【干货】ICML2018:63篇强化学习论文精华解读!


新智元推荐
来源:专知(ID:Quan_Zhuanzhi)
作者:Jian Zhang 编译:Sanglei, Shengsheng
【新智元导读】机器学习顶会ICML 2018从2473份提交论文中接收了621篇,其中有63余篇强化学习相关论文,作者将这些论文分成了多个类别,并对每篇文章的核心贡献做了精炼的总结,这些文章也是追踪强化学习最前沿技术的绝佳材料,精炼的总结也也便于我们快速查找与自己研究相关的文章。

ICML 2018会议概述
从2,473份提交论文中接收了621份,论文接受率为25.1%。
有关增强学习的会议占据了最大的会议室,而且论文数量也是最多的,这篇综述将主要总结增强学习的录用论文
强化学习分类
我将接受的所有RL论文分类为以下主题:
强化学习理论(Theory)--- 8篇
强化学习网络(Network)---3篇
强化学习算法(Algorithms)6篇
强化学习优化(Optimization)8篇
强化学习探索(Exploration)4篇
强化学习激励(Reward) 4篇
基于模型的强化学习(Model-based)5篇
分布式强化学习(Distributed)3篇
层次强化学习(Hierarchical)5篇
多智能体(Multi-agent)6篇
元学习(Meta-learning)迁移(Transfer)终身学习(Lifelong Learning) 5篇
应用及其它(Applications)6篇
1. RL Theory:
Problem DependentReinforcement Learning Bounds Which Can Identify Bandit Structure in MDPs -> 非标准转换模型,学习将MPDs转换为MACs。
Learning with Abandonment-> 非标准转换模型,一个想要为每个用户学习个性化策略的平台,但该平台面临用户在不满意平台操作时放弃平台的风险。
Global Convergence ofPolicy Gradient Methods for the Linear Quadratic Regulator -> LQR证明
More Robust Doubly RobustOff-policy Evaluation -> 通过另一个策略生成的数据来估计策略的性能。
Best Arm Identification inLinear Bandits with Linear Dimension Dependency->利用全局线性结构来提高对接近最优臂的奖励估计。
Convergent Tree Backup andRetrace with Function Approximation->稳定高效的基于梯度的算法,使用二次凸凹鞍点公式
Time Limits inReinforcement Learning -> 正式解释了在案例中如何有效地处理时间限制,并解释了为什么不这样做会引起经验重复的状态混淆和失效,导致次优策略和训练不稳定。对于固定期限,由于时间限制的终止实际上是环境的一部分,因此剩余时间的概念应该作为代理输入的一部分,以避免违反Markov属性。
Configurable MarkovDecision Processes-> 在许多现实问题中,有可能在一定程度上配置一些环境参数,以提高学习代理的性能。一种新的学习算法—安全策略模型迭代(SPMI),联合自适应地优化策略和环境配置。
2. RL Network:
Structured Control Netsfor Deep Reinforcement Learning ->提出的结构化控制网将通用MLP分成两个独立的子模块:非线性控制模块和线性控制模块。非线性控制用于前视和全局控制,而线性控制稳定围绕全局控制残差的局部动态
Gated Path PlanningNetworks ->将VINs重构为递归卷积网络,这表明VINs将周期性卷积与非传统的最大池化激活相结合。门控循环更新方程可以缓解困扰VIN的优化问题。
Universal Planning Networks: Learning GeneralizableRepresentations for Visuomotor Control ->这个规划计算在一个潜在的空间中展开一个正向模型,通过梯度下降轨迹优化来推断一个最优的行动计划,优化一个监督模拟学习目标。在解决基于图像的目标描述的新任务时,学习到的表示还提供了使用图像指定目标的度量。
3. RL Algorithms:
SBEED: ConvergentReinforcement Learning with Nonlinear Function Approximation->使用Nesterov的平滑技术和Legendre-Fenchel 变换将Bellman方程重构为一个新的原始对偶优化问题,开发一种新的算法,称为平滑Bellman误差嵌入,以解决这个优化问题可以使用任何可微函数类。
Scalable Bilinear PiLearning Using State and Action Features->对于大规模马尔可夫决策过程(MDP),我们研究近似线性规划的原始对偶公式,并开发一种可扩展的,无模型的算法,称为双线性pi学习,用于在提供采样oracle时的强化学习。
Beyond the One-Step GreedyApproach in Reinforcement Learning->分析了多步超前策略改进的情况;制定多步策略改进的变体,使用这些定义推导出新的算法并证明它们的收敛性。
Importance WeightedTransfer of Samples in Reinforcement Learning->从一组源任务中收集的经验样本的转移,以改进给定目标任务中的学习过程。提出了一种基于模型的技术,该技术可以自动评估每个源样本的相关性(重要性权重)来解决目标任务。
Addressing Function ApproximationError in Actor- Critic Methods->算法建立在双Q学习的基础上,通过取一对批评者之间的最小值来限制过高估计;延迟策略更新以减少每次更新错误。
Policy Optimization withDemonstrations->利用可用的演示,通过在已学习的策略和当前演示之间实施占用度量匹配来指导探索,以实现隐式动态奖励形成。
4. RL Optimization:
Policy Optimization asWasserstein Gradient Flows->在概率度量空间上,策略优化在分布优化方面变为凸,解释为Wasserstein梯度流。
Clipped Action PolicyGradient ->利用被剪裁的动作的知识来减少估计的方差。
Fourier Policy Gradients ->将期望策略梯度产生的积分重新整合为卷积并将其转换为乘法。
Structured Evolution withCompact Architectures for Scalable Policy Optimization->通过使用结构化随机正交矩阵的梯度近似进行黑盒优化,提供比基线更准确的估计,并具有可证明的理论保证。
StochasticVariance-Reduced Policy Gradient->利用重要性权重来保持梯度估计的无偏差。
The Mirage ofAction-Dependent Baselines in Reinforcement Learning ->分解了策略梯度估计量的方差,数值模拟表明,在通常测试的基准域中,学习的依赖状态动作的基线实际上并没有减少与状态相关的基线的方差。
Smoothed Action ValueFunctions for Learning Gaussian Policies->一个由高斯平滑的期望Q值定义的行为值的新概念。由平滑Q值函数的梯度和Hessian可以恢复参数化高斯策略的预期奖励的梯度和协方差。在训练过程中学习均值和协方差的能力可以显著提高标准连续控制基准的结果。
Soft Actor-Critic:Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor->提出了soft actor-critic,基于最大熵强化学习框架的非策略行动者-评论者(actor-critic)深度RL算法。行动者的目标是最大化预期的回报,同时也最大化熵——在任务中尽可能随机地成功。
5. RL Exploration:
Self-Imitation Learning ->利用过去的良好经验可以间接地推动深度探索。
Coordinated Exploration inConcurrent Reinforcement Learning ->强化学习代理团队,该团队通过种子取样,同时学习如何在一个共同的环境中操作。具有三个属性- 适应性,承诺和多样性 – 是有效协调探索所必需的。
GEP-PG: DecouplingExploration and Exploitation in Deep Reinforcement Learning Algorithms ->依次结合目标探索过程和DDPG。两阶段方法:第一个探索阶段发现一系列简单的策略,最大化行为多样性,忽略奖励功能;然后是更标准的深度RL阶段进行微调,其中DDPG使用重播缓冲区,其中填充了GEP生成的示例。
Learning to Explore viaMeta-Policy Gradient ->元策略梯度算法学习探索,使我们能够自适应地学习DDPG中的探索策略。训练不依赖于参与者策略的灵活的探索行为,从而产生一种全局性的探索,极大地加快了学习过程。
6. RL Reward:
Learning byPlaying — Solving Sparse Reward Tasks from Scratch->计划辅助控制(SAC-X), 代理配备了一组通用辅助任务,它试图通过非策略RL同时学习。主动(学习)调度和辅助策略的执行允许代理有效地探索其环境 -使其在稀疏奖励RL方面表现优异。
Automatic Goal Generationfor Reinforcement Learning Agents ->使用生成模型(在本例中为GANs)来学习生成理想的“目标”(状态空间的子集),并使用生成模型而不是目标的统一抽样。使用基于生成模型的自动课程生成算法来解决多任务问题,该生成模型跟踪学习代理的性能。
Learning the RewardFunction for a Misspecified Model ->本文提出了一个新的误差界限,用来解释从模型中采样的状态下奖励模型的行为。该界限用于扩展现有的幻觉DAgger-MC算法,该算法在确定性的MDPs中提供了理论性能保证,而不是假设一个完美的模型可以被学习。
Mix & Match — AgentCurricula for Reinforcement Learning ->一个自动形成代理课程的程序;通过有效地从简单的代理中找到解决方案开始,逐步训练更复杂的代理;
7. Model-based RL:
Lipschitz Continuity inModel-based Reinforcement Learning ->提供了一个新的边界,在这个边界上,我们用Wasserstein度量来量化Lipschitz模型的多步预测误差。
ProgrammaticallyInterpretable Reinforcement Learning ->生成可解释和可验证的代理策略,可编程的解释性强化学习使用一种高级的、特定于域的编程语言来表示策略。神经导向的程序搜索通过首先学习使用DRL的神经策略网络,然后对程序策略执行局部搜索,以尽量减少与神经“oracle”之间的距离。
Feedback-Based Tree Searchfor Reinforcement Learning -> 提出了一种基于模型的强化学习技术,该技术迭代地将MCTS应用于原始的无限大范围的马尔可夫决策过程中。MCTS过程生成的建议随后作为反馈提供,以便通过分类和回归改进下一个迭代的叶子节点评估程序。多玩家在线战斗竞技场(MOBA)游戏之王的竞争代理。
Machine Theory of Mind->Theory of Mind(ToM)广泛地指人类表达他人心理状态的能力, 包括他们的欲望,信仰和意图。ToMnet使用元学习来学习代理人未来行为的强大先验模型,并且仅使用少量的行为观察,可以引导到更丰富的关于代理特征和心理状态的预测。
Measuring abstractreasoning in neural networks ->提出一个数据集和挑战,旨在探索抽象推理,灵感来自一个著名的人类智商测试。为了在这一挑战中取得成功,模型必须应对训练和测试数据以明确定义的方式存在差异的各种归纳“机制”。提出WildRelation Network(WReN),多次应用关系网络模块(Santoro et al., 2017)来推断小组间关系。
8. Distributed RL:
Implicit Quantile Networksfor Distributional Reinforcement Learning ->使用分位数回归来近似风险敏感策略的状态-行为回报分布的完全分位数函数;展示了57款Atari2600游戏的改进性能。
RLlib: Abstractions forDistributed Reinforcement Learning->开源Ray项目中的一个库,为RL提供可扩展的软件基元,该库主张通过自顶向下的层次控制调整算法,以组合的方式分布RL组件,从而在短期运行的计算任务中封装并行性和资源需求。
IMPALA: ScalableDistributed Deep-RL with Importance Weighted Actor-Learner Architectures->IMPALA(重要性加权行动者学习者架构)可扩展到数千台机器而不会牺牲数据 效率或资源利用率; 通过将解耦作用和学习与一种新的非策略修正方法V-trace相结合,实现高吞吐量下的稳定学习。在DMLab-30(DeepMind Lab环境中的30个任务集(Beattie et al., 2016))和Atari-57 (Arcade Learningenvironment中所有可用的Atari游戏(Bellemare et al., 2013a)上进行测试)。
9. Hierarchical RL:
Latent Space Policies forHierarchical Reinforcement Learning ->以自下而上的分层方式构建层次表示;每一层都经过训练,通过最大熵目标来完成任务。每一层都增加了潜在随机变量,这些变量是从该层训练期间的先验分布中抽取的。最大熵目标使这些潜在变量被纳入到层的策略中,高层可以通过这个潜在空间直接控制下层的行为。
Self-Consistent TrajectoryAutoencoder: Hierarchical Reinforcement Learning with Trajectory Embeddings ->层次结构中学习较低层的问题转化为学习轨迹级生成模型的问题。学习轨迹的连续潜在表示,这有效地解决了时间扩展和多阶段的问题。他的模型通过预测闭环策略行为的结果,提供了一个内置的预测机制。
An Inference-Based PolicyGradient Method for Learning Options->为了使用选项自动学习策略,所提出的算法使用推理方法来同时改进代理可用的所有选项,因此可以以非策略方式使用,而无需观察选项标签。所采用的可微差别推理过程产生了易于解释的选项。
Hierarchical Imitation andReinforcement Learning ->分层指导利用底层问题的层次结构来整合不同的专家交互模式。在Montezuma’sRevenge上测试过。
Using Reward Machines forHigh-Level Task Specification and Decomposition in Reinforcement Learning ->奖励机器是一种有限状态机,支持奖励函数的规范,同时将奖励函数结构暴露给学习者并支持分解。提出了奖励机器的Q-Learning(QRM),一种适当分解奖励机制的算法,并利用off-policy Q-Learning同时学习不同组件的子策略。
10. Multi-Agent:
Learning to Coordinatewith Coordination Graphs in Repeated Single-Stage Multi-Agent Decision Problems ->利用松散耦合,即代理之间的条件独立性。预期奖励可以表示为协调图。
Learning to Act inDecentralized Partially Observable MDPs->首先接近最优的协作多智能体,通过混合整数线性规划替换贪婪最大化。来自文献的许多有限域的实验。
Learning PolicyRepresentations in Multiagent Systems->将代理建模作为表示学习的问题;构建模仿学习和代理识别启发的新目标,设计一种代理策略表示的无监督学习算法。
Competitive Multi-agentInverse Reinforcement Learning with Sub-optimal Demonstrations ->当已知专家证明不是最优的时候,在零和随机博弈中进行逆强化学习; 引入了一种新的目标函数,直接将专家与纳什均衡策略对立起来,以深度神经网络作为模型逼近,在逆强化学习的背景下求解奖励函数。
11. RL Meta-learning, Transfer, Continuing and Lifelong Learning::
Been There, Done That:Meta-Learning with Episodic Recall ->提出了一种生成开放但重复的环境的形式主义,然后开发一个元学习体系结构来解决这些环境。该架构将标准的LSTM工作记忆与可微的神经情景记忆融合在一起。
Transfer in Deep RL usingSuccessor Features in GPI->使用通用的策略改进和继承特性来进行传输技能。以两种方式扩展SF和GPI框架。使用奖励函数本身作为未来任务的特性,没有任何表达性的损失,因此无需预先指定一组特性。
Policy and Value Transferin Lifelong Reinforcement Learning ->使用先前的经验,在一系列从任务分配中抽取的任务实例中引导终身学习。对于基于值函数的传输,保留PAC的值函数初始化方法,同时最小化两种学习算法所需的学习,从而产生MaxQInit。
State Abstractions forLifelong Reinforcement Learning ->在终身强化学习中,代理必须有效地跨任务传递知识,同时解决探索,信用分配和一般问题。状态抽象压缩代理使用的表示,从而减少了学习的计算和统计负担。提出新的抽象类:(1)传递状态抽象,其最优形式可以被有效地计算,以及(2)PAC状态抽象,保证相对于任务的分布。
Continual ReinforcementLearning with Complex Synapses->通过为表格和深层强化学习代理配备合并了一种生物复杂性的突触模型(Benna & Fusi,2016),灾难性遗忘可以在多个时间尺度上得到缓解。整合过程与数据分布变化的时间尺度无关。
12. RL Applications and others:
Spotlight: OptimizingDevice Placement for Training Deep Neural Networks->使用多阶段马尔可夫决策过程来模拟设备布局问题。
End-to-end Active ObjectTracking via Reinforcement Learning ->ConvNet-LSTM函数逼近器用于直接帧到动作的预测。需要用奖励函数来增强环境。
Deep ReinforcementLearning in Continuous Action Spaces: a Case Study in the Game of SimulatedCurling ->基于内核的MonteCarlo树搜索学习游戏策略,该搜索在连续空间内查找动作。为了避免手工特征,我们使用监督学习来训练我们的网络,然后使用高保真的冰壶奥林匹克运动模拟器进行强化学习;赢得了国际数字冰壶比赛。
Can Deep ReinforcementLearning Solve Erdos- Selfridge-Spencer Games?->介绍了一个有趣的双人零和游戏系列,具有可调的复杂性,称为Erdos-Selfridge-Spencer游戏,作为RL的一个新域。作者报告了大量的实证结果,使用了各种各样的训练方法,包括监督学习和多种RL (PPO, A2C,DQN)以及 单代理 与多代理训练。
Investigating Human Priorsfor Playing Video Games ->调查各种有助于人类学习的先验知识,并发现对象的一般先验在指导人类游戏玩法中起着最关键的作用。
Visualizing andUnderstanding Atari Agents->介绍一种生成有用的显著性地图的方法,并使用它来显示1)强代理关注什么,2)代理是否出于正确或错误的原因做出决策,3)代理如何在学习过程中进化。
深度强化学习是最大和最热门的话题之一,有着最多的论文数量和最大的会议场地。
除了训练算法,学习模型,信用分配,分层次,元学习和网络架构是RL流行的子方向。
考虑到网络架构上关于视觉问题的论文数量,对于RL在网络架构上的探索还有很大的空间,在已被接受的论文中只有少数是这一方面的。例如,StructuredControl Nets for Deep Reinforcement Learning and Gated Path Planning Networks。
ML的公平性和可解释性是一个大主题。对于RL也应该有更多的解释和分析工作。一个好的方向是运用控制理论。与此相关的是,BenRecth的《控制优化教程》非常棒。主要思想是RL与控制理论之间应该有更多的交叉。在已被接受的论文中,一个很好的例子是Structured ControlNets for Deep Reinforcement Learning。
附最佳论文总结
【两篇最佳论文(best papers)】
“Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples”
[注]:也就是这篇在年初曾引起轩然大波,一作Anish Athalye质疑ICLR2018中的7/8篇对抗防御的论文太渣,并引起Goodfellow围追堵截要说法。Anish Athalye这篇打脸ICLR的文章在ICML上证明了自己的实力。
相关阅读:
https://zhuanlan.zhihu.com/p/33554466
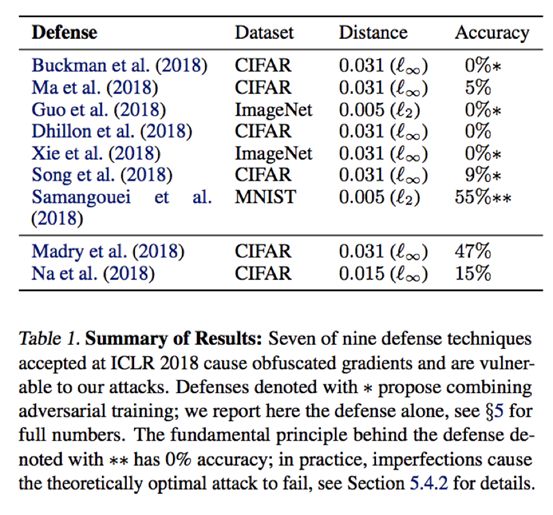
混淆梯度, 是一种梯度掩蔽,在防御对抗的例子中导致一种错误的安全感。
ICLR 2018的白盒安全防御系统,9种当中的7种防御系统依赖于混淆梯度。
对于发现的三种类型的混淆梯度中的每一种,作者都开发了攻击技术来克服它。
在每篇论文所考虑的原始威胁模型中,新的攻击成功地完全绕过了6种,只有一个是部分绕过。
“DelayedImpact of Fair Machine Learning”
训练以尽量减少预测误差的机器学习系统, 往往会表现出基于种族和性别等敏感特征的歧视性行为。原因之一可能是由于数据中存在历史偏差。
这项工作使机器学习的决策与长期的社会福利目标保持一致。
下图显示了作者提出的结果模型, 以减轻机器学习算法的不良社会影响。
依赖于群体的阈值可能面临法律挑战,不可避免的是,它们错失了固定阈值决策可能引发的差异结果。
公平约束(Fairnessconstraints)使群体之间的决策相等,以保护弱势群体。但是,公平约束也会减少已经处于不利地位的人群的福利。
构建一个精确的模型来预测决策对人口结果的影响,可能有助于减轻应用公平约束(fairness constraints)的潜在危害。
【三篇最佳论文提名奖(Best Papers Runner-ups)】
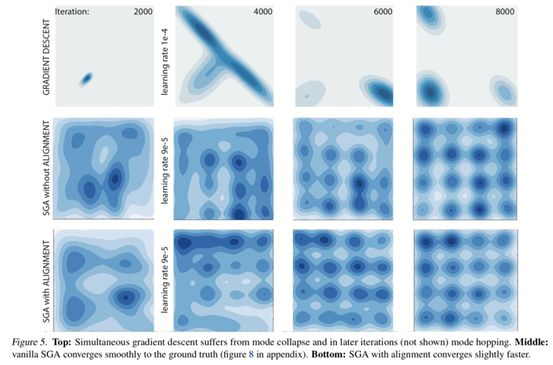
1. “The Mechanics of n-Player Differentiable Games”
l 开发新的技术来理解和控制一般游戏的动力学,例如GAN
l 关键的结果是将二阶动力学分解为两个分量:
l 第一个是与潜在的游戏有关,它会降低隐函数的梯度下降;
l 第二个与哈密顿博弈(Hamiltonian games)有关,哈密顿博弈是一种遵守守恒定律的新游戏,类似于经典机械系统中的守恒定律。
l 分解激发了Symplecti梯度调整(SGA),这是一种新的算法,用于在一般游戏中寻找稳定的定点。
l 基本实验表明,SGA与最近提出的在GANs中找到稳定的固定点的算法相比是有竞争力的,同时在更多普通的游戏中也适用,并且有保证。
2. “Near Optimal Frequent Directions for Sketching Dense and SparseMatrices”
复旦大学的论文Near Optimal Frequent Directions forSketching Dense and Sparse Matrices十分引人注目,这篇斩获“最佳提名奖”的论文由大数据学院副教授黄增峰独立完成,研究的是流模型(streaming model)中的协方差情况。文章提出了一种新型空间优化算法,把流模型运行时间缩短到极致。
计算一个比给定的大矩阵小得多的草图矩阵,使协方差误差最小化。
我们考虑了流模型中存在的问题,该算法在有限的工作空间下只能对输入进行一次传递。
Liberty(2013)及其变体的Frequent Directions算法实现了最佳的空间误差权衡。 但是,是否可以改善运行时间仍然是一个悬而未决的问题。
在本文中,我们几乎解决了这个问题的时间复杂度。 特别是,我们提供新的空间优化算法,运行时间更短。 此外,我们还证明了算法的运行时间几乎是最优的,除非矩阵乘法的最先进的运行时间可以显著提高。
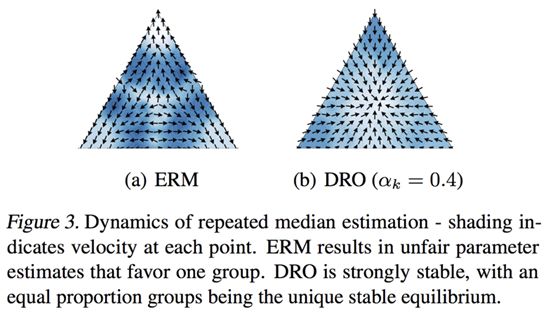
3. “Fairness Without Demographics in Repeated Loss Minimization”
l 最小化平均损失导致表示差异 - 少数群体(例如,非母语人士)对训练目标贡献较少,因此往往遭受更大的损失。由于模型的准确性会影响用户保留率,少数群体的数目会随着时间的推移而缩小。
l 作者指出,经验风险最小化(ERM)随着时间的推移会扩大表征差异,这甚至会使最初的公平模型变得不公平。
l 开发一种基于分布鲁棒优化(DRO)的方法,该方法将经验分布附近所有分布的最坏情况风险最小化。
l 演示了DRO在ERM失败的示例上防止差异放大,并展示了在真实文本自动完成任务中少数群体用户满意度的改进。
原文链接:
https://medium.com/@jianzhang_23841/a-comprehensive-summary-and-categorization-on-reinforcement-learning-papers-at-icml-2018-787f899b14cb
(本文经授权转载自专知,ID:Quan_Zhuanzhi,点击阅读原文查看原文)
新智元AI WORLD 2018大会【早鸟票】开售!
新智元将于9月20日在北京国家会议中心举办AI WORLD 2018 大会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
大会官网:
http://www.aiworld2018.com/
即日起到8月19日,新智元限量发售若干早鸟票,与全球AI领袖近距离交流,见证全球人工智能产业跨越发展。

活动行购票链接:
http://www.huodongxing.com/event/6449053775000
活动行购票二维码:





