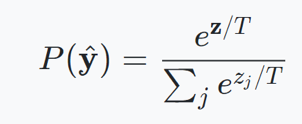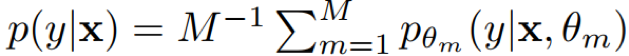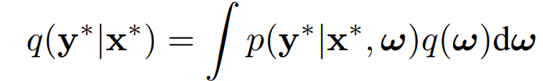©PaperWeekly 原创 · 作者|崔克楠
学校|上海交通大学博士生
研究方向|异构信息网络、推荐系统
本文以 NeurIPS 2019 的 Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift 论文为主线,回顾近年顶级机器学习会议对于 dataset shift 和 out-of-distribution dataset 问题相关的论文,包括了 Temperature scaling
[1]
,DeepEnsemble
[2]
,Monte-Carlo Dropout
[3]
等方法。而
[4]
在统一的数据集上对上述一系列方法,测试了他们在 data shift 和 out-of-distribution 问题上的 accuracy 和 calibration。
![]()
![]()
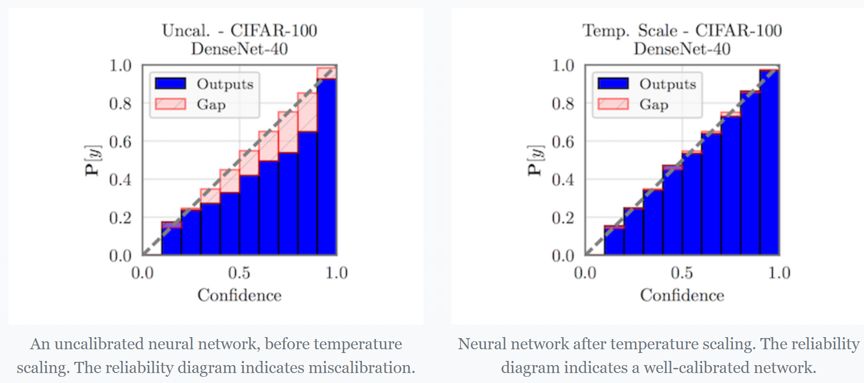
在介绍 temperature scaling 之前,首先需要了解什么叫做 calibrated?
神经网络在分类时会输出“置信度”分数和预测结果。理想情况下,这些分数应该与真实正确性的可能性相匹配。例如,如果我们将 80% 的置信度分配给 100 个样本,那么我们就会期望 80% 样本的预测实际上是正确的。如果是这样,我们说模型是经过校准的。
而 Temperature scaling 则是一个非常简单的后处理步骤,能够帮助模型进行校准。一种可视化校准的简单方法是将精度作为置信度的函数绘制(reliability diagram)。下边左边的可靠性图表中,我们可以看到一个在 CIFAR-100 上训练的 DenseNet 是极度自信的。然而,使用 Temperature scaling,模型就得到了校准。
![]()
具体怎么做 temperature scaling 呢,对于分类问题,网络最后一层往往会输出 logits,而 logits 进一步传给 softmax 函数来得到各个类别的概率,而 temperature scaling 对这一步骤修改为:
![]()
实现层面也很简单,在 PyTorch 的实现如下:
class Model(torch.nn.Module):
def __init__(self):
# ...
self.temperature = torch.nn.Parameter(torch.ones(1))
def forward(self, x):
# ...
# logits = final output of neural network
return logits / self.temperature
但要注意的是,上述方法需要在 validation set 上进行优化,来学习参数 temperature,而不能在 training set 上进行学习,所以 Temperature scaling 是一个 post process,即后处理步骤,这种方法也暂时只能用于分类任务,不能用于回归。
![]()
以往 ensemble 的方法大致分为 randomization-based 的方法,和 boosting based 的方法。前者方法中,ensemble 中的 members 可以并行训练,没有 interaction;后者方法中的 members 之间在训练时是有相互依赖的先后顺序。
而 deep ensemble
[2]
属于前者方法。相比于以往的方法使用部分数据去训练 member,deep ensemble 使用整个训练集去训练 M 个独立随机初始化的网络模型。其训练过程如下图算法所示:
![]()
M 个独立的模型训练完后,对于模型预测使用如下的 uniformly-weighted 的方法进行融合。后文为方便,统称 deep ensemble 为 ensemble 方法。
![]()
MC-Dropout 是为模型引入 uncertainty 特性的最为简单有效的方法之一。以往我们经常在训练时对模型参数使用 dropout,以防止模型过拟合,在 inference 阶段,往往会关闭 dropout。而 MC-dropout 则强调,在 inference 阶段,也要对模型参数进行 dropout。对于一个样本的 inference,MC-Dropout 要求随机进行 K 次 dropout,进行 K 次前传,得到 K 个输出结果。而 K 个输出结果再进行 ensemble。
这么做的目的是因为在贝叶斯网络中,网络模型的参数应当服从特定的分布。模型在预测结果时,应当对模型的参数分布进行积分,而对于如今庞大的模型来说这显然是不可能的。MC-dropout 相当从模型参数的变分分布当中随机采样,将这一“积分”过程变得简单,容易实现。
![]()
![]()
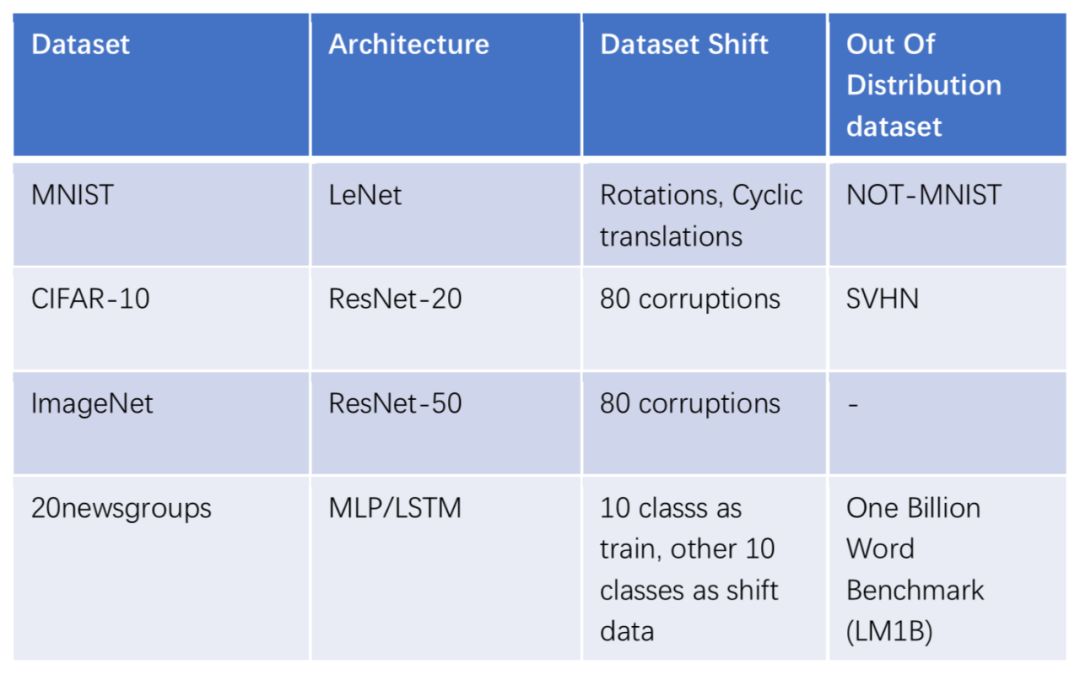
实验主要探讨了上述方法在不同 data shift 和 out of distribution 下,在 accuracy,calibration 等 metric 上的表现。其 data shift 如下图所示,对 ImageNet 和 MNIST 的图片施加不同的 image level 的 corruption。
而 Out-of-distribution 指的是,和训练数据分布不一致的数据集,对于 MNIST 数据集来说,NotMNIST 数据集为 out-of-distribution,而对于 CIFAR 数据集来说,SVHN 数据集为 out-of-distribution。所有的方法均采用相同的网络结构,实验设置汇总到下表所示。
![]()
![]()
![]()
![]()
在 MNIST 数据集上的对比如上图所示,其中 Brier score 越小越好,而 confidence 指的是分类器最大概率类别的置信度分数。经 Stochastic Variational Bayesian Inference (SVI) 在各个 metric 上的表现好。同时也能够发现:
1. 从 a 和 b 上能看出,在有了 data shift 之后,各个模型的 accuracy 都逐渐下降;
2. 从 a,b 中的 Brier score 可以看出,使用 Temperature scaling 在 validation 矫正,能够在 test 上保证 calibration,但在 shift data 上无法保证calibration;
3.
从 c 中可以看出,SVI 在比较高的 confidence 下的 accuracy 最高,说明 SVI 方法比较适合于风险价值较高的应用;
4.
从 e 和 f 中可以看出,这些方法在 OOD 数据上都显示了比较低的 entropy,并且在 OOD 的数据上给出了比较高的 confidence,说明他们对于 OOD 数据预测较为错误。
![]()
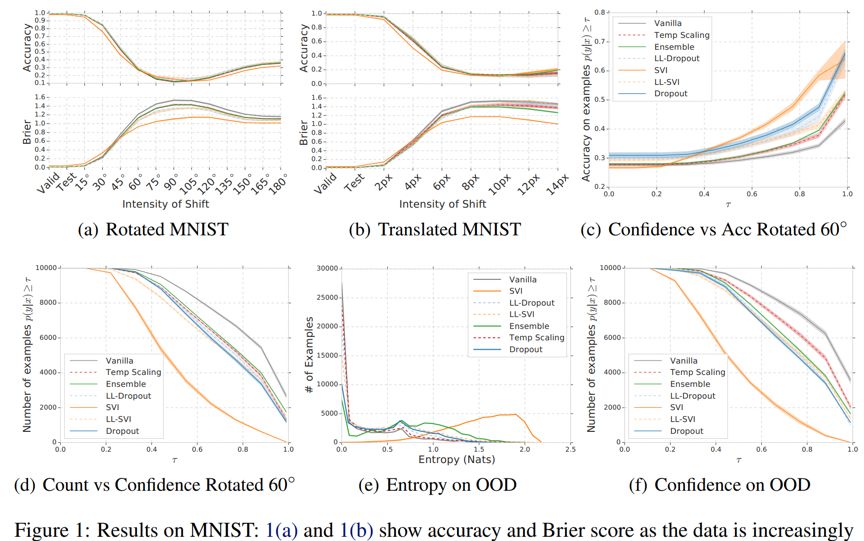
在 ImageNet 数据集上的对比如上图所示,其中 ECE 为 Calibration 指标,越小则代表模型校准的越好。我们可以发现:
1. 所有方法随着 shift 程度的增加(比如图片的模糊程度等),Accuracy 越来越低,ECE 越来越高,代表模型的精确度不断下降,同时校准越来越差;
2. 所有模型在不同 shift 上的 Accuracy 表现差别不大,但是 ensemble 优于所有的模型;
3. 同样,ensemble 在不同的 shift 下,模型仍然保持较好的 calibration 能力;
4. 在 CIFAR 的 OOD 实验上,从 c 图中可以看出,tempreture scaling 的 entropy 最高,ensemble 次之。同样而在 ensemble 方法在 OOD 样本的 confidence 比较低,说明 ensemble 能够保持比较好的 uncertainty 特性。
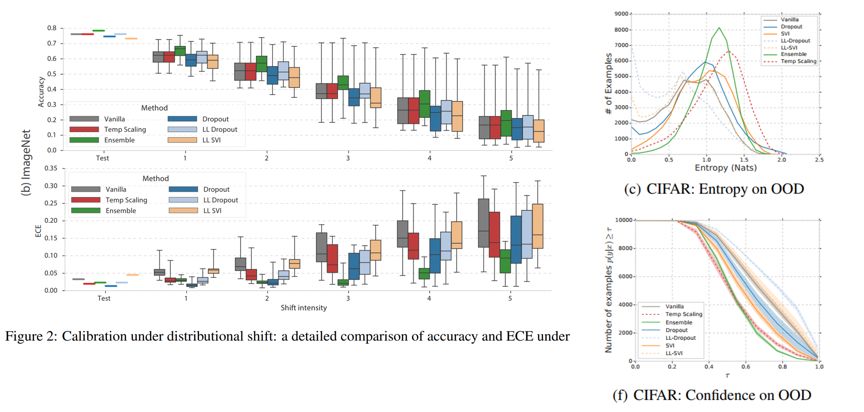
同时作者还发现,在 CIFAR-10 以及文本数据 20Newsgroup 上,ensemble 的表现仍然要优于其他方法,和在 ImageNet 上的表现一致(除了 MNIST 数据集)。而我们也会考虑是否因为 ensemble 方法集成了几个模型,capacity 较大,所以表现较为优异,因此做了如下探究实验。
![]()
如上图所示,作者考虑增加出了 ensemble 外,其他方法所使用的网络的 capacity,得到一系列其他方法在 wide architecture 上的表现,可以看到,增加模型的 capacity 并不能带来在 Accuracy 和 ECE 上的提升。
![]()
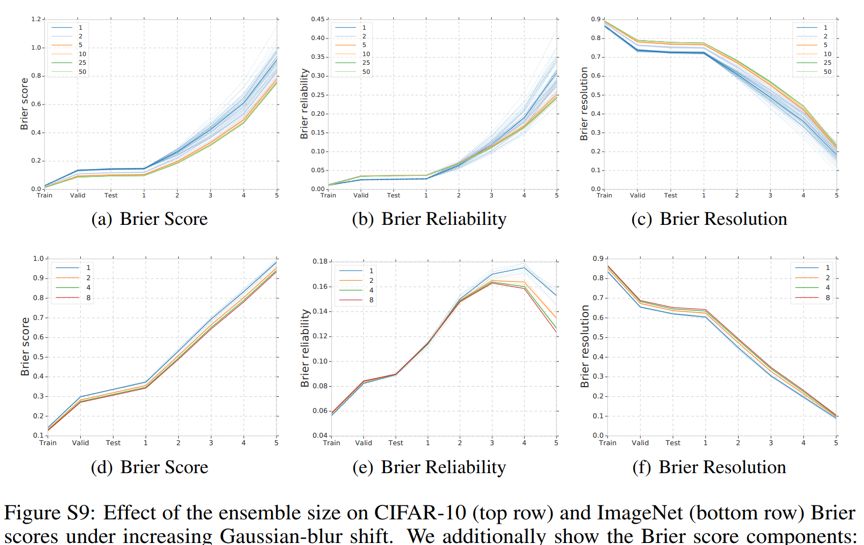
在上图中,作者展示了 ensemble size 对于模型 calibration 的影响,可以看到随着 ensemble size 的提升,Brier Score 是逐渐缩小的,这说明 ensemble size 越大,模型的 calibration 能力是越好的,但超过 50 之后不会再有提升。但考虑到计算负担,一般设置为 5 比较恰当。
![]()
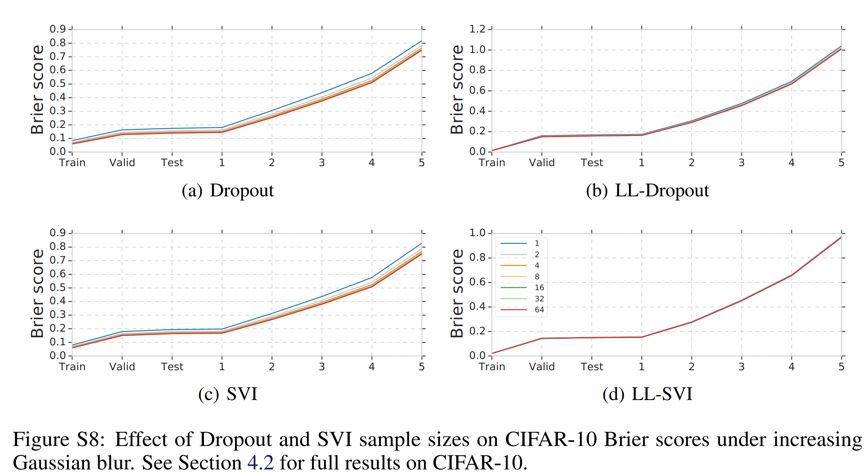
作者也探讨了 sample size 对于采样类方法的影响,可以看到 MC dropout 和 SVI 的 Brier score 随着 sample size 的提升而下降,说明较大的 sample size 对于模型的 calibration 是有帮助的,但也要考虑到计算负担的影响。
![]()
最终作者给出了各个方法的计算和储存方面的效率,可以看到 Ensemble 虽然通常来说表现较好,但是开销往往也是最大的。
1. 模型的 Accuracy 和 Calibration 会随着 data shift 逐渐下降;
2. Temperature scaling 虽然能够在 test set 上保持 calibration,但是在 shift dataset 上却无法达到同样的效果;
3. SVI 在 MNIST 上表现最好,但是在其他所有数据集上,ensemble 表现最为优异。并且他们表现得相对顺序也是一致的;
4. Ensemble 虽然表现较好,但是在计算负担方面不占优势,仍要考虑是否有其他鲁棒的方法。
[1] Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q. On Calibration of Modern Neural Networks. In International Conference on Machine Learning, 2017.
[2] Lakshminarayanan, Balaji, Alexander Pritzel, and Charles Blundell. "Simple and scalable predictive uncertainty estimation using deep ensembles." Advances in neural information processing systems. 2017.
[3] Gal, Y. and Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In ICML, 2016
[4] Snoek, Jasper, et al. "Can you trust your model's uncertainty? Evaluating predictive uncertainty under dataset shift." Advances in Neural Information Processing Systems. 2019.
![]()
点击以下标题查看更多往期内容:
![]() #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
▽ 点击 | 阅读原文 | 下载论文