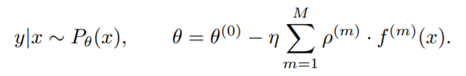选自arXiv
作者:
Tony Duan、Anand Avati等
在此论文中,来自斯坦福的研究者们提出了
NGBoost 梯度提升方法以解决现有梯度提升方法难以处理的通用概率预测中的技术难题。
自然梯度提升(NGBoost / Natural Gradient Boosting)是一种算法,其以通用的方式将概率预测能力引入到了梯度提升中。
预测式不确定性估计在医疗和天气预测等很多应用中都至关重要。
概率预测是一种量化这种不确定性的自然方法,这种模型会输出在整个结果空间上的完整概率分布。
梯度提升机(Gradient Boosting Machine)已经在结构化输入数据的预测任务上取得了广泛的成功,但目前还没有用于实数值输出的概率预测的简单提升方案。
NGBoost 这种梯度提升方法使用了自然梯度(Natural Gradient),以解决现有梯度提升方法难以处理的通用概率预测中的技术难题。
这种新提出的方法是模块化的,基础学习器、概率分布和评分标准都可灵活选择。
研究者在多个回归数据集上进行了实验,结果表明 NGBoost 在不确定性估计和传统指标上的预测表现都具备竞争力。
![]()
链接:https://arxiv.org/pdf/1910.03225v1.pdf
很多真实世界的监督机器学习问题都具有表格式的特征和实数值的目标。
但模型很少应该对预测结果有绝对的信心。
在这样的任务中,估计预测结果中的不确定性就很重要了,尤其是当预测结果与自动化决策直接相关时——因为概率式不确定性估计在确定工作流程中的人工后备方案方面非常重要。
气象学已经将概率式预测用作天气预测的首选方法。
在这种设置中,模型会根据观察到的特征输出在整个输出空间上的概率分布。
模型的训练目标是通过优化最大似然估计(MLE)或更稳健的连续分级概率评分(CRPS)等评分规则来最大化锐度(sharpness),从而实现校准。
这会得到经过校准的不确定度估计。
而梯度提升机(GBM)是一系列能很好地处理结构化输入数据的高度模块化的方法,即使数据集相对较小时也能很好地完成。
但是,如果方差被假定为常数,那么这种概率式解释就没什么用处。
预测得到的分布需要有至少两个自由度(两个参数),才能有效地体现预测结果的幅度和不确定度。
正是这个基础学习器多个参数同时提升的问题使得 GBM 难以处理概率式预测,而 NGBoost 通过使用自然梯度能够解决这个问题。
这篇论文提出了自然梯度提升,这是一种用于概率预测的模块化的提升算法,其使用了自然梯度,从而可以灵活地整合不同的以下模块:
基础学习器(比如决策树)
参数概率分布
评分规则(MLE、CRPS 等)
NGBoost 算法是一种用于概率预测的监督学习方法,其实现提升的方式是以函数形式预测条件概率分布的参数。
研究者这里的实验关注的重点是实数值输出,但他们也表示这些方法全都可用于其它模式的预测,比如分类和事件发生时间预测。
基础学习器(f)
参数概率分布(P_θ)
合适的评分规则(S)
对新输入 x 的预测 y|x 是以条件分布 P_θ 的形式完成的,其参数 θ 通过 M 个基础学习器输出(对应于 M 个梯度提升阶段)与一个初始分布 θ(0) 的叠加组合得到。
注意 θ 可能是一个参数向量(不限定于标量值),这些参数完全决定了概率预测 y|x。
为了得到某个 x 的预测结果参数 θ,每个基础学习器 f 都以 x 为输入。
预测得到的输出使用一个特定于阶段的缩放因子 ρ 和一个通用学习率 η 进行缩放。
![]()
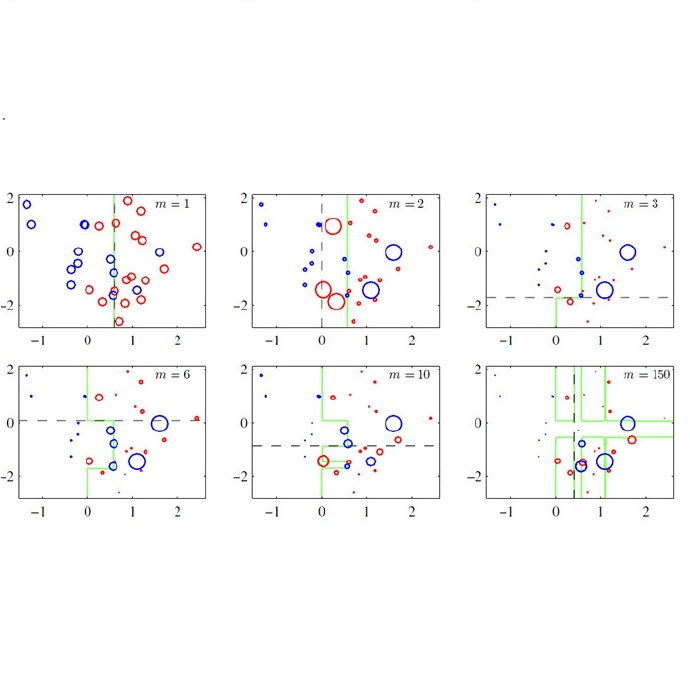
模型是按序列形式学习的,每个阶段都有一组基础学习器 f 和一个缩放因子 ρ。
学习算法首先会估计一个共同的初始分布 θ(0),这样使它能最小化评分规则 S 在所有训练样本的响应变量上的总和,这本质上就是拟合 y 的边际分布。
这就变成了所有样本的初始预测参数 θ(0)。
在每次迭代 m,对于每个样本 i,算法都会根据该样本直到该阶段的预测结果参数计算评分规则 S 的自然梯度 g_i。
注意 g_i 和维度与 θ 一致。
该迭代的一组基础学习器 f 将进行拟合,以便预测每个样本 x_i 的自然梯度的对应分量。
拟合后的基础学习器的输出是自然梯度在该基础学习器类别的范围上的投射。
然后,通过缩放因子 ρ 对投射后的梯度进行缩放,因为局部近似可能离开当前参数位置后不久就会失效。
选取缩放因子的标准是以线搜索的形式最小化沿投射梯度方向的整体真实评分规则损失
![]()
实验使用的数据集来自 UCI Machine Learning Repository,并遵循了 Hernández-Lobato 和 Adams (2015) 最先提出的协议。
所有数据集都随机选取了 10% 作为测试集。
在另外的 90% 中,首先先保留 20% 作为验证集,以选择能给出最佳对数似然的 M(提升阶段的数量),然后再使用所选的 M 重新拟合那 90% 整体。
然后,使用重新拟合的模型在留存的 10% 测试集上进行预测。
对于所有数据集,整个过程重复 20 次;
但 Protein 和 Year 数据集除外,这两个数据集分别重复 5 次和 1 次。
![]()
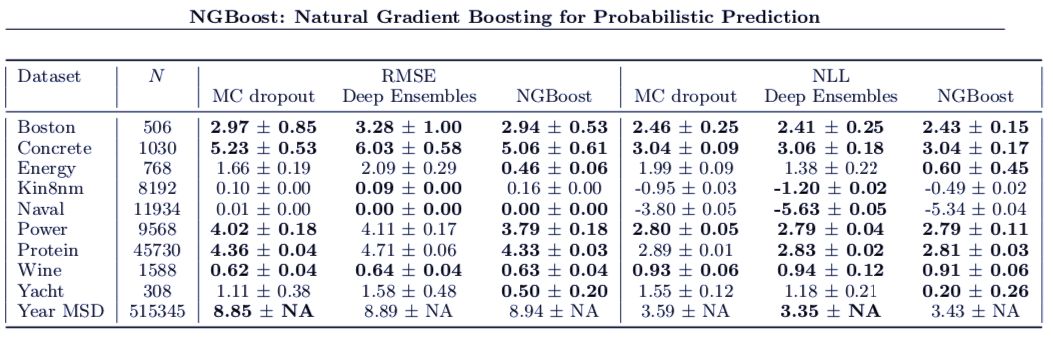
表 1:
在回归基准 UCI 数据集上的表现比较。
MC dropout 和 Deep Ensembles 的结果分别来自 Gal and Ghahramani (2016) 和 Lakshminarayanan et al. (2017)。
NGBoost 在 RMSE 和 NLL 上的表现都很有竞争力,尤其是在更小型的数据集上。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com