【深度语义匹配模型】实践篇:语义匹配在贝壳找房智能客服中的应用

深度语义匹配模型系列文章的终结篇,带大家走进贝壳找房智能客服的匹配。
一、背景
贝壳找房作为房产领域领先的服务平台,业务场景中包含大量自然语言处理的任务。经纪人与用户的交互过程会产生大量的文本语料,无所不能的小贝助手能够帮助经纪人更好的理解用户的需求。
经纪人在面对客户时会遇到很多业务上的问题,比如二套房的贷款比例,税费如何计算等,而经纪人自己也有需要解答的问题,比如公司某项规章制度的解读,等级积分制度,公积金如何提取等。经过长期的积累,运营人员根据线上用户的提问做总结,沉淀下来的知识形成了房产领域的FAQ库(知识库)。我们的智能客服场景致力于解决经纪人的问题,提供一个便捷的搜索入口,以便后续有人再有相同或相似问题时可以直接搜到答案。
智能客服相比于人工客服具有响应速度快、always online、维护成本低等优势,在有FAQ库的前提下,通过智能化手段辅助人工解决经纪人的问题已逐渐被越来越多的经纪人所接受并优先选择。
二、匹配算法的应用场景
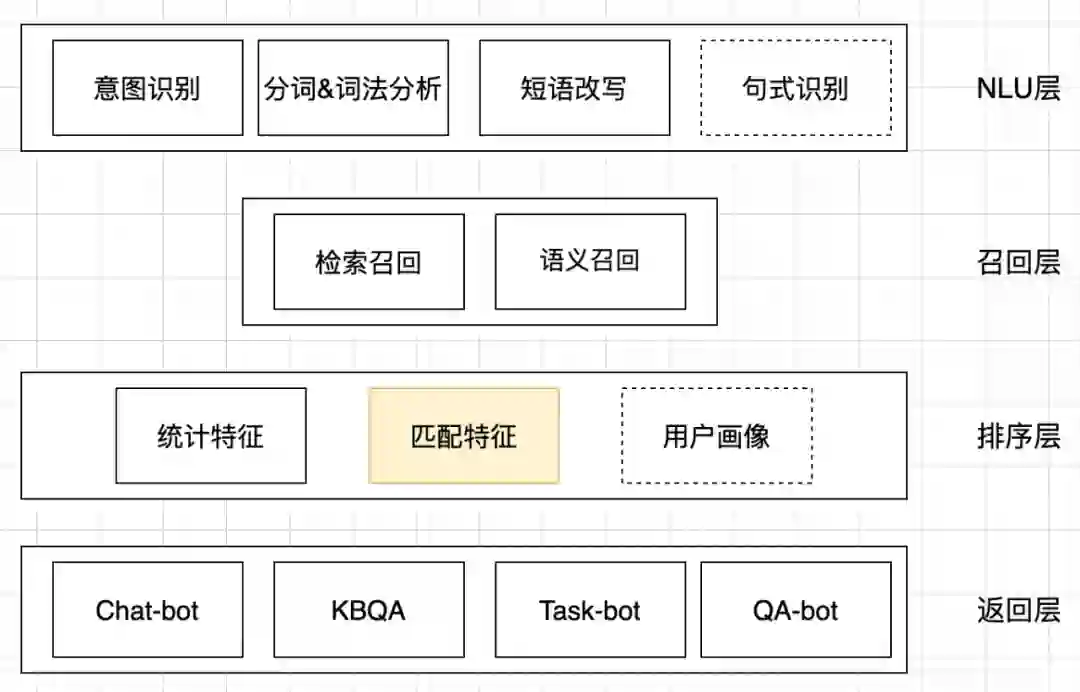
整个智能客服的架构如下图所示:
-
NLU层:NLU层是对用户输入的query进行解析,包含意图识别、分词与词法分析、短语改写等功能。意图识别是为了识别出query的意图,我们通过日志分析总结出了116个意图,其中包含7个Task意图,1个寒暄意图,和108个具体业务意图,会根据不同的意图识别结果走不同的bot。这里的意图识别模型用的是fastText,该模型有高效的训练速度和较高的识别准确率,做出来的结果也可以达到上线使用的标准。词法分析维护了一些词典,通过词典匹配能获得query中的关键词和关键短语。短语改写的目的是为了纠错,比如“搏学考试”手误输入成了“博学考试”,短语改写便能将其纠正,query改写后能更容易召回正确答案。
-
召回层:召回层是将候选答案从FAQ库中拿回,获得待排序的候选集。此处用了两种召回方式:检索召回和语义召回。检索召回会根据NLU层的意图识别与词法分析结果进行关键词和意图的加权,同时,n-gram的使用也一定程度上减弱了分词错误带来的负面影响。语义召回是将相似问构建成一个faiss索引,这些相似问已经由知识库运营人员总结成标准问,并和知识产生了挂接。query和相似问会被映射到同一个语义向量空间,通过KNN能快速拿到和query最相近的相似问,从而拿到最可能回答query的答案。下图直观展示了语义召回的过程:

-
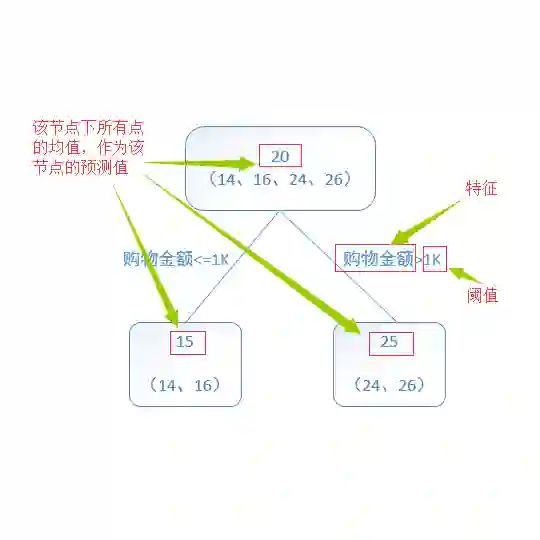
排序层:排序层是将召回层拿到的候选知识进行排序,将和query最相关的知识尽可能往前排。排序模型采用了GBDT,GBDT作为一种常用的树模型,可天然地对原始特征进行特征划分、特征组合和特征选择,并得到高阶特征属性和非线性映射。我们考虑用GBDT可以组合多种特征,可扩展性强,并且后期验证GBDT的效果好于单独使用匹配算法效果,因此,当前匹配算法在排序层中作为一种特征来使用。
-
返回层:query经过上述处理之后会对处理结果进行返回。四种返回层场景展示,依次是Chat-bot,Task-Bot,KBQA和QA-Bot:
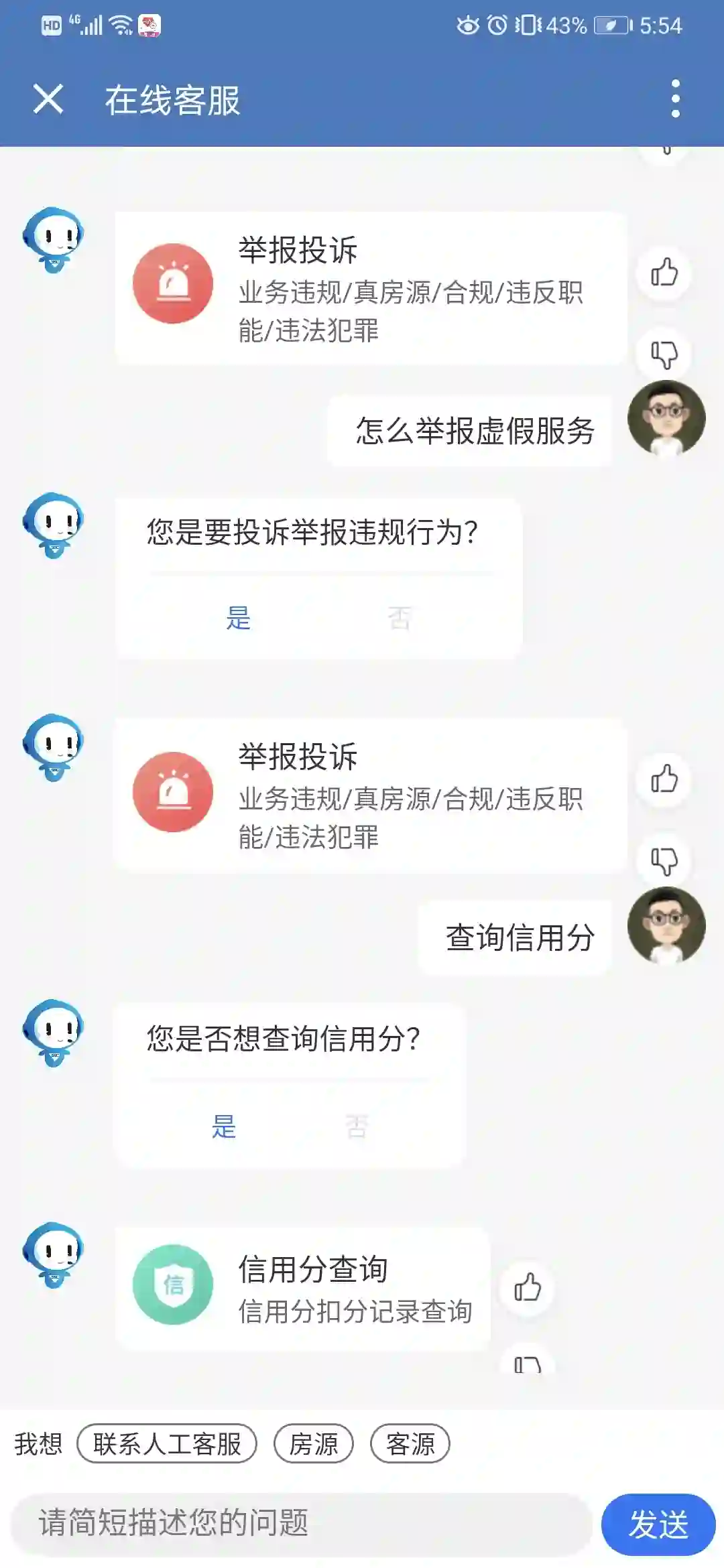
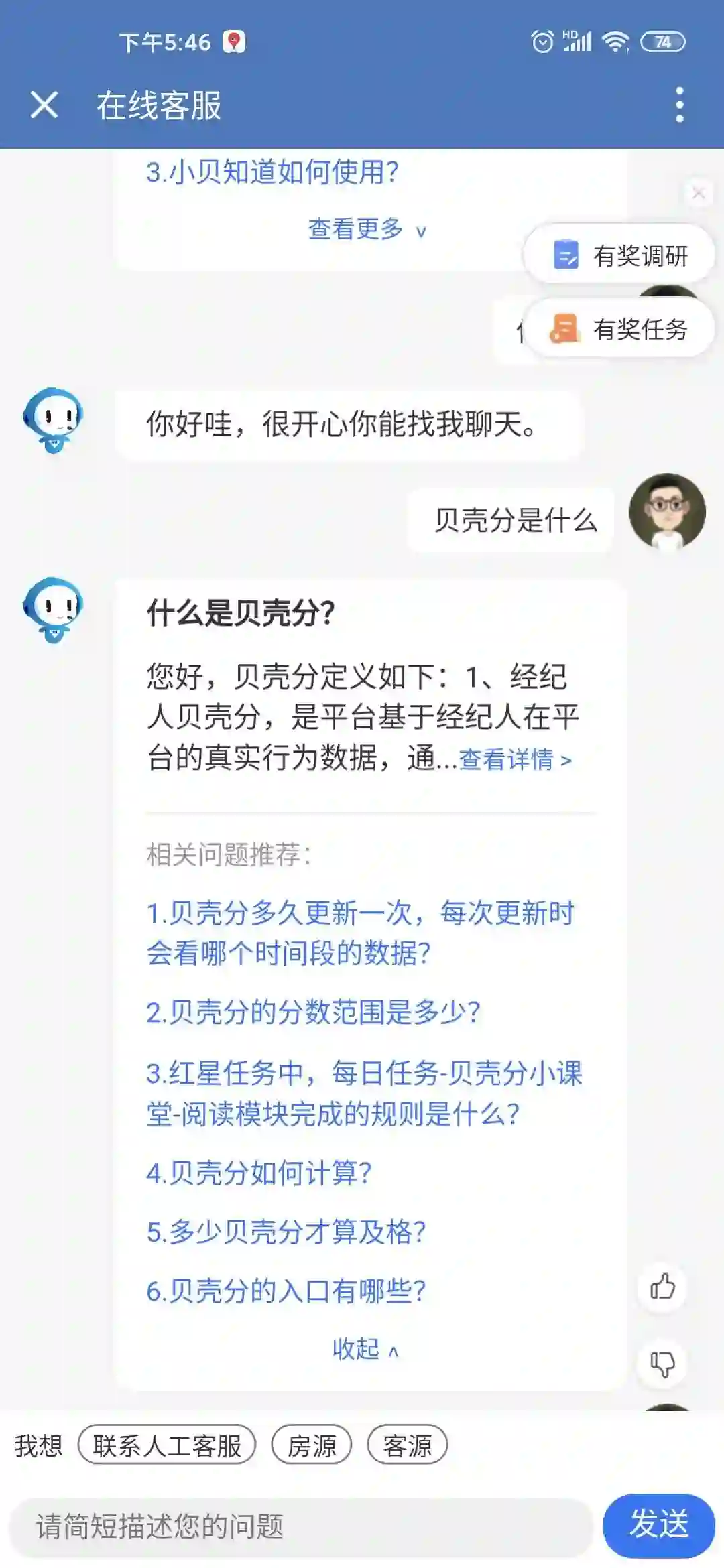
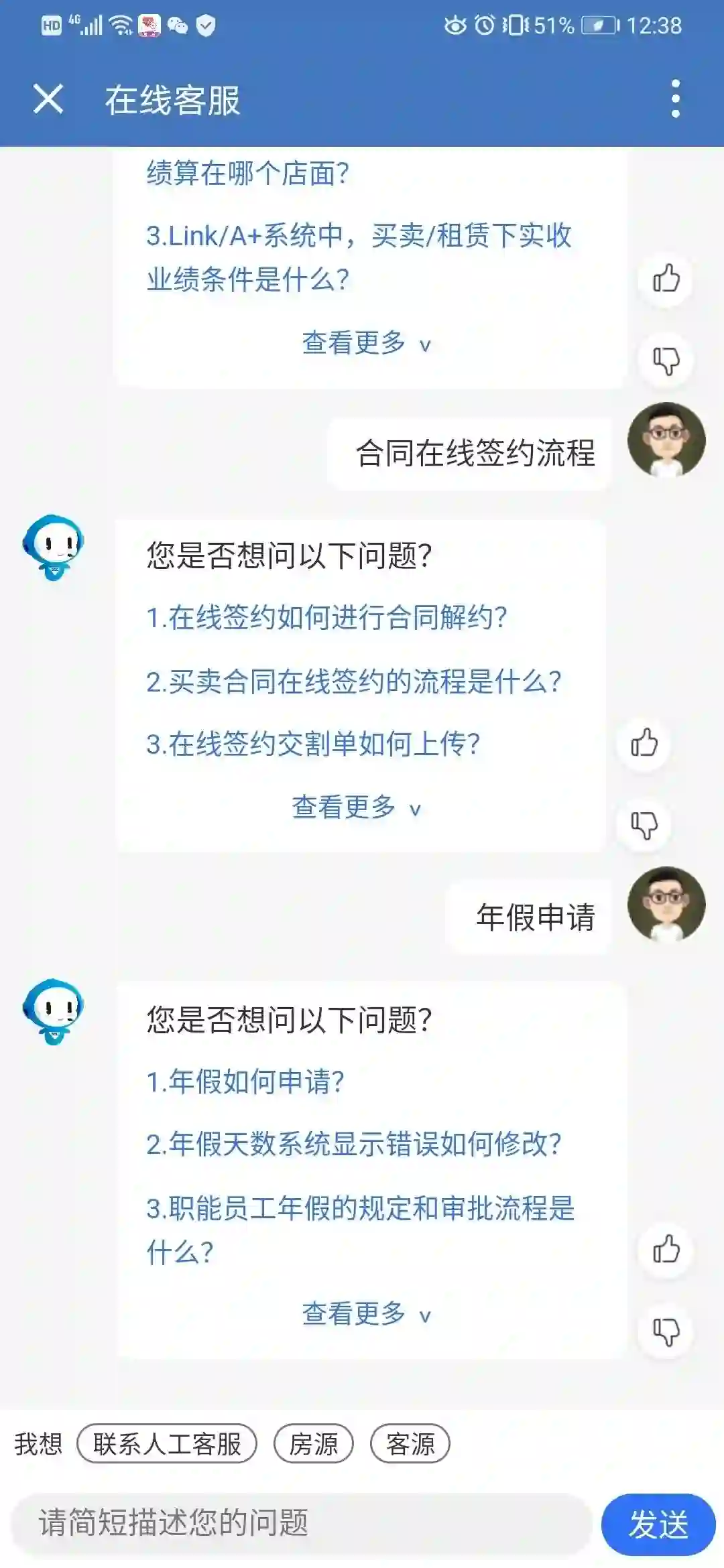
<<< 左右滑动见更多 >>>
三、匹配算法的实践
3.1 数据准备
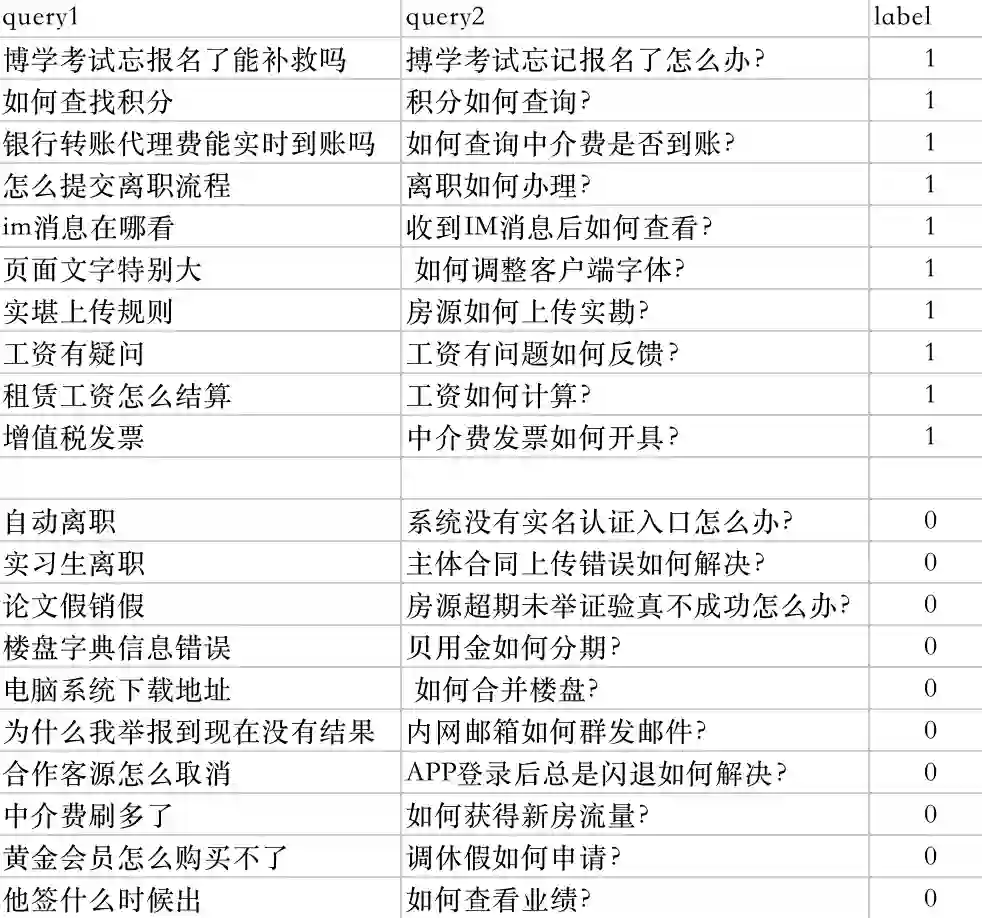
随着标准问数量的增加,知识库中存在大量query和标准问的匹配对,将这些匹配对当作正样本,label为1。将query随机抽取一条与之不匹配的标准问作为负样本,label为0。共产生12w+的训练样本和5000条测试样本,正负样本比例为1:1。标准问是由人工标注总结,因此数据集质量较高,正样本匹配关系很强,数据比较规整。训练样本展示:
3.2 模型训练
我们对4种交互型的深度语义匹配模型进行尝试,分别是ABCNN(ABCNN-1,ABCNN-2,ABCNN-3),PairCNN,ESIM和Bimpm。使用交互型匹配模型的原因如下:
-
交互型的深匹配模型能很好地把握语义焦点,对上下文重要性进行合理建模。 -
从训练集数据来看,正样本是人工标注的有监督数据,交互型模型能保证较高的准确率。
模型原理传送门 (【深度语义匹配模型】原理篇二:交互篇)。四种模型都有优秀的表现效果,因线上使用的模型是ABCNN-2,这里为大家展示该模型的部分实现代码。
#attention矩阵def make_attention_mat(x1, x2):# 作者论文中提出计算attention的方法 在实际过程中反向传播计算梯度时 容易出现NaN的情况 这里面加以修改# euclidean = tf.sqrt(tf.reduce_sum(tf.square(x1 - tf.matrix_transpose(x2)), axis=1))# return 1 / (1 + euclidean)x1 = tf.transpose(tf.squeeze(x1, [-1]), [0, 2, 1])# 矩阵乘法einsum('ij,jk->ik', m0, m1) # output[i,k] = sum_j m0[i,j] * m1[j, k]attention = tf.einsum("ijk,ikl->ijl", x1, tf.squeeze(x2, [-1]))return attention#全部cnn层相关操作def CNN_layer(variable_scope, x1, x2, d):with tf.variable_scope(variable_scope):#卷积left_conv = convolution(name_scope="left", x=pad_for_wide_conv(x1), d=d, reuse=False)right_conv = convolution(name_scope="right", x=pad_for_wide_conv(x2), d=d, reuse=True)#获得注意力矩阵left_attention, right_attention = None, Noneatt_mat = make_attention_mat(left_conv, right_conv)left_attention, right_attention = tf.reduce_sum(att_mat, axis=2), tf.reduce_sum(att_mat, axis=1)#pooling(average pooling(w-ap)和qverage pooling(all-ap))left_wp = w_pool(variable_scope="left", x=left_conv, attention=left_attention)left_ap = all_pool(variable_scope="left", x=left_conv)right_wp = w_pool(variable_scope="right", x=right_conv, attention=right_attention)right_ap = all_pool(variable_scope="right", x=right_conv)return left_ap, right_ap#x1,x2是需要匹配的文本embedding后的结果x1_expanded = tf.expand_dims(x1, -1)x2_expanded = tf.expand_dims(x2, -1)#average pooling(all-ap)最终获得为列向量LO_0 = all_pool(variable_scope="input-left", x=x1_expanded)RO_0 = all_pool(variable_scope="input-right", x=x2_expanded)#x1,x2全部cnn层相关操作后所得特征LO_1, RO_1 = CNN_layer(variable_scope="CNN-1", x1=x1_expanded, x2=x2_expanded, d=d0)#计算相似度#作者论文中提出计算相似度的方法是将L01_1,R0_1拼接后进行逻辑回归,这里为了简化计算直接将all_pooling层和L01_1,R0_1分别计算相似度后拼接,然后进行逻辑回归self.sims = [cos_sim(LO_0, RO_0), cos_sim(LO_1, RO_1)]
3.3 效果测评
5000条测评数据的情况下,上述模型都取得了较好的匹配效果。
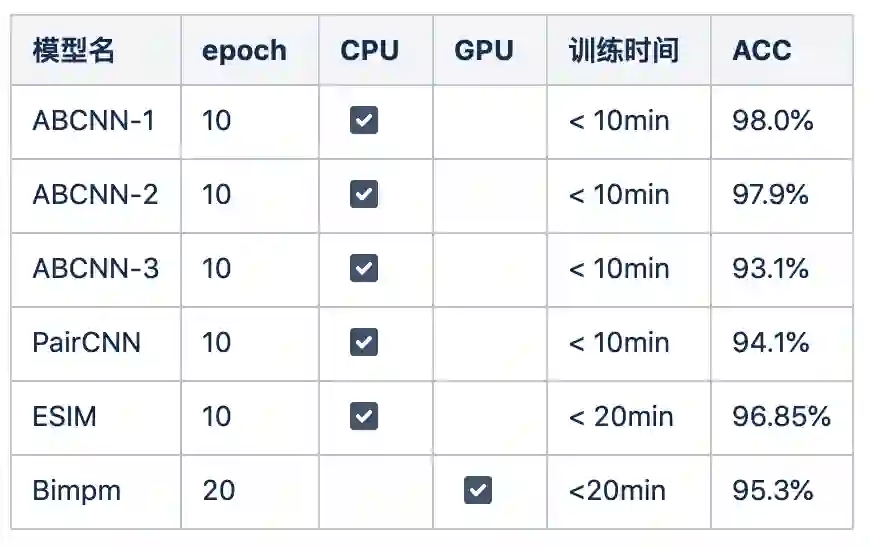
从耗时来看Bimpm训练耗时较长,相比于其他模型收敛速度较慢,整体的耗时排序为t(ABCNN) < t(PairCNN) < t(ESIM) < t(Bimpm),ABCNN的三种算法训练时间没有明显差别。需要特别说明的是,由于Bimpm模型复杂,在cpu上训练时间过长,最终的训练是在GPU上完成。
从准确率来看ABCNN-3和PairCNN的准确率低于95%,剩余都高于95%。ABCNN的三种算法中,ABCNN-1和ABCNN-2的效果相差较小,ABCNN-3的网络结构综合了ABCNN-1和ABCNN-2的结构,但是实验效果并没有更好,反而更差,从侧面反映网络结构更复杂,准确率不一定就更好。
3.4 经验与踩坑
Q:数据对模型有什么影响?
A: 数据质量决定了模型效果的好坏,也尝试采用点击title与query计算相似度,大于某个阈值作为正样本,未点击title与query计算相似度,小于某个阈值作为负样本,因存在错误数据,模型训练效果大打折扣。
Q: 除了数据外,ABCNN模型训练效果受什么影响?
A: ABCNN模型最初几轮的训练效果与模型的随机初始值有很大关系,初始值较差和较好的时候训练达到相同效果的情况下,训练epoch number相差10多轮不足为奇。
Q:为何Bimpm训练时间长?
A: Bimpm模型结构相对复杂,从训练时间上和内存使用率上来说,bimpm应该是放在有GPU情况下考虑选择的模型,并且用原文的参数进行训练时会遇到显存用尽的报错,上表中的结果是删掉两层全连接层,并且减少了神经元个数后训练得出的。
Q:复杂模型的构建与训练有什么建议?
A: 检查写的神经网络是否本身有问题,训练时先用小样本,再逐步增大样本量,通过是否过拟合来判断网络是否正确。
四、总结与展望
当前的深度语义匹配模型已经在贝壳智能客服的在线咨询主场景中使用,模型上线后,QA-bot的列表点击率有了2%的绝对提升,对于一些简单的问题已经能够将较匹配的答案排到top3。
但是对于需要深度语义及具有知识背景的问题,如:“A3到A4需要多少分”的问题,还没有办法将答案“经纪人积分与级别是如何对应的?”排在靠前的位置。当前正在进行知识图谱方向的开发,对知识库内的知识进行结构化的梳理,希望在匹配的同时能够具有简单的推理,来更好的理解用户语言背后的需求。
展望:
-
数据是效果的基础,智能客服效果所依赖的FAQ库也需要不断的知识扩充,如何通过自动或半自动的方法挖出更多高质量的相似问或者标准问,为知识运营人员提效,也是我们现阶段正在探索的方向。 -
当前的匹配算法仅作为一种特征使用在gbdt排序模型中,后期随着匹配算法的不断积累,会将所有的匹配模型进行整合,以一种更通用的模块化的方式,为有文本匹配需求的各个业务场景提供匹配算法的支持。
作者介绍
黄钰瑶,2019年毕业于华中科技大学,毕业后加入贝壳找房语言智能与搜索部,主要从事NLP及智能客服相关工作。
卢新洁,2018年毕业于澳大利亚新南威尔士大学,毕业后加入贝壳找房语言智能与搜索部,主要从事NLP及智能客服相关工作。
相关文章

推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。