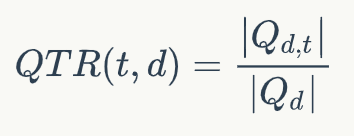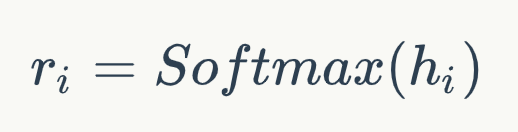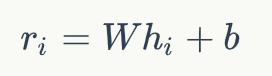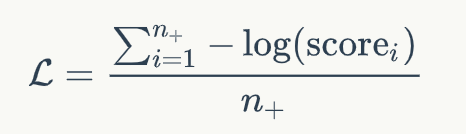背景提高机器阅读理解(MRC)能力以及开放领域问答(QA)能力是自然语言处理(NLP)领域的一大重要目标。在人工智能领域,很多突破性的进展都基于一些大型公开的数据集。比如在计算机视觉领域,基于对ImageNet数据集研发的物体分类模型已经超越了人类的表现。类似的,在语音识别领域,一些大型的语音数据库,同样使得了深度学习模型大幅提高了语音识别的能力。近年来,为了提高模型的自然语言理解能力,越来越多的MRC和QA数据集开始涌现。但是,这些数据集或多或少存在一些缺陷,比如数据量不够、依赖人工构造Query等。针对这些问题,微软提出了一个基于大规模真实场景数据的阅读理解数据集MS MARCO (Microsoft Machine Reading Comprehension)[1]。该数据集基于Bing搜索引擎和Cortana智能助手中的真实搜索查询产生,包含100万查询,800万文档和18万人工编辑的答案。基于MS MARCO数据集,微软提出了两种不同的任务:一种是给定问题,检索所有数据集中的文档并进行排序,属于文档检索和排序任务;另一种是根据问题和给定的相关文档生成答案,属于QA任务。在美团业务中,文档检索和排序算法在搜索、广告、推荐等场景中都有着广泛的应用。此外,直接在所有候选文档上进行QA任务的时间消耗是无法接受的,QA任务必须依靠排序任务筛选出排名靠前的文档,而排序算法的性能直接影响到QA任务的表现。基于上述原因,我们主要将精力放在基于MS MARCO的文档检索和排序任务上。自2018年10月MACRO文档排序任务发布后,迄今吸引了包括阿里巴巴达摩院、Facebook、微软、卡内基梅隆大学、清华等多家企业和高校的参与。在美团的预训练MT-BERT平台[14]上,我们提出了一种针对该文本检索任务的BERT算法方案,称之为DR-BERT(Enhancing BERT-based Document Ranking Model with Task-adaptive Training and OOV Matching Method)。DR-BERT是第一个在官方评测指标MRR@10上突破0.4的模型,且在2020年5月21日(模型提交日)-8月12日期间位居榜首,主办方也单独发表推文表示了祝贺,如下图1所示。DR-BERT模型的核心创新主要包括领域自适应的预训练、两阶段模型精调及两种OOV(Out of Vocabulary)匹配方法。图1 官方祝贺推文及MARCO 排行榜相关介绍Learning to Rank在信息检索领域,早期就已经存在很多机器学习排序模型(Learning to Rank)用来解决文档排序问题,包括LambdaRank[2]、AdaRank[3]等,这些模型依赖很多手工构造的特征。而随着深度学习技术在机器学习领域的流行,研究人员提出了很多神经排序模型,比如DSSM[4]、KNRM[5]等。这些模型将问题和文档的表示映射到连续的向量空间中,然后通过神经网络来计算它们的相似度,从而避免了繁琐的手工特征构建。图2 Pointwise、Pairwise、Listwise训练的目标根据学习目标的不同,排序模型大体可以分为Pointwise、Pairwise和Listwise。这三种方法的示意图如上图2所示。其中,Pointwise方法直接预测每个文档和问题的相关分数,尽管这种方法很容易实现,然而对于排序来说,更重要的是学到不同文档之间的排序关系。基于这种思想,Pairwise方法将排序问题转换为对两两文档的比较。具体来讲,给定一个问题,每个文档都会和其他的文档两两比较,判断该文档是否优于其他文档。这样的话,模型就学习到了不同文档之间的相对关系。然而,Pairwise的排序任务存在两个问题:第一,这种方法优化两两文档的比较而非更多文档的排序,跟文档排序的目标不同;第二,随机从文档中抽取Pair容易造成训练数据偏置的问题。为了弥补这些问题,Listwise方法将Pairwsie的思路加以延伸,直接学习排序之间的相互关系。根据使用的损失函数形式,研究人员提出了多种不同的Listwise模型。比如,ListNet[6]直接使用每个文档的top-1概率分布作为排序列表,并使用交叉熵损失来优化。ListMLE[7]使用最大似然来优化。SoftRank[8]直接使用NDCG这种排序的度量指标来进行优化。大多数研究表明,相比于Pointwise和Pairwise方法,Listwise的学习方式能够产生更好的排序结果。BERT自2018年谷歌的BERT[9]的提出以来,预训练语言模型在自然语言处理领域取得了很大的成功,在多种NLP任务上取得了SOTA效果。BERT本质上是一个基于Transformer架构的编码器,其取得成功的关键因素是利用多层Transoformer中的自注意力机制(Self-Attention)提取不同层次的语义特征,具有很强的语义表征能力。如图3所示,BERT的训练分为两部分,一部分是基于大规模语料上的预训练(Pre-training),一部分是在特定任务上的微调(Fine-tuning)。图3 BERT的结构和训练模式在信息检索领域,很多研究人员也开始使用BERT来完成排序任务。比如,[10][11]就使用BERT在MS MARCO上进行实验,得到的结果大幅超越了当时最好的神经网络排序模型。[10]使用了Pointwise学习方式,而[11]使用了Pairwise学习方式。这些工作虽然取得了不错的效果,但是未利用到排序本身的比较信息。基于此,我们结合BERT本身的语义表征能力和Listwise排序,取得了很大的进步。模型介绍任务描述
2. MARCO是标注不充分的数据集合。换句话说,许多和问题相关的文档未被标注为1,这些噪声容易造成模型过拟合。第一阶段的模型可以用来过滤训练数据中的噪声,从而可以有更好的数据监督第二阶段的精调模型。解决OOV的错误匹配问题在BERT中,为了减少词表的规模以及解决Out-of-vocabulary(OOV)的问题,使用了WordPiece方法来分词。WordPiece会把不在词表里的词,即OOV词拆分成片段,如图6所示,原始的问题中包含词“bogue”,而文档中包含词“bogus”。在WordPiece方法下,将“bogue”切分成”bog”和“##ue”,并且将“bogus”切分成”bog”和“##us”。我们发现,“bogus”和“bogue”是不相关的两个词,但是由于WordPiece切分出了匹配的片段“bog”,导致两者的相关性计算分数比较高。图6 BERT WordPiece处理前/后的文本为了解决这个问题,我们提出了一种是对原始词(WordPiece切词之前)做精准匹配的特征。所谓“精确匹配”,指的是某个词在文档和问题中同时出现。精准匹配是信息检索和机器阅读理解中非常重要的一个技术。根据以往的研究,很多阅读理解模型加入该特征之后都可以有一定的效果提升。具体的,在Fine-tuning阶段,我们对于每个词构造了一个精准匹配特征,该特征表示该单词是否出现在问题以及文档中。在编码阶段之前,我们就将这个特征映射到一个向量,和原本的Embedding进行组合: 图7 词还原机制的工作原理除此之外,我们还提出了一种词还原机制如图7所示,词还原机制能够将WordPiece切分的Subtoken的表示合并,从而能更好地解决OOV错误匹配的问题。具体来说,我们使用Average Pooling对Subtoken的表示合并作为隐层的输入。除此之外,如上图7所示,我们使用了MASK处理Subtoken对应的非首位的隐层位置。值得注意的是,词还原机制也能很好地避免模型的过拟合问题。这是因为MARCO的集合标注是比较稀疏的,换句话说,有很多正例未被标注为1,因此容易导致模型过拟合这些负样本。词还原机制一定程度上起到了Dropout的作用。总结与展望以上内容就对我们提出的DR-BERT模型进行了详细的介绍。我们提出的DR-BERT模型主要采用了任务自适应预训练以及两阶段模型精调训练。除此之外,还提出了词还原机制和精确匹配特征提高OOV词的匹配效果。通过在大规模数据集MS MARCO的实验,充分验证了该模型的优越性,希望这些能对大家有所帮助或者启发。参考文献[1] Payal Bajaj, Daniel Campos, et al. 2016. "MS MARCO: A Human Generated MAchine Reading COmprehension Dataset" NIPS.[2] Christopher J. C. Burges, Robert Ragno, et al. 2006. "Learning to Rank with Nonsmooth Cost Functions" NIPS.[3] Jun Xu and Hang Li. 2007. "AdaRank: A Boosting Algorithm for Information Retrieval". SIGIR.[4] Po-Sen Huang, Xiaodong He, et al. 2013. "Learning deep structured semantic models for web search using clickthrough data". CIKM.[5] Chenyan Xiong, Zhuyun Dai, et al. 2017. "End-to-end neural ad-hoc ranking with kernel pooling". SIGIR.[6] Zhe Cao, Tao Qin, et al. 2007. "Learning to rank: from pairwise approach to listwise approach". ICML.[7] Fen Xia, Tie-Yan Liu, et al. 2008. "Listwise Approach to Learning to Rank: Theory and Algorithm". ICML.[8] Mike Taylor, John Guiver, et al. 2008. "SoftRank: Optimising Non-Smooth Rank Metrics". In WSDM.[9] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. 2018. "Bert: Pre-training of deep bidirectional transformers for language understanding". arXiv preprint arXiv:1810.04805.[10] Rodrigo Nogueira and Kyunghyun Cho. 2019. "Passage Re-ranking with BERT". arXiv preprint arXiv:1901.04085 (2019).[11] Rodrigo Nogueira, Wei Yang, Kyunghyun Cho, and Jimmy Lin. 2019. "Multi-stage document ranking with BERT". arXiv preprint arXiv:1910.14424 (2019).[12] Zhuyun Dai and Jamie Callan. 2019. "Context-aware sentence/passage term importance estimation for first stage retrieval". arXiv preprint arXiv:1910.10687 (2019)[13] Hiroshi Mamitsuka. 2017. "Learning to Rank: Applications to Bioinformatics".