「Deep Learning」读书系列分享第二章:线性代数 | 分享总结

AI 科技评论按:「Deep Learning」这本书是机器学习领域的重磅书籍,三位作者分别是机器学习界名人、GAN的提出者、谷歌大脑研究科学家 Ian Goodfellow,神经网络领域创始三位创始人之一的蒙特利尔大学教授 Yoshua Bengio(也是 Ian Goodfellow的老师)、同在蒙特利尔大学的神经网络与数据挖掘教授 Aaron Courville。只看作者阵容就知道这本书肯定能够从深度学习的基础知识和原理一直讲到最新的方法,而且在技术的应用方面也有许多具体介绍。这本书面向的对象也不仅是学习相关专业的高校学生,还能够为研究人员和业界的技术人员提供稳妥的指导意见、提供解决问题的新鲜思路。
面对着这样一本内容精彩的好书,不管你有没有入手开始阅读,AI 科技评论都希望借此给大家提供一个共同讨论、共同提高的机会。所以我们请来了曾在百度和阿里工作过的资深算法工程师王奇文与大家一起分享他的读书感受。
分享人:王奇文,资深算法工程师,曾在百度和阿里工作,先后做过推荐系统、分布式、数据挖掘、用户建模、聊天机器人。“算法路上,砥砺前行”。
「Deep learning」读书分享(二) —— 第二章 线性代数

我们上次讲的是「深度学习」第一章:简介,今天分享的是第二章:线性代数。右上角是这一章的目录,从27页到42页,内容不多,基本都是传统形式上的概念。同样,我只讲直观思路,尽可能的少用公式,毕竟好多人见着数学公式就头疼,更不用说在PPT上看了,效果不好,容易催眠,看着看着就身在朝野心在汉了。

左侧是基本框架,刚开始会有一些基本介绍,比如标量、向量、矩阵、张量;然后详细讲解下向量、矩阵,和矩阵分解。矩阵分解里面要特别强调:一个“特征值分解”,还有一个“奇异值分解”;接着,向量和矩阵之间什么关系;最后是应用案例。这部分对机器学习和深度学习来说是非常重要的,如果想从事机器学习方面的研究或者是工作,必须掌握。而且今天讲的线性代数是所有数学基础里面最简单的。
我会分成两部分来讲,第一部分是非常传统的方法,就是讲向量是什么、标量是什么等等一些常规的定义、概念,比较枯燥,我会讲得快一些,帮大家快速回顾下曾经学过的《线性代数》或《高等代数》(数学系教材),把还给老师的知识一点点拿回来!(不能白交学费是吧?)所以请大家集中注意力。
第二部分我会换一种方式,从直观感觉上重新理解线性代数的本质,这部分是精华,一般人都没见过,保证让你醍醐灌顶。
第一部分:传统方法

几种类型:
标量,简单来说就是一个数字,像X=3,它就是一个数值;而向量就是一列数或者一堆数,把它排成一行或者一列,然后就对应到线性空间里的一个点或者一个矢量(也就是带方向的线段)。这个线性空间可以是多维的,具体二维还是三维就看这里面堆了几个数。像x=(1,3,6),对应的是三个坐标,就是三维空间里面的一个点;而三维空间的原点到这个点有向线段就是一个向量。
接着是矩阵。矩阵是把向量按照行方向或者是列方向排列起来,变成一个二维数组。像右侧矩阵A里面这样排列。
张量是矩阵基础上更高维度的抽象,它的维度可能比前面还要高,主要对应于包含若干坐标轴的规则网格。
从刚才的那些讲解上可以发现:
标量相当于一维向量(暂时忽略方向,严格来说是向量单个维度的大小)
而向量是只有一维矩阵
矩阵是张量的一个切片
从上到下是维度的逐渐提升。反过来从下往上,张量、矩阵、向量、标量,是不断降维的过程。所以前面的类型只是后面的一个特殊形式,比如说任意一个向量,是张量的一种特殊形式。简而言之,张量囊括一切。

向量一般分成方向和长度两部分。像这个x是一个单位向量,它的特点是长度是1个单位。
关于向量,有这两种理解:
把它当做线性空间里面一个点
把它当做带有方向一个线段
这两种都可以。
跟向量有关的两种运算,一种是内积,第二种是外积。根据定义,内积会生成一个数,外积会生成一个向量;需要根据右手坐标系来定方向,保持手掌、四指与大拇指相互垂直,将手掌与四指分别对应两个向量,一比划,就得到大拇指的方向,大小就按照sin这个公式算出来。
有些特殊的向量,比如零向量就对应线性空间里面的原点;单位向量就是长度是一。还有概念叫正交,简单理解就是空间中两个向量相互垂直。垂直怎么判断?就是两个向量作内积,公式里有个cosθ,θ如果等于90度,结果就是零;这就是正交。
关于向量长度,有个度量方法:范数。向量长度按照范数来度量,分别对应不同的表达式。
L1范数,它会取每一个元素的绝对值,然后求和;
L2范数,L1的绝对值变成平方,外层开方;
还有P范数,这里面的P数值是自己指定的;
F范数一般只适用于矩阵,里面每一个元素取平方,然后再求和。
可见,P范数是一般形式,p=1或2分别对应L1和L2(对应于机器学习里的L1、L2正则)

矩阵相关概念。
同型,如果两个矩阵A和B同型,那么A和B的维度是一样的,比如说A是M×N,B是X×Y,那么M等于X,N等于Y,这是关键;
方阵就是,对于一个M×N的矩阵,M等于N就是个方阵。
单位矩阵,对角线全部都是1;
对称,转置后矩阵不变;
秩和迹。秩对应的一个概念叫线性表出,也就是矩阵里面的每一行或者是每一列,选定一个方向(要么是行要么是列),取其中一列,跟其他的列做加减和数乘(只能是这两种操作),其中任意一列要不能由其他列的线性表出。现在听起来可能不太好理解,可以暂时放放。
行列式,就是在矩阵外面,比如说这个3×3的矩阵,在外面取两边各加一条竖线,这就表示行列式;怎么算呢,每一行、每一列分别取一个数,相当于这里面三个元素全排列,之后再乘上一个逆序数(逆序数是指每组元素原始下标顺序,如果是逆序,就乘-1,把这所有的逆序数乘上去,最后就得到了一个方向,也就是行列式里面是正号还是负号)。
逆矩阵,就是矩阵A乘以某个矩阵后得到单位阵,这个矩阵就是逆矩阵;
伪逆矩阵是逆矩阵的一种扩展;
正交矩阵就是每行每列都是单位向量,特性是AAt=I。
刚才的内容,可能不好理解,不过大家都学过线性代数的基本课程,还是能够回忆起来的。后面第二部分再给大家解释一下为什么会有这些东西。
矩阵运算,除了传统的矩阵乘法,还有一种特殊的乘积,这个就是对应元素乘积,它的表示方法是不一样,中间加个圆圈;两个矩阵(必须同型)对应元素相乘,得到一个新的矩阵,也是同型的。

我们看一下矩阵乘法。从右往左看,这个是作者(Ian Goodfellow)PPT里的一张图,老外的思维是从右往左看。这里是3×2的一个矩阵,和2×4的一个矩阵,两个矩阵相乘,就是两个矩阵中分别取一行和一列依次相乘,得到左边的矩阵。

范数的目标就是衡量矩阵的大小。有很多种类别,但不是什么函数都能当做范数的,有些基本的要求:比如必须要保证有一个零值,然后还要满足三角形不等式,也就是三角形两边之和大于第三边,还有数乘,对应的是等比例缩放。缩放就是一个函数乘以一个实数,这是一个线性空间里的基本运算。

这是P范数的表达式。其实P范数具有一种泛化的表达式,是一种通用的方式,可以包含L1、L2,还有无穷范式,这些都是由P的取值决定的,可以等于1、等于2、等于无穷。

行列式的计算方法比较复杂,公式我就不列了。直接给出直观理解:衡量一个向量在经过矩阵运算后会变成什么样子,即线性空间上进行了某种放缩,可能是放大或者缩小,缩放的倍率就是行列式值;行列式的符号(正或负),代表着矩阵变换之后坐标系的变化。
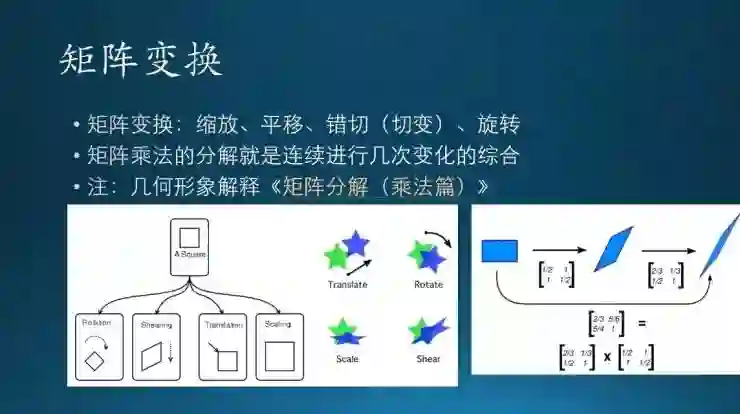
矩阵变换里面有这么几种,平移、缩放等等。这个后面再说,免得重复。

矩阵分解:
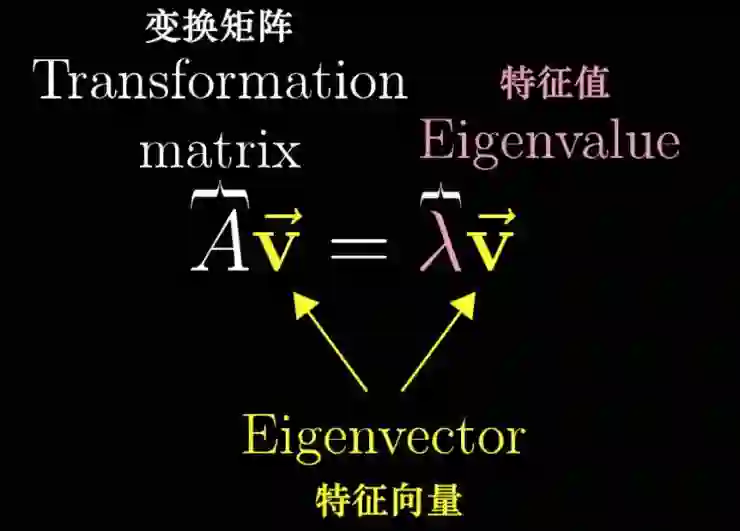
(1)特征值分解,是我们常规见到的。有一个定义,比如我们定义一个矩阵A,乘以一个向量得到的等于另外一个数字乘以同一个向量,Av=λv。满足这个表达式,就叫做矩阵的特征值分解,这是矩阵分解典型的形式。这个v就是一个特征向量,而这个λ就是特征值,它们是一一对应的(出生入死的一对好基友)。符合表达式可能还有其他取值,每一个矩阵A会对应多组特征向量和特征值;矩阵A的所有特征向量和特征值都是一一对应的。
如果矩阵是一个方阵(不只M等于N,还需要保证这个矩阵里面每一行、每一列线性无关),可以做这样的特征分解,把A分成了一个正交矩阵乘对角阵乘同一个正交矩阵的逆。对角阵是把每一个特征向量一个个排下来。
还有个概念叫正定,是对任意实数,满足xAxt>0,就叫正定;类似的还有半正定,大于等于0是半正定;负定就是小于零。
(2)奇异值分解,是矩阵特征分解的一种扩展,由于特征分解有个很强的约束——A必须是一个方阵。如果不是方阵怎么办呢,就没有办法了吗?有的,就是用SVD奇异值分解,这个在推荐系统用的比较多。

这是特征分解的示意图。从直观上理解,这个圆上面的两个向量V1、V2,经过矩阵变换之后在两个特征方向上进行缩放:在V1方向上面缩放λ1倍,变成了新的V1;V2在V2的方向做了λ2倍的缩放,变成新的V2。这两个特征,构成了完整的矩阵分解,也就是经过一个线性变换之后得到的效果——在特征向量方向上分别缩放特征值倍。

SVD分解就是一个扩展形式,表达方式就这样,不细说了。
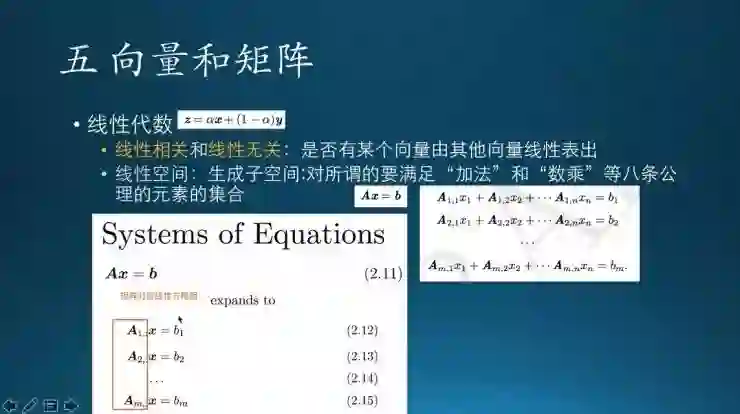
向量和矩阵这两个组合起来就可以解决常见的线性方程组求解问题。
这里有几个概念,一个叫线性组合,就是一个矩阵,里面的一行或者一列,实际上就是多个向量,通过简单的加减还有数乘,组合出来一个新的向量,这叫线性组合。如果用基向量X1、X2执行加法和数乘操作,得到的是x3=k1*x1+k2*x2,一组向量组成的线性空间,即由X1、X2组合成的向量空间,就叫生成子空间。
如果对两个向量X和Y,可以按照α和1-α这两个数乘组合起来生成一个新的向量,这个叫线性表出,就是Z向量由X和Y进行线性表出,然后α和1-α都是一个数值,满足这个关系就叫线性相关。这就是说Z和X、Y是线性相关的,如果不满足,如果Z这个向量不能这样表出,就叫线性无关。
这是矩阵对应的一个线性方程组。这是一个矩阵,现在像右边这样把它展开,就是矩阵和线性方程组是对应的。这个挺常见的我不就不多说了。

矩阵方程组的求解是,把方程组每一个系数组成矩阵A,根据A这个矩阵本身的特性就可以直接判断这个方程组有没有解、有多少解。还有无解的情况。

这是矩阵方程组的一些求解,比较常规的,像AX=b这个线性方程组一般怎么解呢?常规方法:两边直接乘A的逆矩阵。它有个前提:A的逆必须存在,也就是说A里每一行、每一列不能线性相关。这种方法一般用于演示,比如算一些小型的矩阵,实际情况下,A的规模会非常大,按照这种方法算,代价非常大。

再看下什么矩阵不可逆。一个矩阵M×N,按照M、N的大小可以做这样的分类:如果行大于列,通常叫做长矩阵,反之叫宽矩阵;行大于列,而且线性无关,就是无解的情形。宽矩阵有无数个解,其中,每一列代表一个因变量,每一行代表一个方程式。

伪逆是逆的一种扩展,逆必须要求A这个矩阵式满秩,就是没有线性表出的部分。如果不满足,那么就得用伪逆来计算,这只是一种近似方法。SVD这种方法比较厉害,因为支持伪逆操作。
应用案例里,书里面只提到一个PCA,线性降维,也没有详细的展开。其实书里很多章节都提到了PCA,所以我也给大家普及一下基本概念。

这个是PCA在图像上面的应用。这张图非常经典,凡是学过数字图像处理的都知道她——Lenna(提示:别去搜lena的全身图,~~~~(>_<)~~~~,好吧,不卖关子了,老实交代:这是图像处理专家喜欢的一个舞女,养眼,图案灰度也鲜明,于是歪打正着成了著名样本,参考cmu网站上的「The Lenna Story」)。原图像经过主成分分析降维之后就变成右边的图,可以看到大部分信息都都还在,只是有些模糊。这个过程叫降维,术语是图像压缩。
看一下PCA的基本过程。PCA的思想是,原来一个矩阵有很多列,这些列里可能存在一些线性关系,如何把它降成更小的维度,比如说两三维,而且降维之后信息又能够得到很大程度的保留。怎么定义这个程度呢?一般是累计贡献率大概85%以上,这些主成份才有保留意义。这个累计贡献率是通过方差来体现的,样本分布带有一定的噪音或者随机分布,如果是在均值的左和右两个方向进行偏移的话,不会影响方差。方差等效于信息量。

这张图解释主成分分析的过程,用的是特征值分解,一个X的转置乘以X,然后对它做各种复杂的变换,大家看看就行了,想了解细节的话自己去找资料,具体过程一时半会儿讲不清楚。PCA最后有什么效果呢?看中间的坐标系给出示意图,原来的矩阵取了X1和X2两个维度,把样本点打出来能看到近似椭圆分布,而PCA的效果就是得到一组新的坐标系,分别在长轴和短轴方向,互相正交,一个方向对应一个主成分。实际上,数据特征多于两维,图里只是为了方便观察,这样就完成了一个降维的过程。
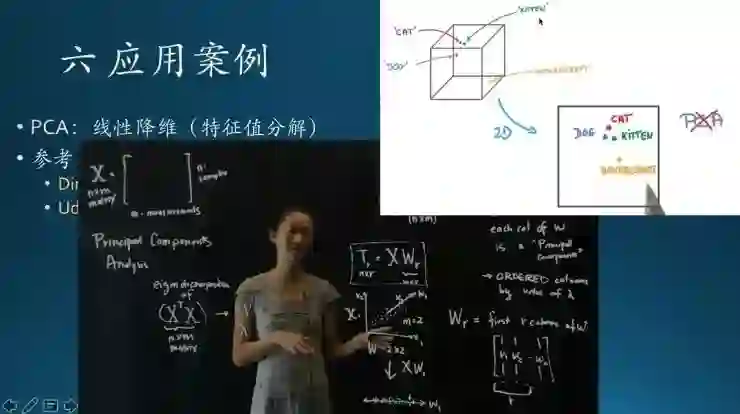
右上是一个示例,有一些动物样本,狗、小猫,还有个气垫船(非动物)。在特征空间里面显示成这样,理论上,动物会靠得比较近,非动物会远离。如果用PCA来做,可能得到的结果是这个样子,动物跟非动物区分的不是很明显。所以,PCA实际上只能解决一些线性问题,非线性情况下,解决的效果不太好。
怎么办呢?用非线性降维方法。典型的方法比如说t-SNE(t分布-随机近邻嵌入),流形学方法。

流形简单来说就是很多面片叠加形成的几何图形。基本假设是,同一个数据集中每个样本会近似服从一定的内在分布,比如说空间几何体里的圆形或球面,甚至正方形,都本身有一定内在结构。流形就是试图用非线性的方法找到内在结构,然后把它映射到低维的空间里面去。这个好像要讲深了,我先不做扩展(涉及拓扑几何)。后面好几个章节要提到流形,流形这个概念是需要了解的,后面自编码器章节还会提到。

这是一个复合、螺旋形的数据集,在空间里面显示出来是这个样子,用线性方法是不可能分开的。流形怎么办呢?近似于找到一种非线性的方法,假设这两个小人,把它拉伸,拉开之后,不同的类别就能够分开了。流行学习就相当于这两个小人把二维流形拉平了,从非线性的变成线性的。

这个图说的是PCA,2006年之前这种方法是非常实用的,一旦提到降维首选是PCA。基本思想就是在数据集里面方差变化最大的方向和垂直的方向选了两个主成分,就是V1和V2这两个主成分,然后对数据集做些变换,它是线性的。
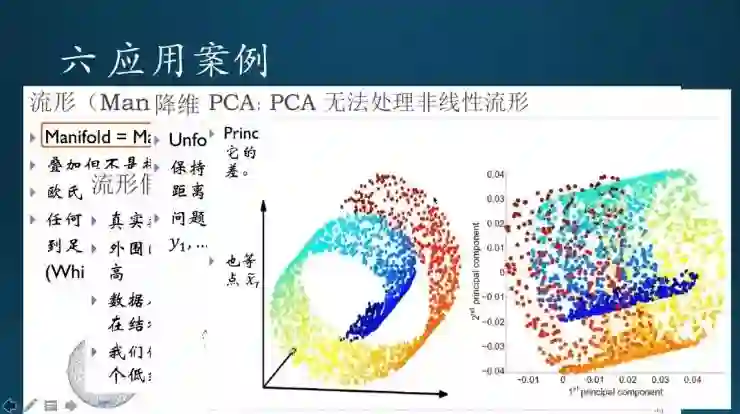
非线性分布的情况,PCA是不行的,其他的线性方法也是不行的,必须用非线性。
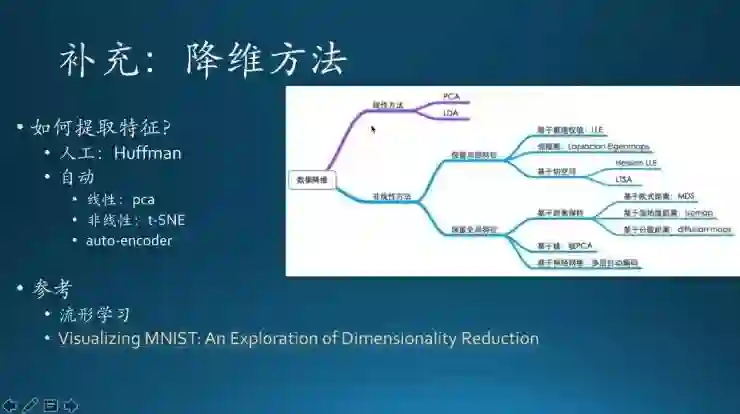
这里要提到降维方法,降维其实用到的相关方案是非常多的,主要分成两类,一类是人工的方法,像信息论里面有一个霍夫曼编码,霍夫曼编码也算是一种降维,它是一种可逆的方法;然后还有其他的自动化方法,因为人工毕竟是代价比较大的,所以需要找自动化方案,比如PCA,非线性的t-SNE,还有后面的自编码器等等。
下面这张图概括了常用的数据降维方法,线性方法有PCA、LDA,非线性的方法又分成保留局部特征和保留全局特征,再往下有很多很多,大家去自己去了解。
不过,图里没有提到t-SNE,因为t-SNE是新出来的,2012年左右开始流行起来的,它其实是Geoffery Hinton团队发明的,现在的用途主要在高维数据的可视化上。

像这样一个数据集,在三维空间里面,它是一个服从球面分布的一个数据集,然后用不同的非线性方法进行降维,总体上还分的还是不错的。不同的颜色它分得比较清,没有大的混杂,基本上可以的。

再看一个,这是S型的结构,经过这几种非线性的方法进行降维之后,也分得比较清楚。

拿MNIST数据集来说明。MNIST是手写数字的一些图片,按照行方向拉伸成一维向量。因为这个图片是28×28的,所以拉伸成的一维向量是784维。由于维度比较高,人能直观看到的基本是二维或者三维的,所以这里面取两个像素点,比如图像里面第18行第15列这一个像素点,还有第7行、第12列这个像素点。然后一个X轴、一个Y轴可视化一下,看它的区分度怎么样。显然从这个结果上看不怎么样,不同的颜色都分的比较零散;所以直接取其中的几个像素来分,分不清。

那么看一下PCA是什么样的效果。它会把里面784维做一个降维,然后取了两个主成分,X轴Y轴是两个主成份。跟上面一张图相比,效果还是挺显著的,周围颜色已经比较靠近。但是中间一坨就不行了,这是它的局限性,部分的分割效果还行。
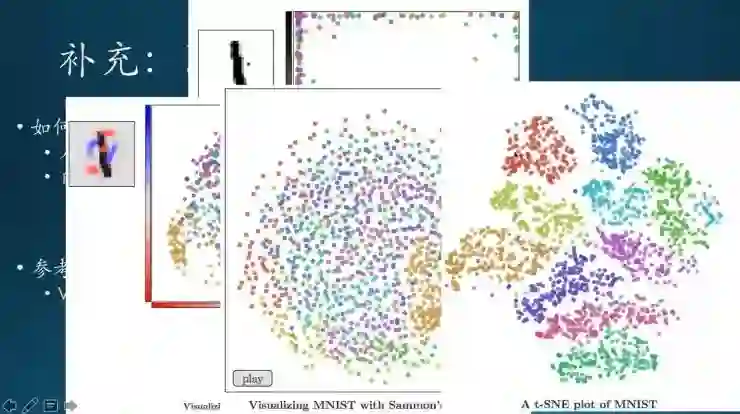
看着好一点的是t-SNE,明显跟上面不是一个量级的,不同的颜色聚合的比较紧,而且不同颜色之间还有一些分隔线,这些区域还非常清晰,这就是它厉害的地方。t-SNE在非线性降维里面绝对是排名第一的。
刚才讲的是第一部分,多而杂、浅显、不好懂,实际上这本书也是按照这个传统思路来讲的。数学本身就很抽象,但是,能不能变得更加形象一点呢?可以的。
第二部分:直观理解

传统的教学方法,从初高中到大学,不少老师拿着书上的概念,堆公式、只灌输、不解释,也不会告诉你这个运算到底有什么几何意义,看完之后记不住。这就是为什么很多人觉得以前都学过,甚至拿了高分,但是现在好像都还给老师了。没有从感性上去理解透的知识点,背的再多,随着时间推移,也都会忘记。

所以接下来换一种方式。进入第二个环节。

我就参考一些资料,比如说第一个是Essence of Linear Algebra,这是国外高手(3Blue1Brown,非盈利,接受捐助)制作的教学视频,可以去YouTube上看,bilibili上也有中文的翻译版,优酷也有了。这个教程非常好,全部用视频可视化方法直观讲解线性代数。第二个是马同学高等数学,几篇公众号文章也很好,跟3Blue1Brown不谋而合。毫不夸张的说,看完这两个教程后,你会有一种相见恨晚、醍醐灌顶、重新做人的感觉。下面是视频里的几个观点:

事实上,国内外传统教学里一直把人当机器用,各种花式算行列式,不胜枚举,然而没有告诉你是什么,为什么?

很多人对数学有种与生俱来的恐惧感,不怪你,是某些老师把简单问题教复杂了,让你开始怀疑自己的智商,认定自己不是学数学的料,于是,见到数学就避而远之。
对于初学者来说,良好的解释比证明重要得多。

下面切换我的有道笔记:《线性代数笔记》。http://note.youdao.com/noteshare?id=2dd5b67042a5a49bd81a450c0a7490be
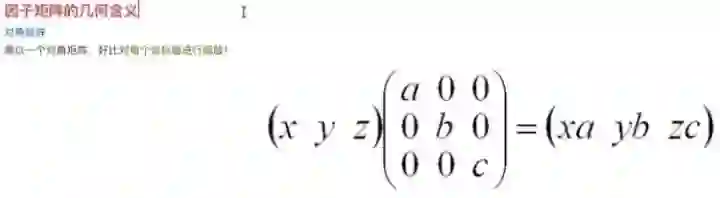
刚才说的有矩阵是吧?我们来看一下矩阵到底在干嘛。这个(x y z)这是一个向量,一个矩阵对它进行变换之后变成了(ax by cz),对应的就是把原来的X、Y、Z三个方向分别作a、b、c放大。
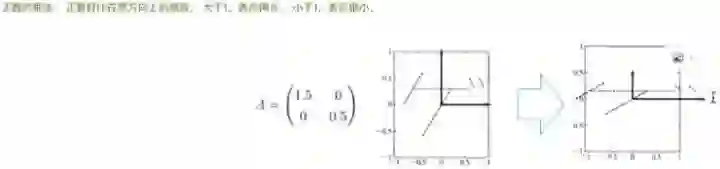
在图上面怎么理解呢?看这个,这是一个矩阵,来看着坐标系的变化。这个是在X轴方向做1.5倍的放大,这是在Y轴的方向上做缩小到一半,效果就是这样子。X轴Y轴都做了一个缩放动作,对应的轴上面的坐标和点也要做这样的缩放,整个空间都被拉伸了,X轴方向被拉伸,Y轴方向被压缩。

假设取这些二维平面上的样本点,变化完之后就成这样的。X的范围从-1到1,变成了-1.2到+1.2,也就是在X方向做1.2倍的放缩,Y轴方向1.3倍的放缩(样本点之间距离拉开了)。
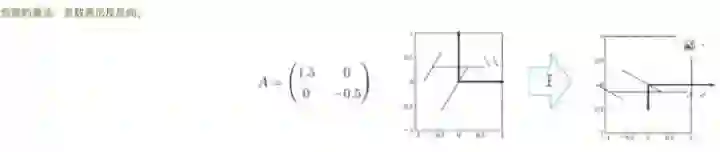
如果这里面有一个负值又是什么概念呢?就是轴方向的变化(术语:手性变化,比如左手变右手)
比如这个Y轴的有一个负号,刚才是0.5,现在是-0.5,那就是把Y轴往下翻,负号就是反向,类似一个镜面反射。如果X也是负的话,就是相对于坐标原点的中心对称。
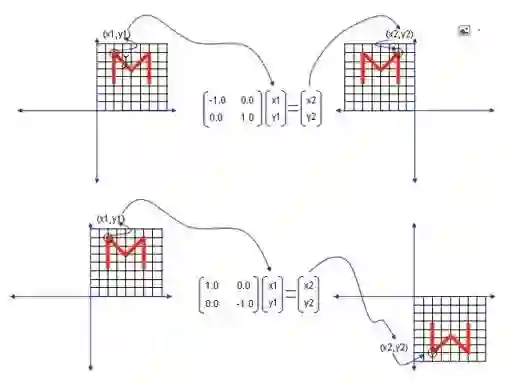
这里面放一个图形,看起来会更加直观一些。M这个形状的数据集,经过这个变换之后成这样。对角线的第一个元素是作用在X轴上面的,X轴沿着Y轴作了一个对折,也就是镜面反射,原来M在这儿,翻过来到这,就是这个矩阵的作用;Y轴上没有任何变化,因为是1,不放大也不缩小。第二个里Y轴是负数,那么反过来就是沿着X轴翻一下。
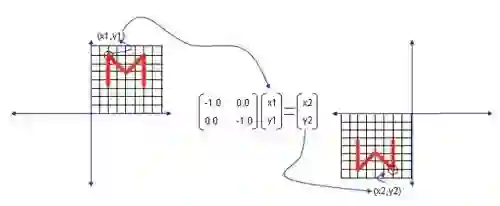
如果两个都是负,那就是中心对称,从第一象限翻到了第三象限。

如果里面有这样情况,这就是矩阵不可逆的情况,它的行列式是0。0的话会有什么变化?原来这是一个坐标系,到这里变成一条线了,这就是做了一个降维操作,把两维的变成一位了。那一位能返回去吗?不可能的,所以这叫不可逆。
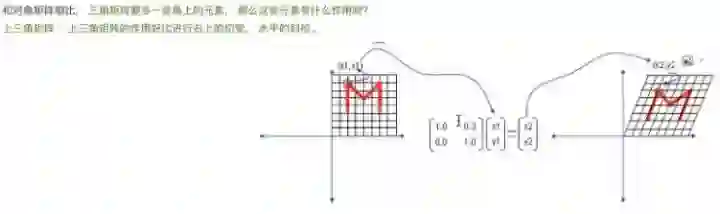
这个跟刚才相比的话,多了右上角一个元素0.3,这是一个上三角矩阵,是什么意思呢?看一下图的结果,沿着Y轴方向是不变的,X方向就做了一种错切,也叫推移。形象理解就是站在上面,然后把箱子往这边推,底部是不动的,那么就有一个推移的动作。为什么会这样?大家可以拿这个矩阵,随机取一个点去感受一下。
第一行始终作用在X轴方向上,它跟原来相比加了一项。说明X轴方向做了追加,把Y轴的信息拿过来追加延长X轴,而Y轴没有变化,所以Y是不变的,X是要做拉伸的。
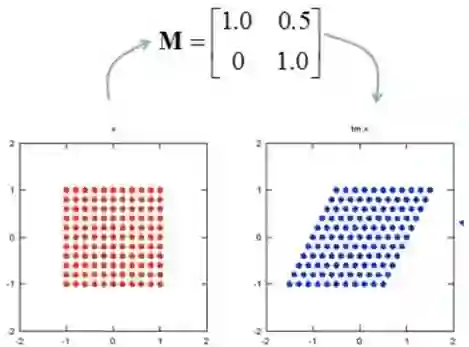
红色的这个矩阵变到蓝色就有一种错切,有一股力从左边往右推。
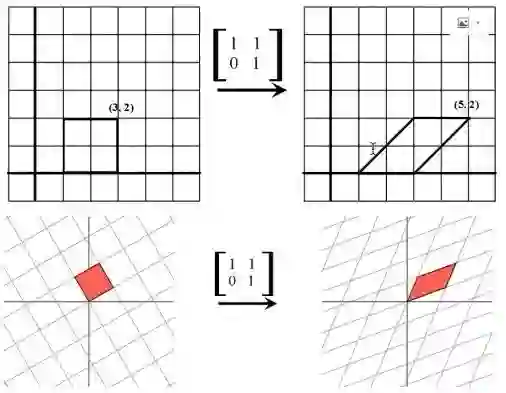
这也是推移以后的效果。
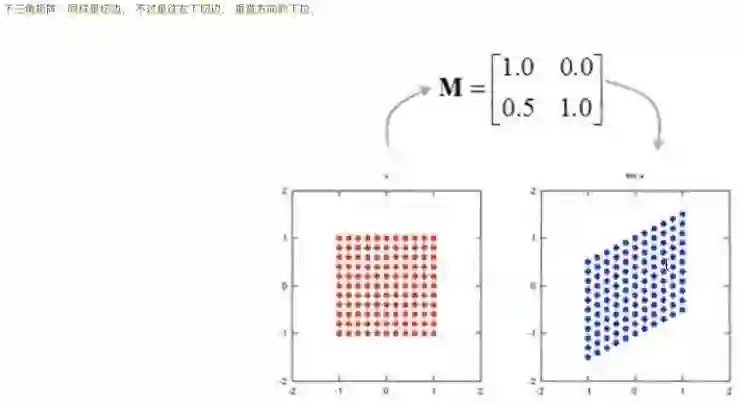
刚才说的是上三角,然后变成下三角怎么样?那就是反过来,X轴不变,沿着Y轴方向推移,到这儿。
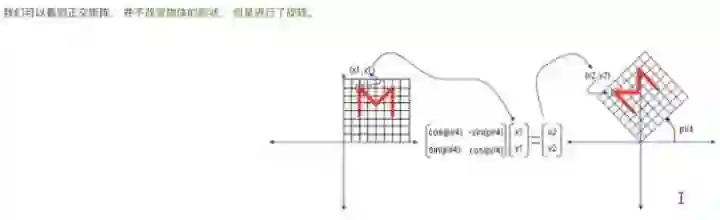
好,这一部分讲的是旋转。M通过这个矩阵就进行了旋转,这是个正交矩阵,正交就是矩阵行列式的值为1,意思是说是X和Y轴是不做任何缩放的,只做以原点为中心的旋转。这就是做一个旋转,按照π/4的角度做旋转。
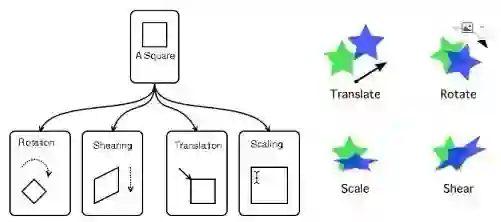
刚才说了几种变化,第一个旋转,第二个错切,第三个平移,加上缩放。线性变换里不包含平移;线性变换加上平移的话,那就是仿射变化。
那么到底什么是线性变换?线性空间的任意点在变化前后一直保持等距分布!

下面不是线性变换,因为距离不等。

矩阵分解是说,每一个矩阵都是由这几种基础的变化组合而成的。这部分过了,有点难度。数学分析里这门课讲到矩阵的话,运算代价非常大的,怎么让计算机跑起来更快呢,就做矩阵分解,把一个大矩阵分成几个小矩阵,算起来更快。矩阵分解的一个基本目的就是提高计算效率。

接下来讲矩阵的特征值和特征向量。先有直观概念,特征向量反映的是经过这次变换之后它的变化方向;特征值反映的是变换的幅度。为什么会这样?往下看。
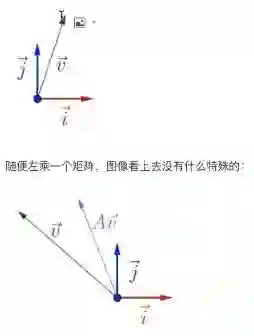
这是一个坐标系X和Y,上面有一个向量,或者说二维平面上的一个点,乘以一个矩阵之后变成这样了。
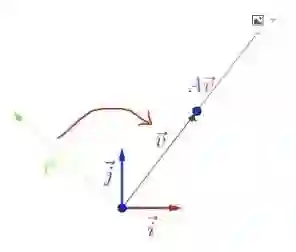
再乘以另外一个矩阵可能变成这样。看看图像区别的话,v乘它之后仍然在这个方向上;变换前后的差别就是方向不变,只是大小做了拉伸。如果符合这样的情形的话,那么λ就是A的一个特征值,v就是A的一个特征向量。A矩阵可能还有其他的情形,可能还有其他一些特征值和特征向量。矩阵特征值分解的效果,就是对一个矩阵A,在平面上找到所有满足这种关系的向量集合。
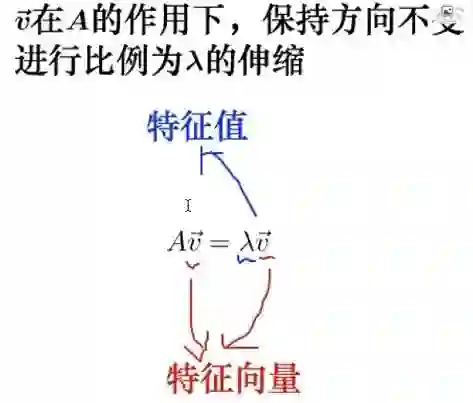
这就是特征值表示的一些传统公式,A矩阵乘以一个向量,得到一个特征值乘一个向量,反映的就是在v的方向上面拉伸了多少倍。这就是通过特征值分解揭示矩阵本身的特性。
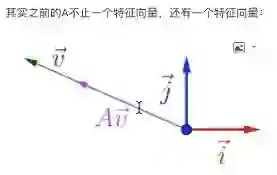
刚才提到一个特征向量和一个特征值,还有没有其他的?有的,这个也是,这个V就是它的一个特征向量,长度也对应一个特征值,这是A矩阵的两个特征值。
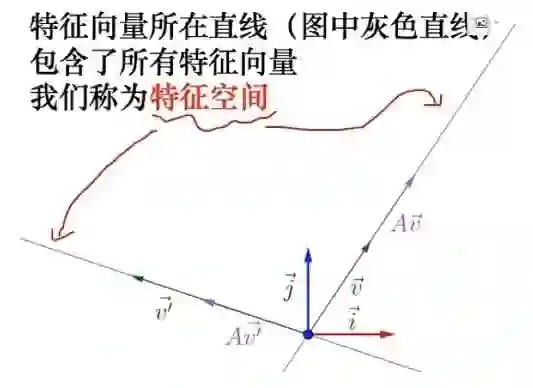
A矩阵对应的两个特征向量和两个特征值,如果对特征向量做数乘,比如拿这个V1乘以2、乘以3;每一个特征向量经过数乘操作组成的空间叫做特征空间。

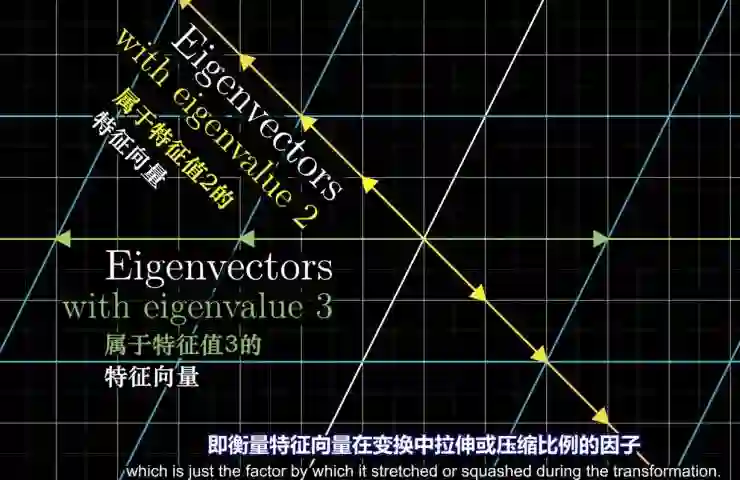
这里有一种近似的、形象的表述,就是矩阵是一种运动。运动在物理里面运动就有两个概念,第一个往哪走,第二个走多少,对应的是速度加上方向。
运动是动态的,点表示瞬时的状态。站哪个位置是静态的,要观察到运动必须要借助一种实体,比如说要观察跑步现象,总得要找个实物,比如看人跑、还是看猪跑、看老虎跑,你总要找个物体附上去才能够看到它的变化过程。
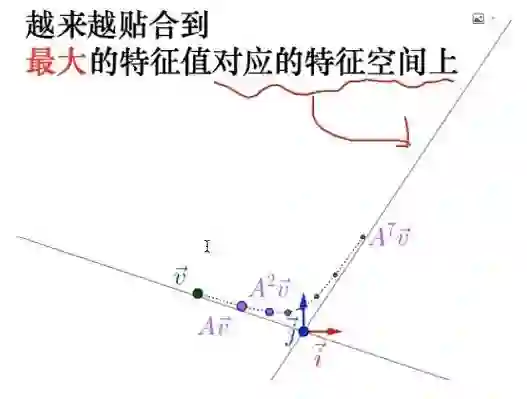
对同一种运动,A代表这种运动,如果应用到一个向量上面多次,它会产生什么样的变化?像A这个矩阵是一种变换,作用到V这个特征向量上,一次得到的点是在这儿,两次到这,三次四次跑到这边来了。7次就沿着这个方向,然后如果8次、9次仍然这个方向。这里有种奇怪的现象,就是对一个向量做线性变换,N次以后它会趋近于一个方向走,就不会再继续变方向了。
这个方向实际上是有一定的意义的,这个方向就是矩阵分解的最大特征值对应的方向。简单说就是反复利用矩阵乘法都会有一个最明显的特征,就是整个运动方向会朝着矩阵的最大的特征向量方向走,这是它的几何解释。在一般的代数里面,可能你根本想不到这一点。

补充:这是我自己补充的,一开始向量往这个方向走,变化特别大,这都反映的是矩阵本身的特征值,贫富悬殊非常大。两个不同方向上的特征值,一个是另一个的很多倍,它们的悬殊非常大。这种情况叫有一种术语叫病态,它的衡量是通过条件数,条件数的概念就是一个矩阵的最大特征值与最小的特征值之间的倍数。最大特征值除以最小特征值得到的倍率比如是3,还可以是10,肯定是10的时候病态更严重,已经病得无药可救了。
对这种矩阵做变换的话,你就要特别小心。在梯度下降里面如果碰到这种矩阵的话,很容易在整个优化空间里不停地震荡,很难收敛。

接下来看特征分解。这一个矩阵分解完之后,中间是个对角阵,对应的就是每一个特征值。像A这个矩阵,做一个特征分解之后,两个特征值是3和1,然后左边右边对应的就是一个特征向量。比如说左边矩阵的第一个列向量就是3这个特征值对应的特征向量,不信你可以试一下。
同理,左边矩阵的第二个列向量就是1对应的特征向量.这就是一一对应的特征向量。左右两个矩阵相比就是做了个转置而已。另外矩阵里是正交向量,左右的矩阵只会做旋转,不会做缩放;中间的对角矩阵有缩放。所以整个A矩阵的作用既有旋转又有缩放。
所以特征值是一种拉伸,衡量沿着特征向量的方向拉伸多少;然后特征向量就是拉伸的方向。所以到现在应该比较好理解我们上来就说的那句话,叫特征值和特征向量就对应运动的速度和方向。

这个部分是讲矩阵的秩和线性方程组之间的关系。Ax=b这样一个线性方程组,它有唯一解的充要条件是矩阵的秩,等于它的增广矩阵的秩,等于N。这也就是说满秩,满秩的方程才有解;无解的条件就是它的矩阵的秩小于增广矩阵,简单说就是A不是满秩的,或者它是不可逆的;如果有多种解呢,像这样加上增广矩阵之后仍然小于N。这是数学上的表达,但还是不够形象。
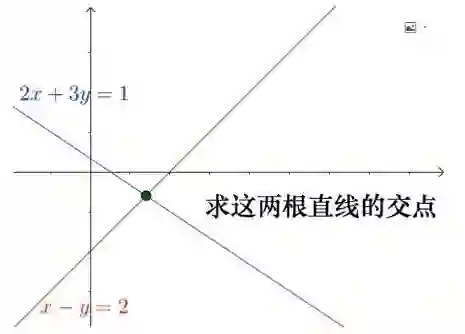
那么现在形象理解一下,我把线性方程组做下简化,变成二元线性方程组。方程组画在空间里面就是两条直线,同时满足这两个方程组的解,就是两条直线的交叉。只有这一个点同时满足这两个方程,直观地看出来这是唯一解。所以这么理解的话,唯一解就是有且只有一个交点;无解的话,把一条直线变得和另一条平行,两条直线根本就没有交点,就是无解;有很多解呢,就把平行的直线往一起靠,叠加在一起,完全重合了,那么解就可以很多很多,因为直线可以包含任意无穷多的点。

看一下,矩阵解线性方程的几何意义。这个空间上面X轴Y轴,取了一组正交基i=(1,0)和j=(0,1),然后空间里的点就可以ai+bi来表示,a、b是任意实数,这就是i和j张成的线性空间。

这个如果i和j共线,就是说i和j可以通过i=kj这个方式表达的话,就是共线。共线就相当于是一个降维操作,把原来的二维空间变成了一维的,这是不可逆的。
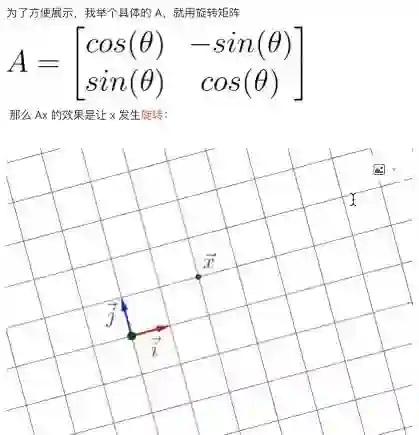
A是这个矩阵在对整个的方程的线性空间做变换,就是旋转。整个变换过程里,X点相对于变换后的这个坐标系是没有变化的,相对位置没有变化,但是相对于原来那个坐标系就发生了变化。
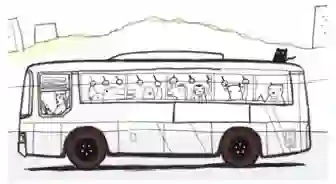
用形象的方法理解,好比我们去坐公交车,车在动,我们也在动;我们相对于车是静止的,但是我们相对地面是运动的。我们相对与地面运动的过程就是一个矩阵对一个向量做变化之后的效果,像这样。
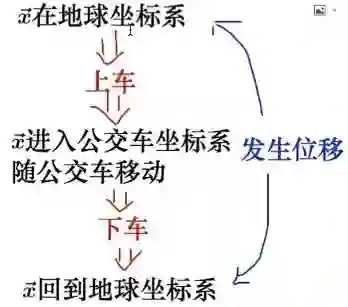
地球坐标系就相当于地面,上车,再返回地球,就发生了位移。这个变换对空间里面每一个点都发生了变换。

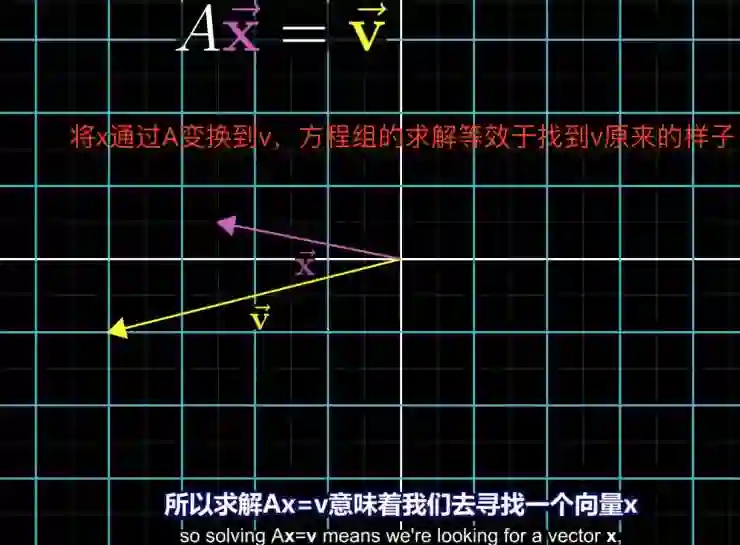
回到线性方程组。Ax=b是线性方程的一种表示,它的形象解释就是找到这样一个向量,它在线性变换之后变到了B点,我们要找到x,就是b原来的样子,是一个可逆的操作。这就是线性方程组的含义。

这一部分是我自己补充的。
比如刚才说从x到b,能不能从b回到x呢?如果可以,那就是可逆,对应的A这个变化是可逆的;如果不能,那就是不可逆。
这个不可逆,又是怎么理解?这就是一种降维打击,比如说把一个立方体拍成一个平面,像一张纸;然后把纸揉成一个团,然后再直接打到十八层地狱。这些就是降维打击,是不可恢复的。
不可逆的时候怎么办,想尽可能回去,有点偏差也行。伪逆就是这样的时光隧道(变成冤魂野鬼,回到当初的地点),对逆做一个扩展。一般的线性方程组里面有很多样本,点非常多;矩阵是不可逆的,那就求他的最小二乘解,让这条直线尽可能靠近所有点,这就是一种近似的方法,也就是不可逆,但是我们尽可能让他回去(中国人深入骨髓的思想:落叶归根)。
还有个概念,既然有降维,那就有升维。升维该怎么理解呢?假设从北京到西藏,要坐火车,时间很长,可能两天三夜,很累。但是有钱人,直接坐飞机嗖的一下就到了,这就是升维。飞机飞行的路线在垂直高度上是有差别的,火车的高度全程差别不大。(不同维度下的生活方式不同,有个笑话:“等我富了,天天吃包子!”,富豪的世界你不懂,乞丐的世界,你也不懂)
特征分解怎么理解呢?公交车沿着既定路线走,先往东两千米,再往西三千米,然后再往东北五千米,然后就到家了。这里的方向就是特征向量,走的幅度两千米、三千米、五千米就是特征值。行列式是什么意思?就是这个路线的长度。这样理解应该就直观得多了吧。
行列式大于零有放大的作用;行列式等于0是降维的作用,不可逆的;行列式小于零,是在坐标系上面做了一个反射。注:行列式和特征值与坐标系无关,反应的是矩阵本身的特质。

这是2×2的一个矩阵,我们看一下改变行列式的大小会有什么效果。当行列式是大于1的,就有一个放大作用;如果我调小行列式的值,就缩小,然后到1是不变的;在0到1这个范围内就缩小;注意看这一点,如果等于0的话就降维了,变成一个点了;再往右边,行列式是负数,A和B翻过来了,沿着Y轴把X轴往这边反射;然后缩放的情况跟正像方向是一样的。这个过程就好理解,这叫行列式的几何意义。
最后以一张图结束:

AI 科技评论整理。感谢王奇文嘉宾的分享以及帮忙补充校对本文。
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————