前言:当前对序列推荐的研究集中于开发更高效的序列表示学习(SRL)模型。大部分已有方法都是显示地对商品 ID 进行序列建模,然而这些模型难以迁移至新的推荐场景,如新的领域或平台。为了解决建模商品 ID 带来的限制,本文提出了一个新的 SRL 方法 UniSRec。具体的,UniSRec 利用商品的文本信息学习可迁移至不同推荐场景的通用表示。为了学习通用商品表示,我们设计了基于参数白化和混合专家网络(MoE)增强的商品编码架构;为了学习通用序列表示,我们设计了两种基于对比学习的优化目标,在预训练阶段采样多个领域的序列/商品作为负例。预训练后的通用序列表示模型可以参数高效地迁移至新的领域或平台中。在真实数据集上构建的大量实验验证了 UniSRec 的效果。特别的,当把 Amazon 数据集上预训练的 UniSRec 模型迁移至一个新平台(某英国电商)时,也可以观察到效果提升,验证了本文提出的通用序列表示学习方法的强大迁移性。
作者: 侯宇蓬,中国人民大学硕士生二年级,导师为赵鑫教授,研究方向为推荐系统和图机器学习。
论文题目:Towards Universal Sequence Representation Learning for Recommender Systems
论文下载地址:
https://arxiv.org/pdf/2206.05941
论文开源代码:
https://github.com/RUCAIBox/UniSRec
一、背景与动机
序列化推荐模型通常可以归纳为一类序列表示学习(SRL)任务,即先将用户行为形式化为按时序排列的商品序列,然后开发高效的网络架构来捕捉序列交互特征并反映用户偏好,如 RNN、CNN、GNN、Transformer、MLP 等。
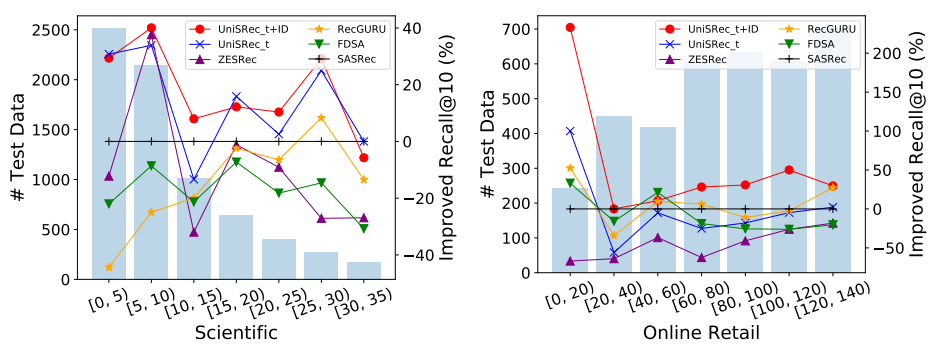
然而大多数针对推荐系统的 SRL 方法都依赖于显示的商品 ID 建模,存在迁移性差和冷启动的问题。即使各个推荐场景的数据格式是完全相同的,这些序列推荐模型依然难以迁移至新的领域或平台,严重限制了推荐模型的重用性。面对一个新的推荐场景,我们往往需要重新训练一个模型,这十分繁琐又耗费资源。此外,对于那些在数据中仅仅存在几次交互历史的冷启动商品,由于训练数据较少,现有的基于商品 ID 建模的模型也难以被很好地推荐给合适的用户。
二、思路与挑战
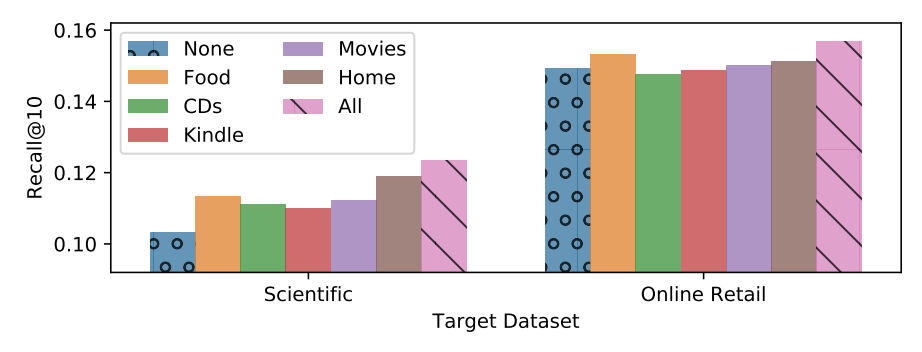
受到预训练语言模型的启发,我们致力于设计一个新的 SRL 方法,打破显示建模 ID 带来的限制,学习更具通用的序列表示。核心想法是利用与商品相关的文本(如商品描述、标题、品牌等)来学习可在不同域之间迁移的商品表示和序列表示。
但我们仍然面对一些主要挑战:
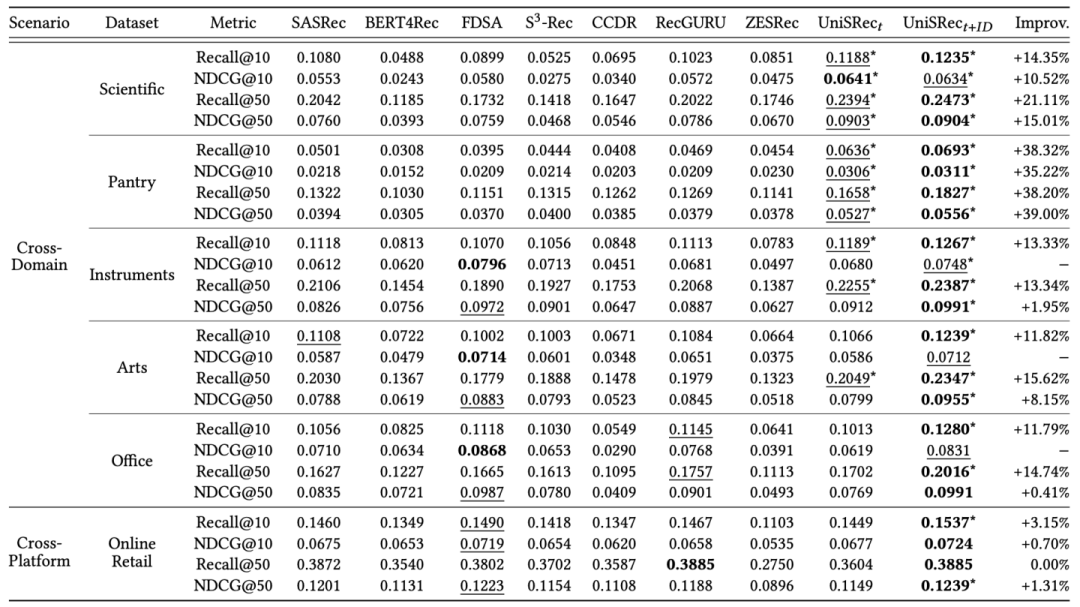
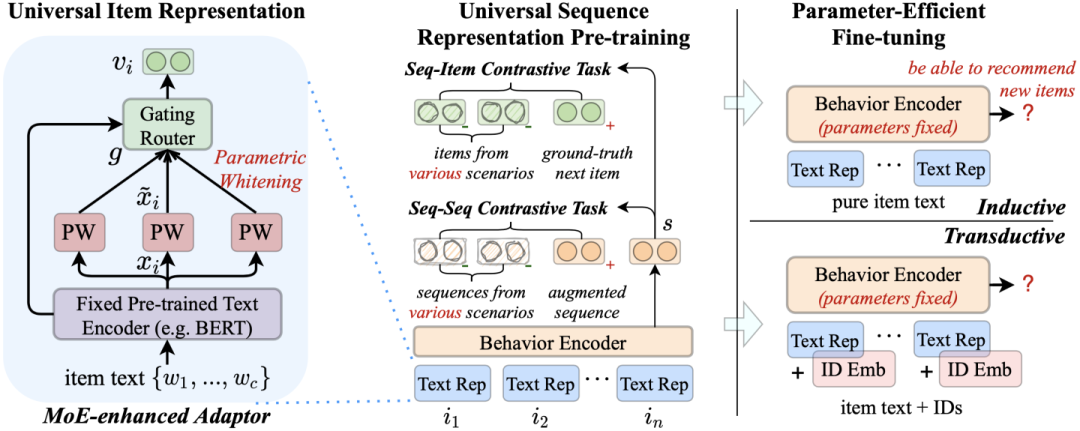
本节我们来介绍本论文提出的 UniSRec 模型。给定多个领域的历史交互序列,UniSRec 致力于学习通用的商品和序列表示。这些通用表示可以参数高效地迁移并泛化至新的推荐场景(新领域 or 新平台)。
1. 输入
用户行为序列可以被形式化为
(按时间顺序排列),其中每个商品都对应着一个独特的商品 ID 和一段描述性的文本(如商品描述、标题或品牌)。商品的描述文本可以形式化为,其中来自于共享的词表,表示商品文本截断的长度。
注意这里的每个序列包含了一个用户在某个特定领域的交互行为,而一个用户可以在多个不同领域和平台产生多个行为序列。由于不同领域间存在较大的语义差距,我们没有将一个用户的行为简单地混合为一个序列,而是将它们视为不同的序列,且并不显示地标注一个序列的用户是谁。注意到商品 ID 在本方法中只作为辅助信息,我们主要使用商品文本生成 ID 无关的可泛化的表示。除非特别指定,否则商品 ID 都不会作为 UniSRec 的输入。
2. 通用商品文本表示
通用序列行为建模的第一步即是将不同推荐场景的商品表示为通用语义空间中的向量。之前的方法通常是给商品 ID 分配一个可学习的嵌入表示。由于不同领域的商品 ID 的集合通常不同,这种方法限制了商品表示的可迁移性。
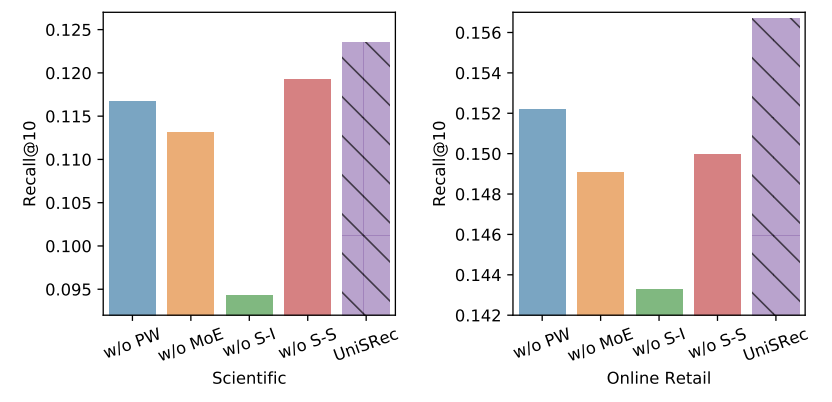
我们的做法是基于商品文本学习可迁移的商品表示,是通过自然语言描述了商品的特性。越来越多的证据显示,自然语言提供了一个通用的数据格式,可以连接不同的任务和领域。受此启发,我们首先使用预训练语言模型(PLM)学习文本表征。进一步,由于不同领域的文本表征可能会形成不同的语义空间(即使文本编码器相同),我们提出使用参数白化网络和混合专家网络(MoE)增强的适配器模块来将原始的文本表示转换至适用于推荐任务的通用的语义空间。

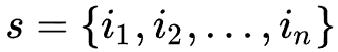 (按时间顺序排列),其中每个商品
(按时间顺序排列),其中每个商品
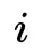 都对应着一个独特的商品 ID 和一段描述性的文本(如商品描述、标题或品牌)。商品
都对应着一个独特的商品 ID 和一段描述性的文本(如商品描述、标题或品牌)。商品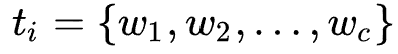 ,其中
,其中
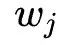 来自于共享的词表,
来自于共享的词表,
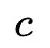 表示商品文本截断的长度。
表示商品文本截断的长度。
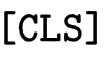
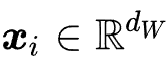
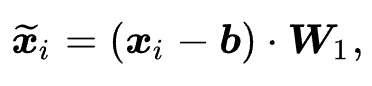
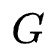 个参数白化网络作为 experts,并基于参数化的路有模块构建了 MoE 增强的适配器(Adaptor)
个参数白化网络作为 experts,并基于参数化的路有模块构建了 MoE 增强的适配器(Adaptor)
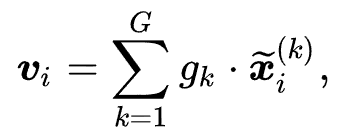
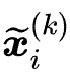 是第
是第
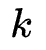 个参数白化网络的输出,
个参数白化网络的输出,
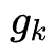 是门控路由模块生成的对应的融合权重,具体计算方式如下
是门控路由模块生成的对应的融合权重,具体计算方式如下
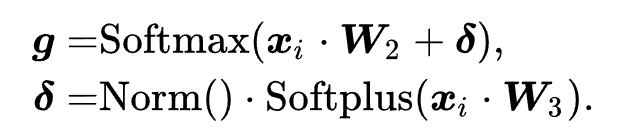
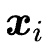 作为路由模块的输入,因为其携带着领域相关的语义偏置。这里的
作为路由模块的输入,因为其携带着领域相关的语义偏置。这里的
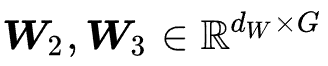 是可学习参数。为了 experts 间的负载均衡,我们使用
是可学习参数。为了 experts 间的负载均衡,我们使用
 来生成随机高斯噪声。
来生成随机高斯噪声。
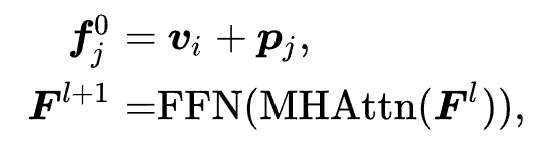
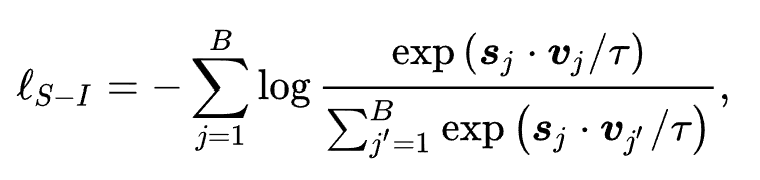
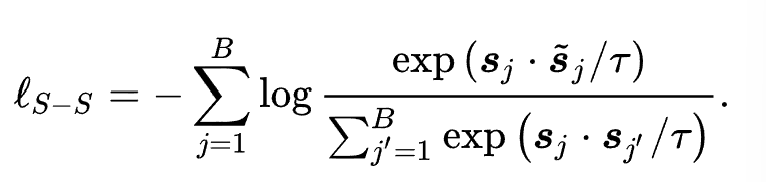
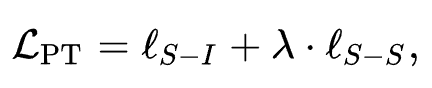

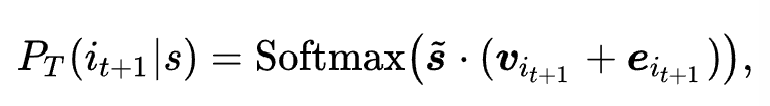
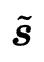 代表 ID 表示增强后的通用序列表示。
代表 ID 表示增强后的通用序列表示。