现代统计学的发展 第二部分
转自:
http://episte.math.ntu.edu.tw/articles/mm/mm_03_3_09/index.html
两岸数学词汇存有差异, 请参照[遇见数学]之前整理发布的《两岸数学词汇对照表》
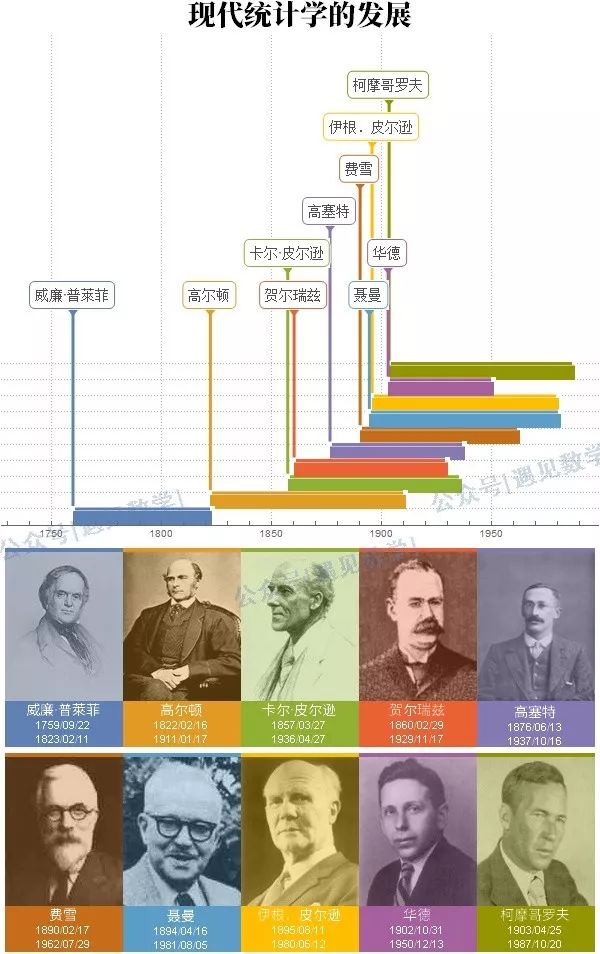
(续第一部分)在十九世纪末叶,有人问高尔顿爵士这种两组数据之间的关系是否可以测度?他想出了相关的观念。但是我们现在所用的相关系数ρ 却是卡尔皮尔逊所创,其定义为
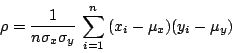
分别为X -组资料的算术平均和标准差。
经由简单的代数运算,我们可以证出ρ的数值介于-1与+1之间,0值表示没有直线关系存在,表示数据应在正斜率的直线上,-1表示数据在负斜率的直线上,在
附近的相关系数表示两变数有相当高的直线关系,接近0的相关系数表示两变数没有直线关系,在我们的例子中,ρ大约为0.9。注意ρ是直线关系的测度,数据可能形成一团,这时
值会很小,然而它们虽不是直线相关,但却无疑是相关的。
高尔顿是著名的演化论者达尔文的表亲,曾为达尔文做过一些统计工作。我们在上节曾提到他对相关概念的研究,但是教师们最不会忘记的高氏的贡献是他首创把成绩评分与常态曲线拉上关系。
常态曲线(正态曲线)至少可追溯至1733年的棣美弗(Abraham De Moivre)的导证,是一个统计上非常有用的观念。它的方程式为
其中 μ 和 σ 为参数,恰巧等于它的平均数和标准差。一般人把任意「钟形曲线」都想成为常态,事实上这种观念并不正确。其他函数例如 的图形也是钟形,但是却全然没有常态曲线所具有用的特性。常态曲线的方程式看起来似乎相当复杂,但是在数学家们看来却是所有曲线中最单纯「最安分」的曲线之一。图四就是一条特定常态曲线的图形。
图四:常态分布密度函数曲线图 |
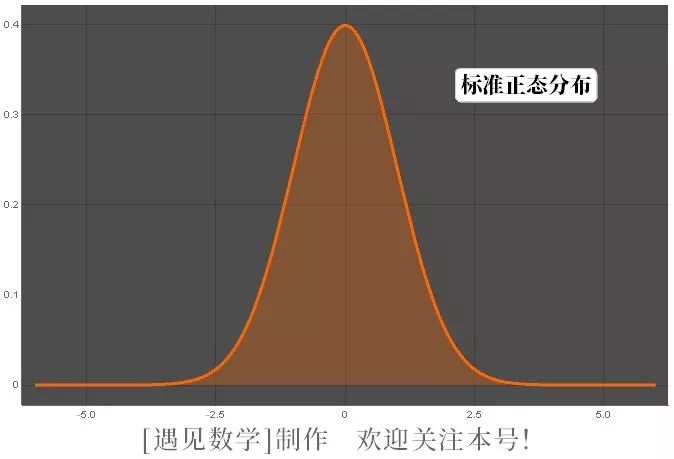
常态分配的优点是不论其平均数 μ 和标准差()之值为何,均可经过标准化
的变换,转换成平均数为0和标准差为1的标准常态分配。如果把在常态曲线下由
到
的面积积分的话,结果是1。大约有三分之二的面积在以平均数为中心左右一个标准差之间。在任意区间
之间常态变数的机率的求法就是等于求在这区间之上,常态曲线之下所围成的面积,这种数值可由任何标准的数表中查出。
早先在谈离散分配的时候,我们曾经提到算术平均数可以看成是总质重等于1的离散质点体系的质量重心。刚才我们提到的常态曲线是一个连续分配的例子,依据类比的方式,我们可以把常态分配与一根理想化向两端无限伸长质重为1而其密度则为依决定常态分配的函数f而变动分布的棒相联接。依据微积分,这种杆棒的质量中心是
这个公式正是我们用来定义连续分配的平均数的式子。或许很出人意外的,并不是每一连续分配都有平均数,因为上式的积分有时可能不存在。例如柯西分配,其方程式为
就是一个平均数不存在的分配,有兴趣的读者可试着验证它。
同理,依据离散变数的标准差公式,我们可以定义出连续分配的标准差为
如果用这两个公式来计算一下常态分配的平均数和标准差,经由相当简易的积分运算可以得出它们分别是它的两个参数 μ 和 σ。除此以外,高尔顿、皮尔逊和他们的「门徒」还创出回归观念和卡方试验。大约在1915年,一个新名字出现于统计界,费雪(Ronald Aylmer Fisher, 1890~1962),他在该年发表关于样本相关系数统计量的精确分配的论文引导进入统计史的第二时期。紧接着他的一系列的论文和专书给统计调查带来一股新动力。有人把我们如今所采用的统计理论的半数归功为费氏的成就,在费氏和他的同仁最卓越的成就中,包括适用于小样本的统计方法的发展,发现许多样本统计量的精确分配,假说检定之逻辑原则的简明陈述,变异数分析的发明和对一个群体参数的数理统计量中如何取舍的准则的介绍。据说费雪是个早熟的孩子[注4] ,在很小的时候就已精通如球面三角之类艰深的学问。他曾对物理科学深感兴趣,1912年自剑桥大学得到天文学的学士学位。天文学中的误差论(theory of errors)使他对统计问题发生兴趣,我们提到1915年他进入统计界因为那年他发表一篇关于样本相关系数的分配的文章。这篇文章启始了对各种样本统计精确分配的研究,费氏在这方面颇享盛名。在这方面的研究,他深受敏锐的几何直觉的引导,得出的很多结果,后来经几个闻名世界的最杰出数学家的研究,证明了其正确性。
费雪还有很多其他的贡献,早先我们曾提到他介绍了一样本统计量是否为一个群体参数的好估计量的判定准则,包括了一致性,效率性和充足性等概念就是在1921年一篇重要文献中提到的。在这类文章中,他还曾介绍最概估计量(maximum likelihood estimation) 的观念。
1919年费氏离开他在中学教数学的工作,转至罗森斯得农业试验站(Rothamsted Agricultural Experimental station),在这里他发展出现在世界通用的抽样技巧和随机程序。他的两本名著《Statistical Methods for Research Workers》和《Design of Experiments》分别于1925年和1935年出版,对于统计有重大的影响。后者的第二章曾列入《数学世界》 [注5],在这篇非常引人入胜的文章中,费氏提到有一位女士声称她能分辨出她的茶中牛奶是在泡茶之前或之后加入的,而后他描述一种实验计划来证明或否定该女士的声称。
为了想答覆关于群体的问题,由实用的观点来看,我们必须由群体中选取样本,然后依据样本所提供的资讯推论母体。母体所涉及的如母体均值μ和标准差σ都是未知,假设有一个样本被很适当地选出(如何选法是一个很重要的统计问题),依据样本可以得出相当好的母体参数或某量的估计值。早先我们曾提到费雪提出母体参数的好样本统计量的判别准则,我们只是很简要的提出,假若( x 1 , , x n )代表一组由母体均值为μ、标准差为σ的群体中选取的样本,则分别定义如下的样本平均数
和样本标准差S。
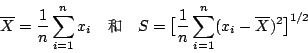
用这些统计量以估计μ及σ,会满足费雪所订的大部份准则[注6] 。
如果我们由一个群体取出很多组样本,并且每组均计算值,我们就可得到很多不同的数值,而这些数值会趋于接近群体平均数μ。这样看来,
也是一个变数呈某种形式分布,这就引起了一个重要问题:若已知群体变数为某种分配,则样本平均数又如何分配?下述定理,我们仅叙述而不证明,可回答部份这个问题。
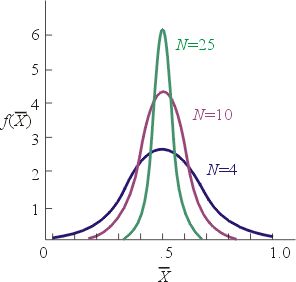
定理:若母体变数的分布函数为平均数μ和标准差σ的常态分配,则样本平均值亦为常态分配,其平均数为μ,标准差
,n为样本大小。
回想标准差的重要性,我们的结论是当样本大小越大,则值接近μ的机率也愈大,如图五所示。在应用这个定理时,受到一个严格的限制,因为实际上的任何群体是否确实为常态分配很可怀疑。有很多群体变数甚至不近似常态分配,但有一个在机率论上最著名的定理,也是在所有数学中最著名的定理之一可以部分帮助解决这个问题是中央极限定理,其中一种形式叙述如下:
定理:若一母体变数不论其分配如何,只要有平均数μ和一标准差σ,则
约近似为平均数为μ和标准差
的常态分配,而且当样本数n越大时,
的分布越近似常态分配。
中央极限定理有一段相当长的发展史,1773年棣美弗证明其第一种形式即考虑掷硬币只有两种可能出现的情形,我们在前面所说的形式是1922年凌德柏(JWLindeberg)所述[注7] 。近来俄国数学家甚至给出以常态分配为其极限分配的充要条件,把本定理推广至其极致。为了显示统计学家对中央极限定理的用法,我们来看由霍尔(Paul G. Hoel)编著的统计教本[注8]中的一个典型问题「某细绳制油商由过去的经验发觉某种细绳的平均耐拉力为15.6磅,标准差为2.2,现试将这种细绳的制造过程时间缩短,而后取50条细绳为样本做试验。结果发现其平均耐拉力减为14.5磅,试问依据这个样本,是否应下结论为「新制造程序对绳子拉力有坏的影响?」」
图五 |
统计人员称这种问题为假说检定,我们必须检定假说 对
,虽然制造程序改变,标准差也很可能改变,但是我们仍假设耐拉力X的标准差为2.2磅,现在我们用到了中央极限定理,不论X如何分配,
为平均数μ和标准差
的近似常态分配,或者说
为平均数0和标准差1的标准常态分配。然后我们查数值表,发现
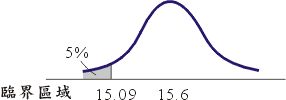
远离15.6,如果假说H 0成立的话,
的机率仅0.0002,因此我们弃却H 0而接受H 1。依照通常在H 0成立的假说下,
值出现的机率仅0.05时即弃却H 0的原则,由数表可知当
小于15.09,我们就应判定弃却H 0,任意小于15.09的数值称为在临界区域。
图六 |
我们再回头提一下假设新制程的标准差σ不变的误差机率。事实上,这时σ已不是一个已知数,但是我们可以计算出样本标准差S,在1908年化学家高塞特(William Gosset)以Student的笔名发表他发现的统计量 (注意σ被S取代)的分配,他指出若X为常态分配,则t为自由度n -1的student t分配,这种分配相当重要,其分配数值在一般统计数表中均有列出。虽然高塞特于1908年发现t分配,但是他的结果只是一种猜测,直到1926年才由费雪加以严密的证明。在此X为常态分配这条件非常紧要,但是即使X仅为近似常态分配,统计学家发现当σ为未知,尤其是当样本数n值很小时,非常适宜采用t分配。当n相当大时,S和σ的差别越来越小,因此不太需要使用t分配数值表。
第三个时期以为在1928年聂曼(Jerzy Neyman)和伊根.皮尔逊(Egon Pearson,卡尔.皮尔逊之子)的共同论文多篇的发表为开端,这些论文介绍和强调诸如验定问题中的第二种错误,检验的检定力和信赖区间之类的观念。在这期间,工业界开始大量采用统计技巧,尤其是与品质管制有关的统计。并且由于人们对调查工作的感兴趣导向对抽样理论与技巧的研究,1928年聂曼和伊根.皮尔逊的论文为检定与估计理论带来一种崭新的面貌。包括对许多费雪早先提出的想法的重新加以整理和修正,例如在细绳制造商的问题中,我们早先得到的结论是:若一样本的样本平均数值小于15.09则弃却假说H 0。聂曼和皮尔逊提出如下之类的问题:为什么我们要设15.09以左为临界域?为什么不取0.025在分配曲线极左的面积和0.25在分配曲线极右的面积成「双尾」(two tailed)临界区域?
图七 |
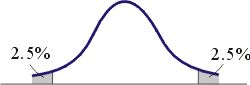
于选取临界域时必须采何种准则?我们必须要用直觉还是用严谨的数学?我们得到如图八的结论牵涉到两种不同型态的错误,聂曼和皮尔逊命名为第一种错误和第二种错误。聂曼和皮尔逊总结他们的发现归纳成为下述原则:在所有具有相同第一种错误的试验(临界域)中,我们选用具最小第二种错误的临界域。
H 0为真 |
H 1为真 |
|
|
正确决定 |
第二种错误 |
|
第一种错误 |
正确决定 |
图八
虽然本原则的应用相当复杂,聂曼和皮尔逊的影响使本原则及其相关的检定力函数成为重要的统计概念,并且发展出讨论这类问题的一般数学理论。
谈现代统计学的发展,实不能不提华德(Abraham Wald, 1902~1950)[注9] ,否则必定显得不完备。华德的第一篇论文关于目前常见的统计程序── 逐次抽样(sequential sampling)的出现第四时期的开始。这篇1939年的论文是华德一连串论文的起始,不幸正当他的创新力处于颠峰时却由于飞机失事死于非命。华德最大的贡献之一是他介绍一种对统计问题的新看法(1945),那就是以对局的观点去处理统计方面的问题,这就是今日所称的统计决策理论(statistical dicision theory)。从这个观点,统计被视为以自然为对手的对局的艺术,这是一个相当广义的理论,虽然它牵涉到相当复杂的数学,但是平心而论,我们可以说大部分目前的统计研究人员发现采用这种新观点非常理想。华德对统计理论发展的方向有重大的影响,他的「门徒」们多成为今日统计界的领袖人物。
华德诞生在罗马尼亚,是正统的(orthodox) 犹太世家,由于它的宗教信仰,使他受教育的机会受到某些限制,而必须靠自修弥补。他自修的结果竟能对希尔伯特(Hilbert) 的《Foundation of Geometry》提出有价值的见解,他的建议列入该书的第七版中,这一事实充分显示了他的数学天赋。后来华德进入维也纳大学并且在仅修了三门课之后就得到博士学位。在这个时期的奥地利,由于政治上的因素使他无法从事学术工作,只好接受一个私人职位,职责是帮助一位银行家增广高等数学知识,他因此对经济学深感兴趣,后来成为经济学家摩根斯坦(Oskar Morgenstern) 的亲信助理。摩氏曾与冯纽曼(John Von Neumann) 共同合作从事研究并奠定了对局论(game theory) 的基础。
华德在二次大战前到达美国,他的父母和姊妹不幸没有逃出来,结果死于纳粹的瓦斯房。华德由于对经济学的兴趣接触到统计学,逐渐转向从事统计学的研究,不久竟成为一位杰出的理论统计学家。除了统计决策理论之外,华德对统计还有很多重要的贡献,在此我们提出主要的一个,就是逐次分析。虽然这个理论可能不是他所首创,但却是他发展完成的(1943)。这个技巧在减少生产制程中的抽样数方面非常重要,二次大战期间曾被列为机密。
现在我们以工业方面的品质管制问题为例来说明逐次分析的观念,在逐次方法未发表之前,标准的抽样程序是由制成品中抽取定量的样本,然后依据样本中所含不良品数的多寡判定允收或拒收该批。这种程序忽略了关于制成品批的优劣资讯可由在抽样过程中不良品出现率的大小获得的事实。
在逐次抽样中,我们把抽样过程中可能发生的状况分为三类:
(1)大量不良品连续出现导致立即判定拒收该批
(2)大量良品连续出现,导致立即判定允收该批
(3)缺乏结论性的证据,因此必须继续抽样,图九是一个实例。
图九:这次抽样 |
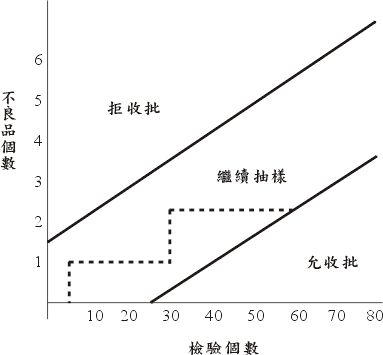
这三个区域的划分准则视所允许的第一种错误和第二种错误而定。在本例中,在查验第六十个制成品后才判定允收。
由图形中可见,这种抽样方法可能很快就能决定是否允收,也可能在中间区域停留很久的时间,但是华德证明允收或拒收的决定能于有限步内达成的机率为1 ,实际经验显示逐次抽样和传统的固定样本大小的程序相比在抽样费用方面约可节省一半。
除了上述四大统计思潮外,1933年俄国数学家柯摩哥罗夫(Kolmogorov) 发表《Foundation of the theory of probability》为统计学理论奠定了逻辑基础。在统计应用技巧方面,电子计算机的发展和使用是一大革命。十九世纪末叶开始,美国人口调查局(US Census Bureau) 每十年举办一次人口普查,后来,由于人口的渐增,人口调查局发现他们已越来越无法处理所搜集的成堆数据。贺尔瑞兹(Herman Hollerith) 想出许多利用打孔卡片(punched card) 记录数据的方法,并且发明机械能读这些数据和处置资讯(Information),在贺氏的指导下,1894年人口调查局的工作利用打孔卡和读卡机,提高不少效率。虽然1890年人口调查时,美国人口比1880年增多了约百分之二十五,但是工作完成所费的时间却仅为其三分之一。
电子计算机于二次大战后发展一日千里,1950年后渐进入实用阶段。计算机的出现不但使统计计算工作简化,而且快捷。尤其是有了统计成套程式(Statistical package) 以后,更为方便,只要知道应采用何种统计方法就能使用。1972年惠普(Heweleit Packard) 公司发展出掌上型计算器(calculator),对于一般小统计问题的解决,更是方便,不必因为统计问题特地到计算机中心去。
统计为一科学方法,其可应用范围,遍及自然科学及社会科学的整个领域中的许多部分,大凡农业、工业、商业、教育、医药、政治、社会、经济等等许多问题无不适合采用统计方法处理,统计学传入我国虽已有相当时日,但是我国目前还只有政府机关较为重视,民间工商企业近年来虽然也渐渐讲求科学管理,但是大多未能应用统计方法。(完)



