【ICLR2021】神经元注意力蒸馏消除DNN中的后门触发器

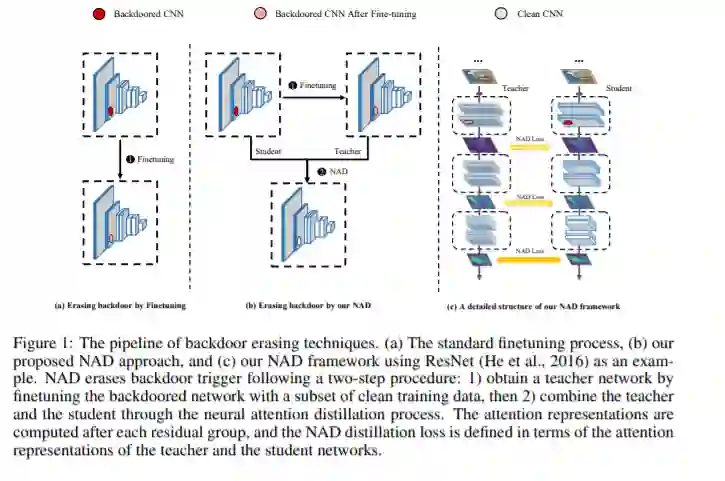
本篇论文的研究对象是AI安全领域的后门攻击。作为一种发生在训练阶段的定向攻击,后门攻击近年来在AI安全中引起了极大的重视。后门攻击能够控制模型的预测结果,但是却不会影响正常样本的预测准确率,是一种相当隐蔽且危险的攻击。更重要的是,一旦将后门触发器嵌入到目标模型中,就很难通过传统的微调或神经修剪来彻底消除其恶意的影响。针对这一问题,本文提出了一种新颖的防御框架--神经元注意力蒸馏(Neural Attention Distillation,NAD),以消除DNN中的后门触发器。NAD利用教师网络在少量干净的数据子集上指导后门学生网络的微调,以使学生网络的中间层注意力激活与教师网络的注意力激活保持一致。其中,教师网络可以通过对同一干净子集进行独立的微调获得。针对6种最新的后门攻击——BadNets,Trojan attack,Blend attack,Clean-label attack,Sinusoidal signal attack,Reflection attack,验证了提出的NAD的有效性,仅使用5%的干净训练数据就可以有效擦除后门触发器,同时几乎不影响干净样本的性能。本文提出的基于神经元注意力蒸馏的后门净化方法是目前业界最简单有效的方法,能够抵御目前已知的所有后门攻击,理论分析表明该方法具有对后门攻击的普适性防御能力。论文代码已经开源:https://github.com/bboylyg/NAD。
https://www.zhuanzhi.ai/paper/cd0a5e5691fdcf5c9d35336bee226409
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NAD” 可以获取《【ICLR2021】神经元注意力蒸馏消除DNN中的后门触发器》专知下载链接索引




