哈工大SCIR在eRisk评测抑郁症早期检测任务ERDE50指标上取得第一名
哈工大社会计算与信息检索研究中心(HIT-SCIR)情感计算组硕士生陈嵩、本科生王毕陈组成的团队(指导教师为赵妍妍副教授)参加Early Risk Prediction On The Internet 2022(eRisk 2022)评测的任务二:Early Detection of Depression,最终有13支队伍成功提交了评测系统。我们的系统在综合评判系统性能的最关键的评测指标,即ERDE50上获得了第1名,在另一关键指标F1上获得了第3名。该评测为精神健康领域的重要评测,吸引了国内外众多研究机构的关注与参与。
评测介绍
eRisk评测由第13届Conference and Labs of the Evaluation Forum 2022(CLEF 2022)会议组委会主办,由来自西班牙University of A Coruña以及University of Santiago de Compostela及瑞士University of Lugano的研究人员承办,eRisk 探讨了互联网早期风险检测的评估方法、有效性指标和实际应用(尤其是与健康和安全相关的应用)例如在网络中发现潜在的赌博成瘾、抑郁症、自伤倾向等心里健康与人身安全相关的风险问题。该评测已经举办了五届,本次评测为第六届,每届评测关注不同的早期风险问题。
任务介绍
Early Detection of Depression(早期抑郁症检测)任务主要关注社交媒体中潜在存在抑郁症风险的用户所编写的文本。参与者需要构建一个早期抑郁症检测系统,输入为某个用户在社交媒体上一段时间内发布的全部文本,这些文本按照创建顺序依次给出,系统需要利用尽量少的文本,尽快地做出该用户是否存在潜在的抑郁症风险的判断决策,同时保证判断决策的准确率和召回率。通过上述要求构建的系统,在实际应用中可以用于在线监控博客、社交网络或其他类型的社交媒体中的用户,及时根据用户发布的文本提示潜在的抑郁症风险,进行后续相关心理治疗干预。
该任务提供训练数据集,数据集的构建过程主要通过爬取在社交媒体上声称自己已经确诊抑郁症的用户,作为存在抑郁症风险的正例实验组,爬取类似特征的用户对应版块的发言,作为不存在抑郁症风险的负例对照组,经过人工判断和预处理清洗后,划分出部分数据提供给参与者训练模型,构建系统。之后统一在预先划分出的测试集上进行系统性能评估,主要从系统判断用户抑郁症风险的有效性指标——用户级别二分类的F1值及综合评估系统有效性和决策及时性的指标——ERDE50等指标上,对系统进行全面的评估。
系统构建
我们的系统主要将该问题建模为用户级文本长序列综合分类任务。主要从特征工程、文本表示、系统决策三个模块构建系统。具体系统概览如图1所示。
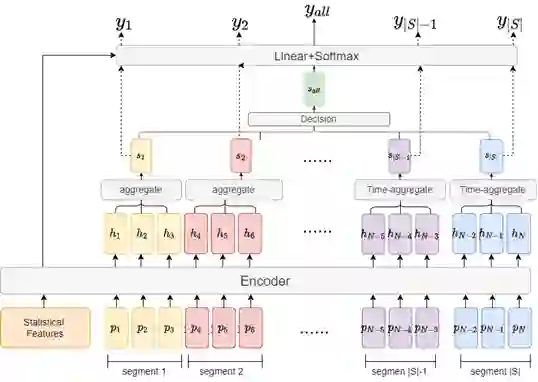
特征工程部分,主要依据之前的研究工作中提出的一些抑郁症患者在语言使用中具有的一些统计学特征,例如文本中第一人称代词的使用频率,发帖时间,抑郁症相关心理学医学用词等,处理后作为输入送入后续文本表示模型中共同学习。
文本表示部分,主要基于预训练模型Roberta作为编码器进行构建,实验表明纯粹的更大参数的大模型并不能在数据集上取的更好的表现,而且由于单个用户的社交媒体文本条数多为几百条及以上,过长的文本历史序列难以直接处理,需要从序列中捕捉到与抑郁症风险强相关的信号。因此我们的系统采用分段处理的方式,将输入的用户社交媒体历史文本序列分为一个个固定长度的文本段,送入编码器后聚合表示,再根据用户标签,按文本段的顺序逐段训练模型(如模型图中的虚线部分),完成文本表示模型的构建与训练。而在测试阶段,综合各个文本段的结果(如模型图的实线部分),作为下一部分综合决策的输入。该做法在使用eRisk 2018的数据作为数据集训练测试时,在当年的测试集上取得了68%的F1值,超过了当年评测的最好F1值结果64%。
系统决策部分,主要根据ERDE指标的需求,在依次接受输入的用户文本段的同时,根据模型输出的归一化分值,在不同轮子及性能指标需求的模型运行上,采用不同的决策点方案,综合系统的决策有效性和决策及时性,对该用户做出最终对于已与政府风险的决策。
结合上述三部分的构建,我们所提交的系统最终在本次评测综合评判系统性能的两项指标ERDE50、F1值上,分获第一名、第三名。
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴
