务上取得顶尖水平的系统。尽管模型与架构已经有了,但惊人的性能本身对此领域的影响就很大。这不是在大量数据上做工程就能得到的(虽然数据发挥一定作用)。这是一篇系统论文,但其影响与性能值得被 ICLR 大会接收。

机器之心CES 2019专题报道即将到来,欢迎大家积极关注。

点击「阅读原文」查看机器之心专题页。



