理解dropout: 组合 or 噪声?

开篇明义,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
dropout是CNN中防止过拟合提高效果的一个大杀器,但对于其为何有效,却众说纷纭。在下读到两篇代表性的论文,代表两种不同的观点,特此分享给大家。
注: 这是之前在csdn博客写的文章,搬运过来的。所以图稍微有点模糊。
组合派
参考文献中第一篇中的观点,Hinton老大爷提出来的,关于Hinton在深度学习界的地位我就不再赘述了,光是这地位,估计这一派的观点就是“武当少林”了。注意,派名是我自己起的,各位勿笑。
观点
该论文从神经网络的难题出发,一步一步引出dropout为何有效的解释。大规模的神经网络有两个缺点:
-
费时 -
容易过拟合
这两个缺点真是抱在深度学习大腿上的两个大包袱,一左一右,相得益彰,额不,臭气相投。过拟合是很多机器学习的通病,过拟合了,得到的模型基本就废了。而为了解决过拟合问题,一般会采用ensemble方法,即训练多个模型做组合,此时,费时就成为一个大问题,不仅训练起来费时,测试起来多个模型也很费时。总之,几乎形成了一个死锁。
Dropout的出现很好的可以解决这个问题,每次做完dropout,相当于从原始的网络中找到一个更瘦的网络,如下图所示:
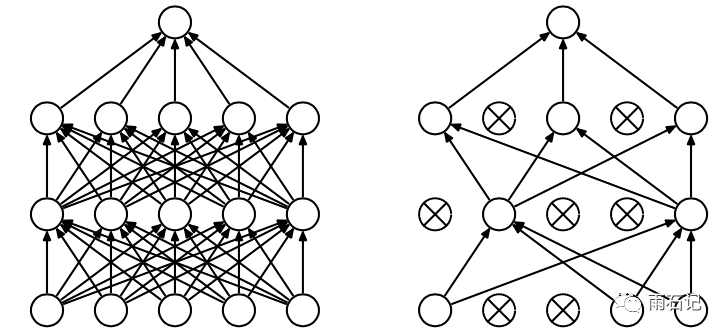
因而,对于一个有N个节点的神经网络,有了dropout后,就可以看做是2n个模型的集合了,但此时要训练的参数数目却是不变的,这就解脱了费时的问题。
动机论
虽然直观上看dropout是ensemble在分类性能上的一个近似,然而实际中,dropout毕竟还是在一个神经网络上进行的,只训练出了一套模型参数。那么他到底是因何而有效呢?这就要从动机上进行分析了。论文中作者对dropout的动机做了一个十分精彩的类比:
在自然界中,在中大型动物中,一般是有性繁殖,有性繁殖是指后代的基因从父母两方各继承一半。但是从直观上看,似乎无性繁殖更加合理,因为无性繁殖可以保留大段大段的优秀基因。而有性繁殖则将基因随机拆了又拆,破坏了大段基因的联合适应性。
但是自然选择中毕竟没有选择无性繁殖,而选择了有性繁殖,须知物竞天择,适者生存。我们先做一个假设,那就是基因的力量在于混合的能力而非单个基因的能力。不管是有性繁殖还是无性繁殖都得遵循这个假设。为了证明有性繁殖的强大,我们先看一个概率学小知识。
比如要搞一次袭击,两种方式:
-
集中50人,让这50个人密切精准分工,搞一次大爆破。 -
将50人分成10组,每组5人,分头行事,去随便什么地方搞点动作,成功一次就算。
哪一个成功的概率比较大?显然是后者。因为将一个大团队作战变成了游击战。
那么,类比过来,有性繁殖的方式不仅仅可以将优秀的基因传下来,还可以降低基因之间的联合适应性,使得复杂的大段大段基因联合适应性变成比较小的一个一个小段基因的联合适应性。
dropout也能达到同样的效果,它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
个人补充一点:那就是植物和微生物大多采用无性繁殖,因为他们的生存环境的变化很小,因而不需要太强的适应新环境的能力,所以保留大段大段优秀的基因适应当前环境就足够了。而高等动物却不一样,要准备随时适应新的环境,因而将基因之间的联合适应性变成一个一个小的,更能提高生存的概率。
dropout带来的模型的变化
而为了达到ensemble的特性,有了dropout后,神经网络的训练和预测就会发生一些变化。
-
训练层面
无可避免的,训练网络的每个单元要添加一道概率流程。
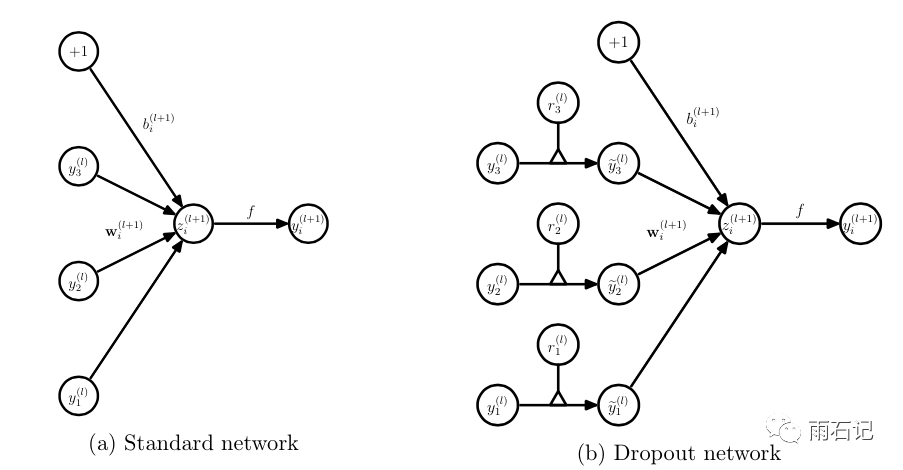
对应的公式变化如下如下:
-
没有dropout的神经网络
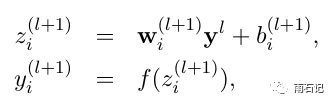
-
有dropout的神经网络
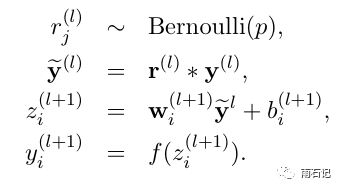
-
测试层面
预测的时候,每一个单元的参数要预乘以p。
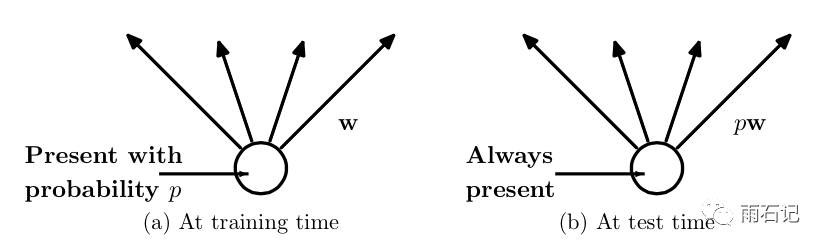
论文中的其他技术点
-
防止过拟合的方法:
-
提前终止(当验证集上的效果变差的时候) -
L1和L2正则化加权 -
soft weight sharing -
dropout -
dropout率的选择
-
经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。 -
dropout也可以被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数。使得输入变化不会太大(0.8) -
训练过程
-
对参数w的训练进行球形限制(max-normalization),对dropout的训练非常有用。 -
球形半径c是一个需要调整的参数。可以使用验证集进行参数调优 -
dropout自己虽然也很牛,但是dropout、max-normalization、large decaying learning rates and high momentum组合起来效果更好,比如max-norm regularization就可以防止大的learning rate导致的参数blow up。 -
使用pretraining方法也可以帮助dropout训练参数,在使用dropout时,要将所有参数都乘以1/p。 -
部分实验结论
该论文的实验部分很丰富,有大量的评测数据。
-
使用weight-scaling来做预测的均值化 -
使用mente-carlo方法来做预测。即对每个样本根据dropout率先sample出来k个net,然后做预测,k越大,效果越好。 -
标准神经网络,节点之间的相关性使得他们可以合作去fix其他节点中的噪声,但这些合作并不能在unseen data上泛化,于是,过拟合,dropout破坏了这种相关性。在autoencoder上,有dropout的算法更能学习有意义的特征(不过只能从直观上,不能量化)。 -
产生的向量具有稀疏性。 -
保持隐含节点数目不变,dropout率变化;保持激活的隐节点数目不变,隐节点数目变化。 -
L2 weight decay -
lasso -
KL-sparsity -
max-norm regularization -
dropout -
maxout 神经网络中的另一种方法,Cifar-10上超越dropout
-
文本分类上,dropout效果提升有限,分析原因可能是Reuters-RCV1数据量足够大,过拟合并不是模型的主要问题
-
dropout与其他standerd regularizers的对比
-
特征学习
-
数据量小的时候,dropout效果不好,数据量大了,dropout效果好
-
模型均值预测
-
Multiplicative Gaussian Noise 使用高斯分布的dropout而不是伯努利模型dropout
-
dropout的缺点就在于训练时间是没有dropout网络的2-3倍。
进一步需要了解的知识点
dropout RBM Marginalizing Dropout 具体来说就是将随机化的dropout变为确定性的,比如对于Logistic回归,其dropout相当于加了一个正则化项。 Bayesian neural network对稀疏数据特别有用,比如medical diagnosis, genetics, drug discovery and other computational biology applications
噪声派
参考文献中第二篇论文中的观点,也很强有力。
观点
观点十分明确,就是对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation,因为,总可以找到一个样本,使得在原始的网络上也能达到dropout单元后的效果。比如,对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,那么总能找到一个样本,使得结果也是如此。这样,每一次dropout其实都相当于增加了样本。
稀疏性
知识点A
首先,先了解一个知识点:
When the data points belonging to a particular class are distributed along a linear manifold, or sub-space, of the input space, it is enough to learn a single set of features which can span the entire manifold. But when the data is distributed along a highly non-linear and discontinuous manifold, the best way to represent such a distribution is to learn features which can explicitly represent small local regions of the input space, effectively “tiling” the space to define non-linear decision boundaries.
大致含义就是:在线性空间中,学习一个整个空间的特征集合是足够的,但是当数据分布在非线性不连续的空间中的时候,则学习局部空间的特征集合会比较好。
知识点B
假设有一堆数据,这些数据由M个不同的非连续性簇表示,给定K个数据。那么一个有效的特征表示是将输入的每个簇映射为特征以后,簇之间的重叠度最低。使用A来表示每个簇的特征表示中激活的维度集合。重叠度是指两个不同的簇的Ai和Aj之间的Jaccard相似度最小,那么:
-
当K足够大时,即便A也很大,也可以学习到最小的重叠度 -
当K小M大时,学习到最小的重叠度的方法就是减小A的大小,也就是稀疏性。
上述的解释可能是有点太专业化,比较拗口。主旨意思是这样,我们要把不同的类别区分出来,就要是学习到的特征区分度比较大,在数据量足够的情况下不会发生过拟合的行为,不用担心。但当数据量小的时候,可以通过稀疏性,来增加特征的区分度。
因而有意思的假设来了,使用了dropout后,相当于得到更多的局部簇,同等的数据下,簇变多了,因而为了使区分性变大,就使得稀疏性变大。
为了验证这个数据,论文还做了一个实验,如下图:
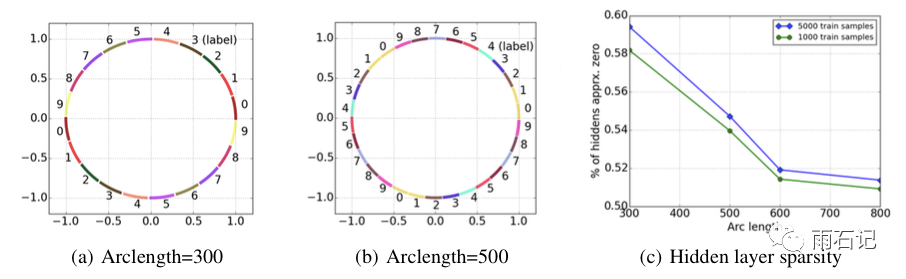
该实验使用了一个模拟数据,即在一个圆上,有15000个点,将这个圆分为若干个弧,在一个弧上的属于同一个类,一共10个类,即不同的弧也可能属于同一个类。改变弧的大小,就可以使属于同一类的弧变多。
实验结论就是当弧长变大时,簇数目变少,稀疏度变低。与假设相符合。
个人观点:该假设不仅仅解释了dropout何以导致稀疏性,还解释了dropout因为使局部簇的更加显露出来,而根据知识点A可得,使局部簇显露出来是dropout能防止过拟合的原因,而稀疏性只是其外在表现。
论文中的其他技术知识点
-
将dropout映射回的样本训练一个完整的网络,可以达到dropout的效果。 -
dropout由固定值变为一个区间,可以提高效果 -
将dropout后的表示映射回输入空间时,并不能找到一个样本x *使得所有层都能满足dropout的结果,但可以为每一层都找到一个样本,这样,对于每一个dropout,都可以找到一组样本可以模拟结果。 -
dropout对应的还有一个dropConnect,公式如下: -
dropout
-
dropConnect
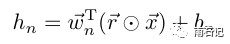
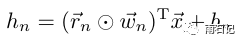
-
试验中,纯二值化的特征的效果也非常好,说明了稀疏表示在进行空间分区的假设是成立的,一个特征是否被激活表示该样本是否在一个子空间中。
参考文献
[1]. Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[2]. Dropout as data augmentation. http://arxiv.org/abs/1506.08700
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



