【KDD20】主题模型在图模型中的应用专题
论文解读者:北邮 GAMMA Lab 硕士生 许斯泳
1 引言
主题模型是一种以无监督方式对文本内容的隐含语义结构进行聚类,发现文档中抽象主题的统计模型,主要被运用于NLP领域中的各种任务。简单总结主题模型的目的,就是从一堆文档中学习两种矩阵:一是document-topic矩阵,即document在主题上的分布,二是topic-word矩阵,即topic在词表上的分布。基于主题模型的思想和功能,已有很多工作将其运用或迁移到其他领域,来提高模型方法的效果。本文将介绍在KDD 2020上发表的两篇在图模型中利用主题模型的工作。
第一个工作是《Graph Structural-topic Neural Network》,主要是将主题模型的统计思想引入到GCNs中,解决GCNs不能很好地建模局部高阶结构的问题。
第二个工作是《Graph Attention Networks over Edge Content-Based Channels》,该工作关注了图中边上的非结构文本信息,利用主题模型发现边的文本信息隐含的丰富语义,从而更好地推理和节点之间的交互。
2 Graph Structural-topic Neural Network

2.1 动机与贡献
GCNs的一个缺点在于对节点的局部结构的建模不是很好,其更多地关注于节点的特征,而对邻域内的高阶结构模式表达能力不够,而更深层的GCN却常常由于过平滑问题使得效果下降。虽然已有工作利用了GCN的高阶模式,但是这种对节点选择少量的结构模式进行建模也是不足够的。因为节点的高阶邻域由很多特征混合的节点构成,从而导致邻域内存在许多结构模式。以下图为例,经理X和教授Y的邻域都具有三种社交关系:家庭,雇员,关注者。其中,雇员这类社交关系,通常会形成层级或树型类似结构,而家庭会形成团状结构,关注者会形成星型结构。对于经理X来说,他通常会领导一个大团队,拥有很多雇员,其社交关系分布中,雇员会占更大比例,对于教授Y来说,他更有影响力,关注者更多。因此这两类节点的邻域结构模式存在分布上的显著差异。将这种现象与主题模型进行对比,这种邻域高阶模式在社交网络上分布的差异可以跟文档中词在主题上的分布可以一一对应起来,并将主题模型方法迁移到图的建模上。

贡献:
1)通过匿名随机游走和提出Graph Anchor LDA对图进行主题建模,方法灵活且高效。
2)提出一个multi-view的GCN,将节点特征与建模了结构的主题特征融合起来。
3)在多个数据集上进行实验,验证了模型GraphSTONE的性能和效率。
2.2 模型
模型的目的是要从整体分布上去考虑局部结构特性,并且高效。其整体框架如下:
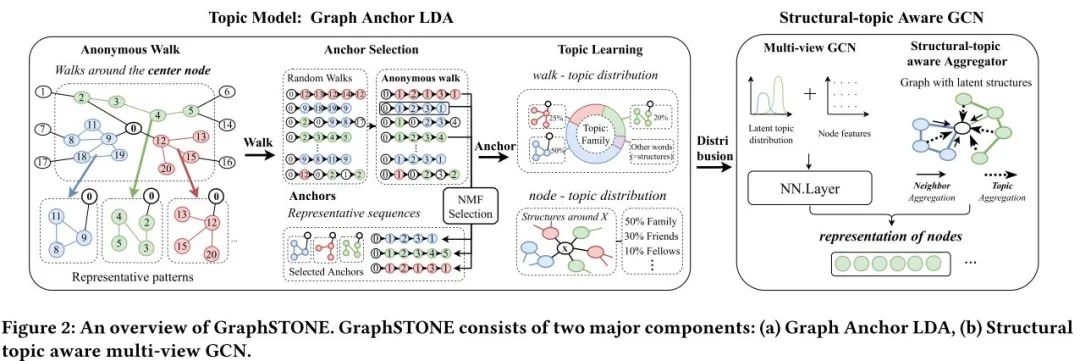
在进行图模型与主题模型的类比与迁移之前,首先介绍匿名随机游走:假如随机游走序列为(0,12,13,12,14,12),其起始节点是0,则转化为匿名随机游走为(0,1,2,1,3,1),这种方式的好处是相同的结构很可能会被编码为相同的序列,这样能够近似代表一种具体的高阶结构。
2.2.1 图结构VS主题模型
在NLP领域的主题模型中,所要学习的两个参数为,每个主题里的单词分布即word-topic分布矩阵U,以及每个文档的主题概率分布即document-topic分布矩阵R。
现建立图中的主题模型:
结构模式(匿名随机游走) = words
从某节点出发采样的随机游走序列集合 = document
在graph中,则可以学习的参数是,每个主题的匿名随机游走序列分布即walk-topic分布矩阵U,以及每个节点的主题概率分布即node-topic分布矩阵R,在图中,节点主题可以看成是节点的社交关系。
2.2.2 Graph Anchor LDA
NLP中,对文本的预处理有去停用词,在graph中的随机游走序列,也存在很多无意义的序列,如果不剔除,则可能在这些大量无意义序列中过拟合而忽略掉很多重要的信息。Graph Anchor LDA目的是想在运用主题模型之前先选择一些指导性的结构,称为“anchors"。
首先定义一个walk-walk共现矩阵M,利用非负矩阵分解抽取anchors:
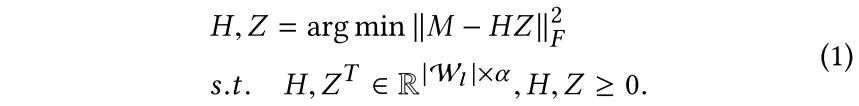
从而找到anchors
然后,经过主题模型的学习,得到两种参数矩阵。
2.2.3 融合结构主题特征和节点属性的图卷积方法
1. 聚合方式:利用主题分布相似性作为聚合的权重
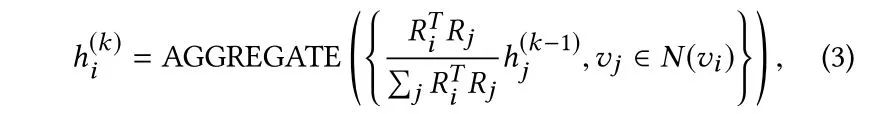
2. Multi-view GCN: 将节点属性和结构主题特征进行拼接,融合
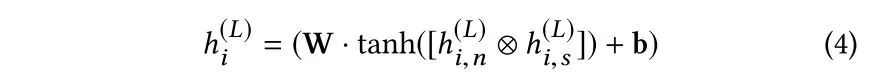
3. 优化目标:同Graphsage
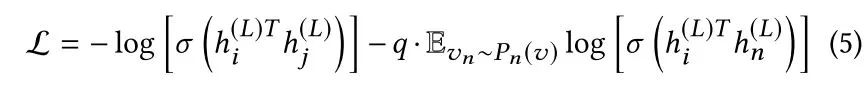
2.3 实验
真实数据集上的实验包括链路预测和节点分类任务:
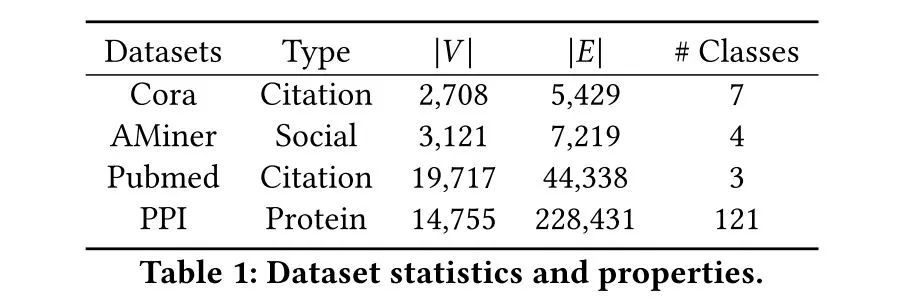
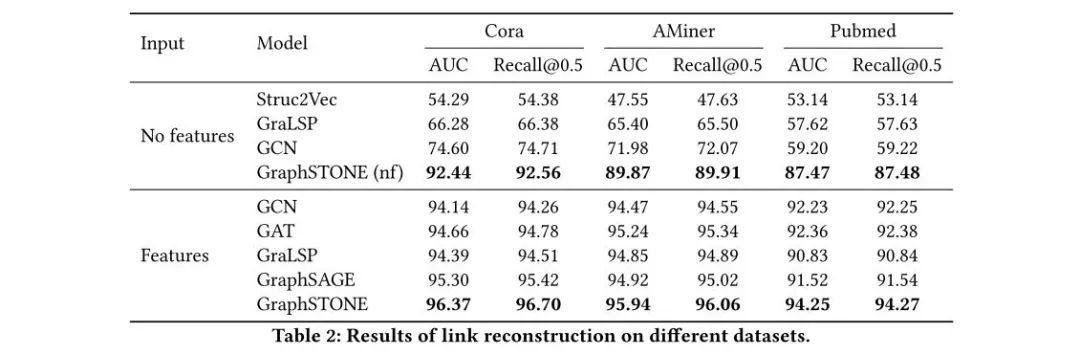
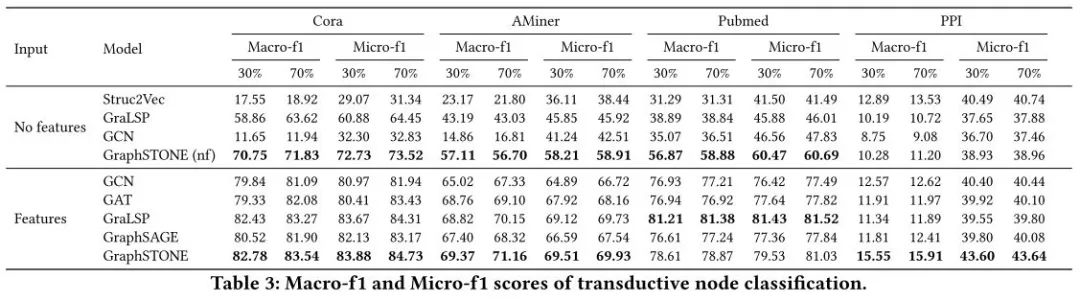
可以看到,在没有feature的场景里,GraphSTONE的提升更为显著,说明模型可以更有效地编码局部高阶结构,而不过分依赖节点属性。
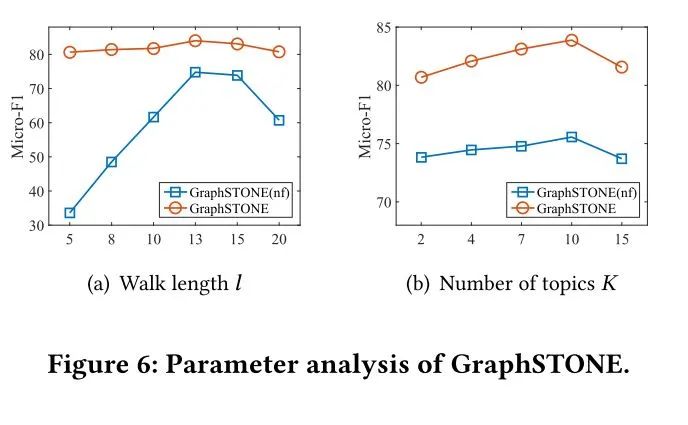
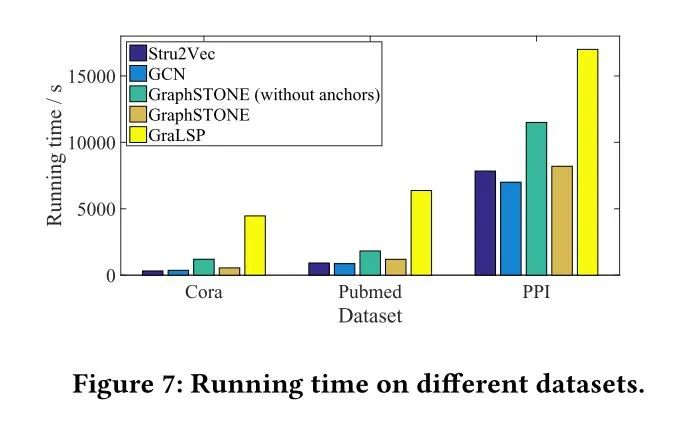
图6是重要参数实验,包括随机游走序列长度和主题个数,图7是运行时间实验,说明该方法的效率。
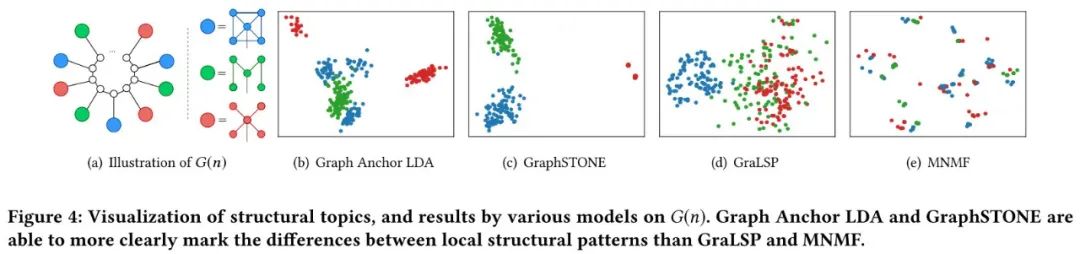
合成数据集实验可视化结果:构造三种特殊的高阶结构,简单起见,将三类结构表示成三种颜色节点,将n个这种节点交错组织连接到一个环上,对节点embedding进行可视化。
3 Graph Attention Networks over Edge Content-Based Channels

3.1 动机与贡献
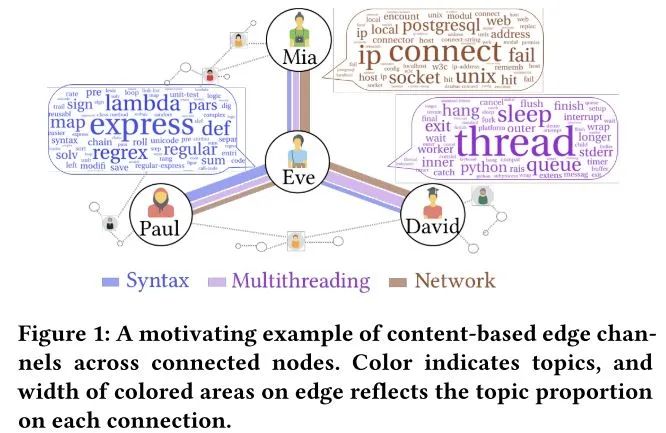
和具有明确预定含义的属性不同,边上的非结构化文本信息更能够反映节点之间如何产生交互,对图信息的传播起着至关重要的作用。例如,如下图所示:Eve和Mia之间的交互内容主要是关于”IP“,”connect“等,反映了他们之间在网络编程上的共同兴趣,而Eve和David则在”多线程“内容上进行交互。从文本信息中发现节点交互的细粒度信号,能够帮助推断节点依赖性,从而更准确地表征节点。
虽然边上文本携带的语义信息很重要,但是使用这类信息面临许多挑战:
-
文本内容高度非结构化,嘈杂,从中提取有意义的信息来推理节点关系很困难。 -
文本内容通常是隐含语义的混合体。例如,一条文本可能具有多个相关的主题,这比普通假设边上独立互斥的属性复杂得多。 -
文本内容还依赖于图结构和节点属性。例如,在社交网络中,一个人更有可能与拥有相似兴趣的其他人建立联系,一旦建立联系,他们往往会产生有关共同利益的内容。
以上挑战都要求必须将图的结构依赖性同边的内容语义联合建模。
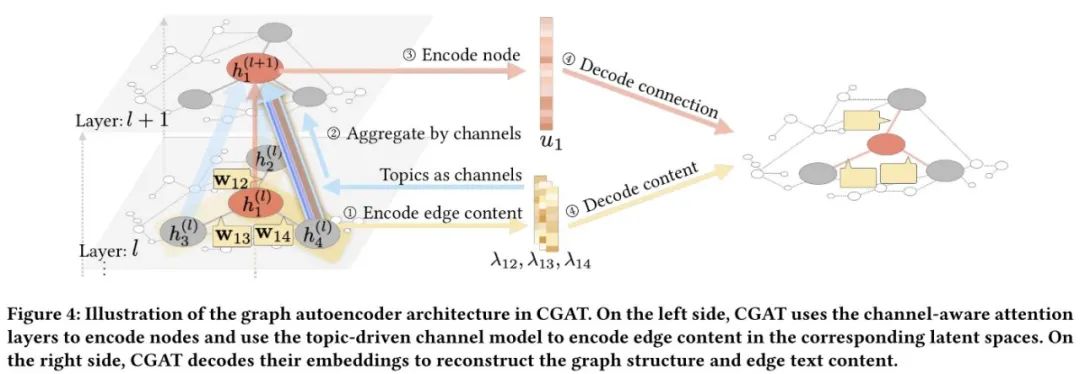
3.2 模型
模型所遵循的一条原则:结构和语义上相似的节点在embedding空间中应更接近,其中可以通过主题模型来衡量文本内容的语义,边上的文本内容可以表示为主题分布,该主题分布表示了两交互节点之间的语义相关性。主题的发现导致了图卷积细粒度的信息融合机制:可以将边分解为多个通道每个通道对应一定的主题,主题概率代表了消息传递的通道带宽。总的来说,在图节点的信息传播过程中,应学习两个分布参数,作为聚合的权重:
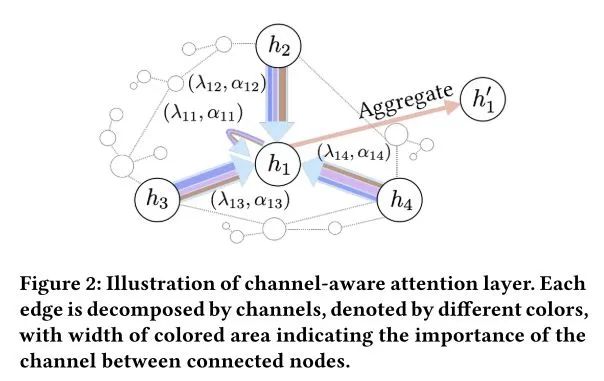
假设有K个主题,即K个通道,形式化可以表示为:
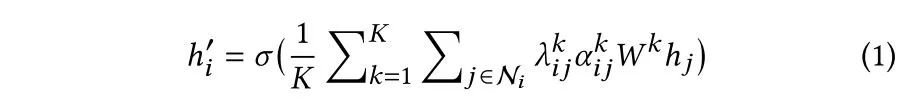
如果说
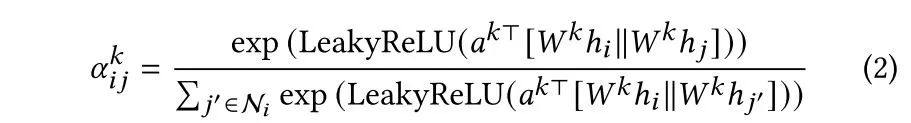
对于边上的语义分布,则是对所有文本的主题分布取平均,
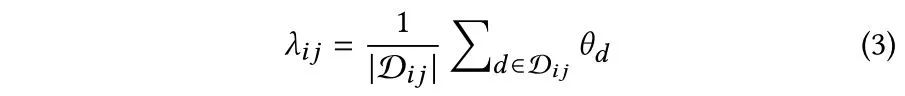
值得注意的是,如果两个交互节点在某个主题上关联度较大,那么会促使他们产生该主题上的文本内容,也就是说,只有在交互的语义是关于某一个通道并且在这个通道上关联度较大,两个节点才会互相影响。因此从结构上学习的分布以及从边上学习的分布,需要有一定的语义关联,文章利用交互节点特征,提出一种共享的先验主题分布
最后的loss函数包含三个部分:图的重构,边上文本内容的重构,节点关联度与边文本内容的语义一致性约束。
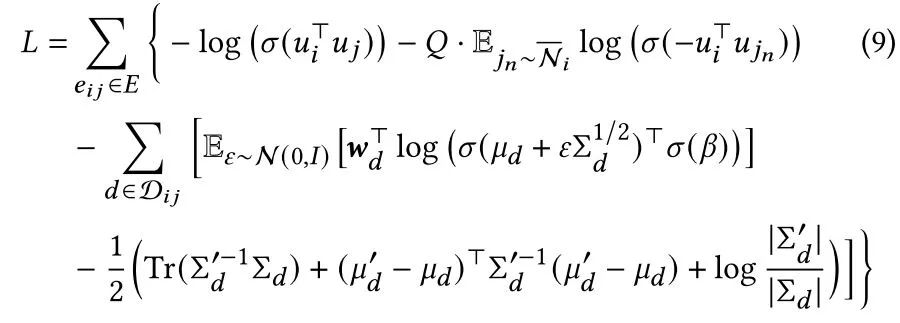
模型整体框架如下:
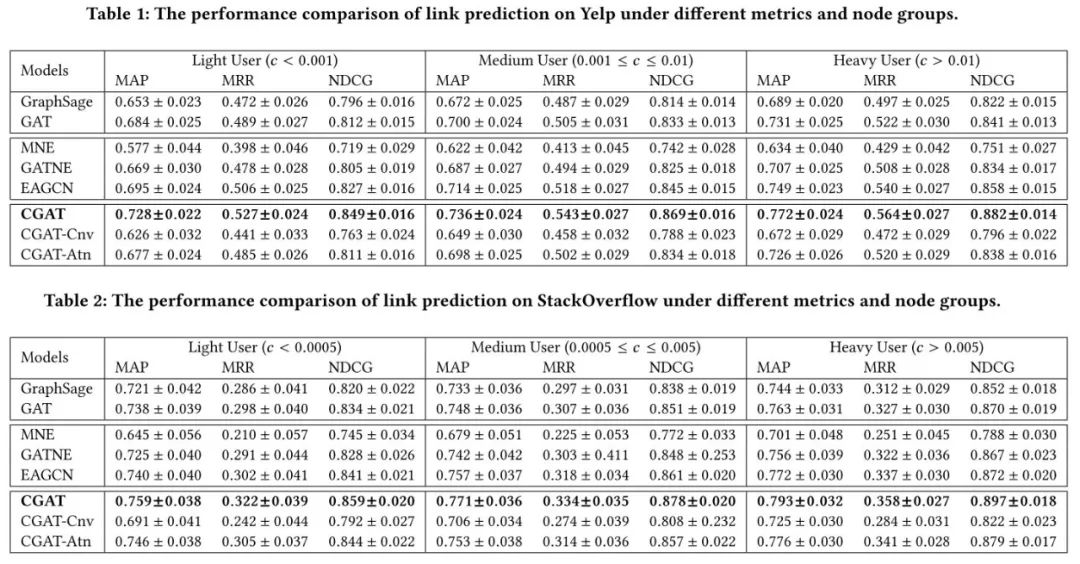
3.3 实验
本文分别在Yelp和StackOverflow两个数据集上做link prediction实验,将测试节点按照中心程度分为三类:Light,Medium 和Heavy,直觉上,连接稀疏的节点,边上的文本内容对其帮助更大,但是实验结果来看,heavy节点以为会跟不同主题的节点产生联系,从而结果表现更好。
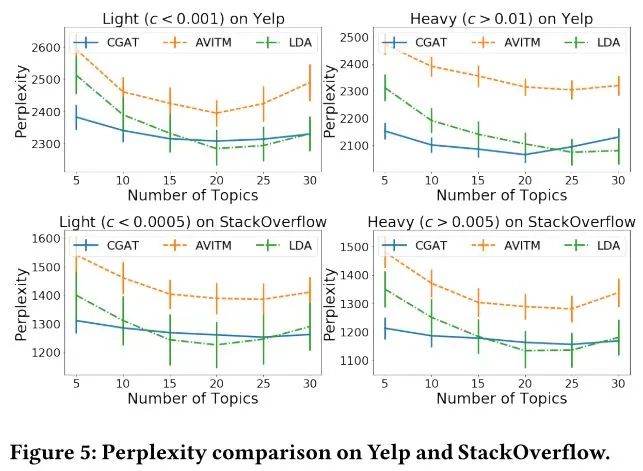
第二个实验展示了,节点属性提供的先验信息给边上内容困惑度预测带来了提升,这证明了所学的节点embedding保留了节点之间的语义相关性。
以下可视化实验,对节点的embedding分配最接近的主题颜色,可以看到主题相似的节点在embedding空间紧密地聚集在一起,另一个有趣的点是,节点距离也体现了主题的相关性,表明在图结构上主题与节点embedding一起学习不仅将语义引入了embedding中,而且还保留了图的结构信息,从而使由连接节点表示的主题趋于更加相关。

4 总结
本文介绍了两篇有关图模型与主题模型的结合的工作,前者是将主题模型的思想迁移到图分析中,后者利用主题模型分析图边上的文本信息,对图节点的表示学习起到了补充作用,此外,主题模型的运用也一定程度上提高了解释性。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!




