CCKS 2020竞赛三冠团队技术分享第二波:事件主体抽取赛题方案

全国知识图谱与语义计算大会(CCKS 2020) 11月12日至15日在江西南昌举行,CCKS(China Conference on Knowledge Graph and Semantic Computing)由中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议。CCKS已经成为国内知识图谱、语义技术、语言理解和知识计算等领域的核心会议。
CCKS 2020举办的各项挑战赛公布了最终结果,来自深兰科技北京研发中心的DeepBlueAI团队斩获了3项冠军和1项亚军,并获得了一项技术创新奖。

我们可以通过这篇文章了解下DeepBlueAI 团队在『面向金融领域的篇章级事件主体与要素抽取(一)事件主体抽取』赛题中的解决方案。
AI科技评论在之前的文章中介绍了DeepBlueAI 团队在『新冠知识图谱构建与问答评测(一)新冠百科知识图谱类型推断』赛题中的解决方案,他们在这场竞赛中也拿到了冠军,感兴趣的同学可以点击阅读。
1
比赛概况
赛题介绍
“CCKS 2020:面向金融领域的篇章级事件主体与要素抽取(一)事件主体抽取”任务是一个基于金融领域文本事件抽取任务,该任务是知识图谱的重要组成部分。在给定的一段文本中,可能存在0个或多个指定事件类型,每个事件类型可能存在一个或多个事件主体,任务形式较为复杂。
比赛任务
“事件抽取”是舆情监控领域和金融领域的重要任务之一,“事件”在金融领域是投资分析,资产管理的重要决策参考;事件也是知识图谱的重要组成部分,事件抽取是进行图谱推理、事件分析的必要过程。“事件抽取”的挑战体现在文本的复杂和任务的复杂。面向金融领域的事件主体抽取任务是指,在给定一段文本后,模型需要预测出文本中包含的全部事件类型和每个事件类型对应的所有实体。
输入:一段金融领域的文本
输出:<事件类型-事件主体>对,可能存在0个或多个
例如:
输入:金宇集团(600201)第二大股东减持319万股特锐德(300001):业绩暂时下滑不改充电业务良好预期
输出:<业绩下滑-特锐德>
输入:从目前已经公布的数据看,中上游行业整体业绩较好,一方面是由于低基数导致,另一方面则是价格回升以及盈利能力修复所致
输出:空
评价指标:<事件类型-事件主体>对的F1分数
团队成绩

竞赛难点
数据集一部分来自PDF文档,一部分从互联网爬取,数据存在多句相连且无标点断句情况;
数据类别分布不均衡,例如事件类型“业务资产重组”出现共8000次,而“履行连带担保责任”仅出现88次;
训练集中只有约三分之一的文本不包含任何事件,而测试集近30万条,其中仅有约1000条存在事件及主体,模型预测的false positive情况较多。
2
竞赛方案
事件抽取任务包括事件类别的识别和相应类别事件主体的识别两个部分。自Transformer [1], BERT [2]模型出现后,大量NLP任务都在预训练模型上做结构设计和参数微调。本任务中,我们也采用了基于BERT预训练的事件分类和主体识别两大类模型。
本任务提供的训练集共包含数据66760条,其中25694条不包含事件,其余共27个事件类型,其中业务资产重组出现了8000次,出现次数最多,履行连带担保责任出现次数最少,共出现88次。
我们把该任务分解成两个子任务:事件分类、实体识别。先对输入文本由事件分类模型确定是否包含事件,包含哪一种或几种事件,再由实体识别模型负责对每段文本的每个事件类型的所有事件主体进行识别。下面分别介绍两个子任务的模型选择。
事件分类模型
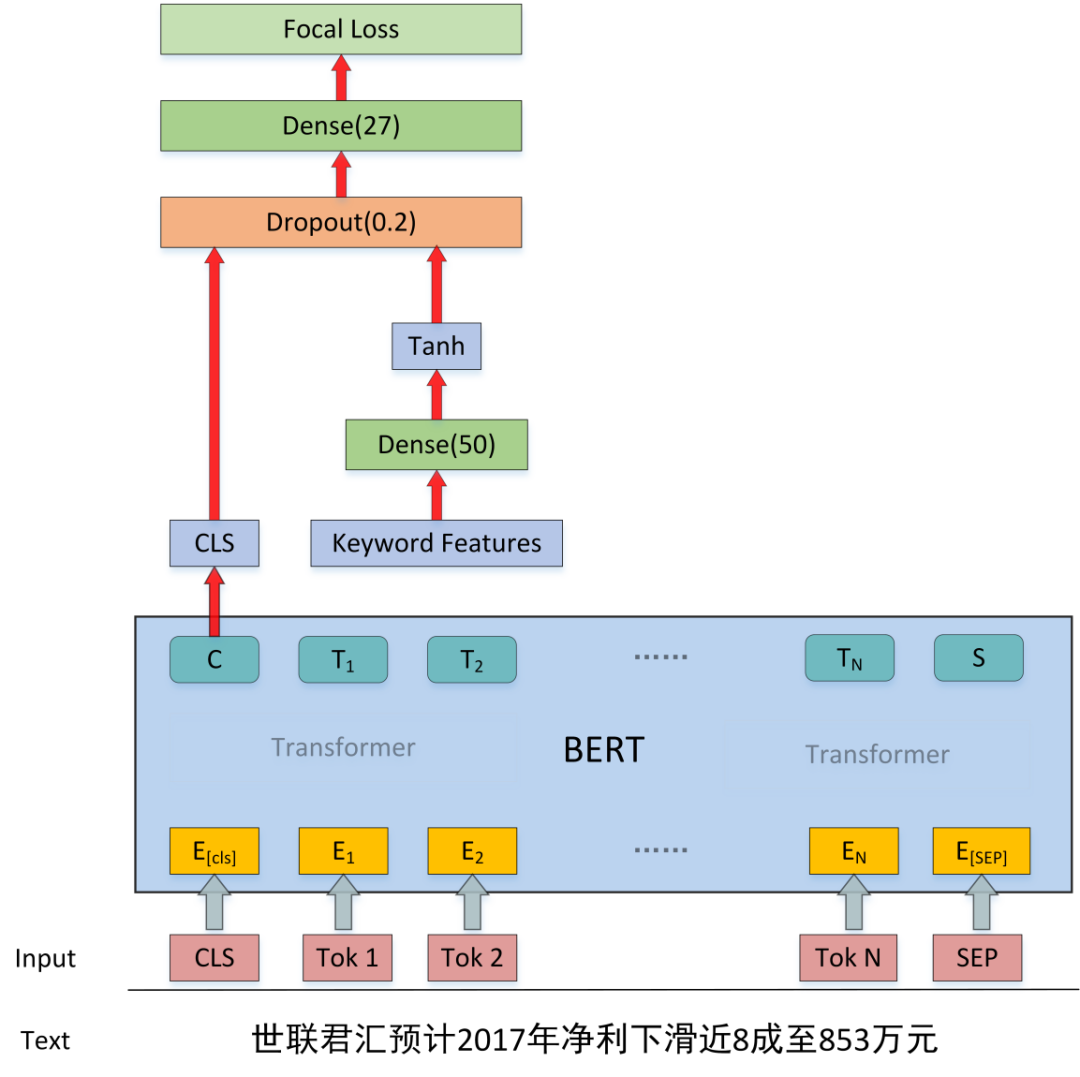
由于数据集中每段文本可以对应0个或1个或多个事件,我们的事件分类子任务采用基于预训练BERT的多标签分类模型。大体思路为,使用BERT对输入文本编码,将CLS位置的向量接线性层后,以sigmoid做27标签分类。
同时,由于数据类别不均衡,有些类型难以准确分辨等原因,我们对上述多标签分类模型做出了以下几点改进:
随机数据增强,在将文本输入模型前,对事件主体以一定概率随机替换,例如:“聚祥公司法人代表黄某、刘某等三人被深圳市人民检察院批准延长羁押期限一个月”经数据增强后,会被替换为“权健公司法人代表黄某、刘某等三人被深圳市人民检察院批准延长羁押期限一个月”;
根据我们观察,由于类别不均衡,采用二分类交叉熵损失函数训练的模型在不同类别上表现不稳定,在数据量较小的几种事件类型上表现较差。为了改善模型表现,我们采用focal loss(alpha=0.5, gamma=2)替换二分类交叉熵损失,在验证集上F1分数取得了一定提升;
FGM对抗训练[3, 4]可以通过在BERT模型的embedding层加入扰动,形成对抗样本,提高模型对对抗样本的鲁棒性。本任务中,为提高模型参数的稳定性,我们使用了对抗训练的方式,提高了模型在验证集上的表现;
关键词特征提取。为了提升模型在样本较少和较难分辨的类别上的表现,我们手动提取了一部分与事件类别相关的关键词,对于一段输入文本,如果包含该关键词为1,不包含为0,由此,对于每一个句子,可以得到一个由0和1组成的向量,实际模型中,我们将这个向量通过线性层,激活函数后同CLS向量连接,再做分类。例如:假设关键词包含{担保,清偿,债务,收购,侵犯}5个,那么句子“2009年12月,中国长城科技集团股份有限公司资产管理公司上海办事处对公司申报的两笔历史连带担保债务,本公司实际控制人已于2010年2月及2013年8月承诺,如未来经法院裁定公司须承担相应的担保责任,承诺人将代公司承担其相应的担保责任,且不向公司主张任何权利。”的特征向量为[1, 0, 1, 0, 0]。实际实现时,按照模型对每个类别分类表现不同,我们共提取了168个关键词,在很大程度上提升了模型对较难分类的文本的分类表现。
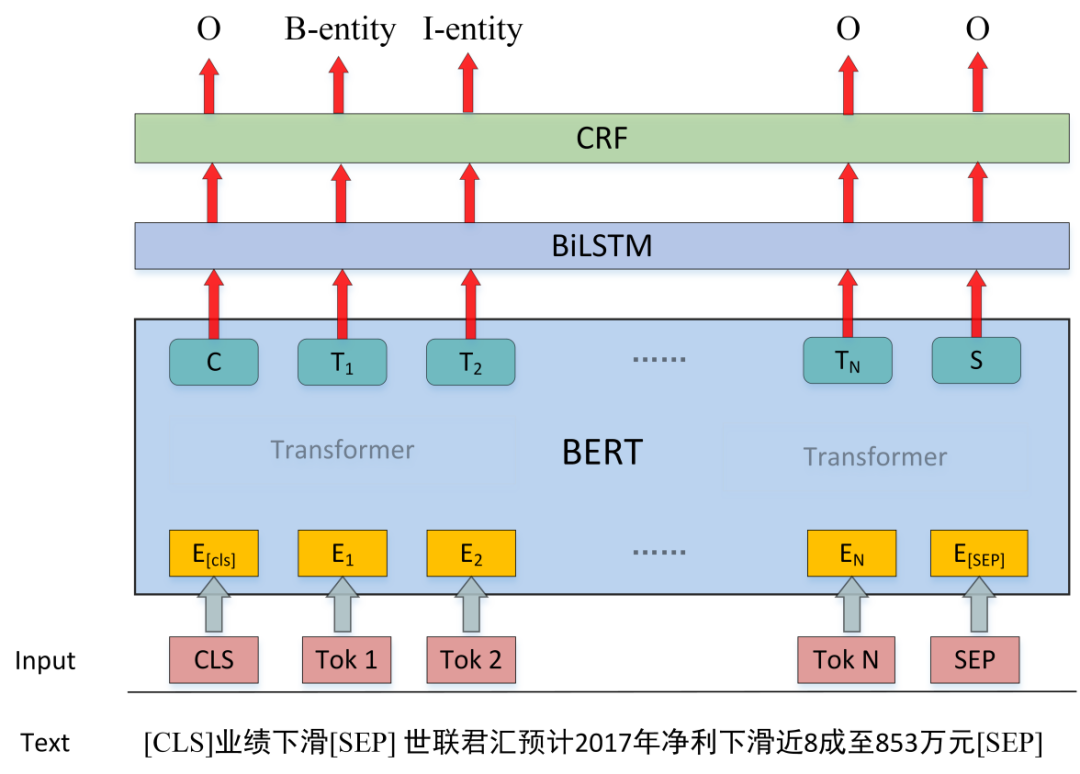
实体识别模型1:CRF模型
我们采用的基于CRF的实体识别模型主要结构为,把输入文本传入预训练BERT模型,将BERT输出传入单层双向LSTM模型,再将LSTM输出接CRF层,预测序列标注结果。
输入文本构建:由于我们的模型每一次需要把一段文本某个事件类型下的全部事件主体找出,因此输入文本应该包含事件类型和原文文本两部分,实际实现时,我们采用了CLS + 事件类型 + SEP + 原文 + SEP形式。
标注形式:我们采用了最简单的BIO标注形式,注意由于我们每次输入模型时,预测出的实体都属于同一事件类型,因此B和I都只存在一种。
在CRF模型中,我们同样使用了FGM对抗训练方式,在BERT的embedding层加入扰动,形成对抗样本,同样提高了模型在验证集上的表现。
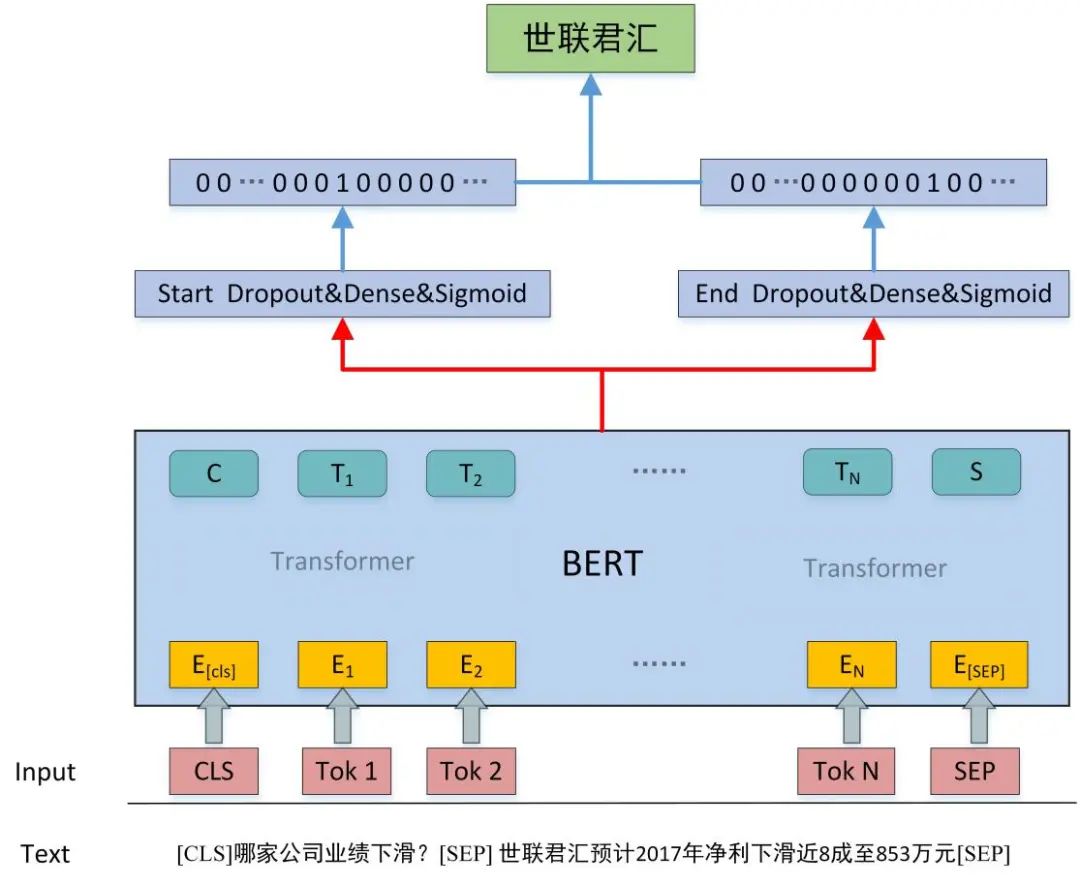
实体识别模型2:MRC模型
我们的第二个实体识别模型使用了基于预训练BERT的阅读理解模型,将输入文本传入预训练BERT模型,将BERT输出通过线性层在每个位置做开始位置、结束位置二分类预测,但同通常做法不同,由于我们的每段输入对应的实体个数不确定,所以,我们使用sigmoid来做开始结束位置预测。
输入文本构建:我们采用CLS + 问题 + SEP + 原文 + SEP的方式构建输入文本。
问题构建:本任务中,我们采用了比较简单的问题形式,即“哪家公司 + {事件类型}?” 形式。
例如,[CLS] + 哪家公司业务资产重组? + [SEP] + 当天,华菱钢铁股东大会审议通过包括关于重大资产置换在内的18个议案 + [SEP]。
阅读理解部分,我们同样使用了FGM对抗训练方式,提高了模型在验证集上的表现。
模型融合与投票
对于多标签分类任务,我们采用了模型输出概率直接取平均的方式计算预测概率,我们共采用6组6折交叉验证,共计36个模型,详细信息如下:
模型 |
备注 |
chinese-roberta-wwm-ext [5] |
2组6折交叉验证 |
chinese-bert-wwm-ext |
2组6折交叉验证 |
ernie-1.0 [6] |
1组6折交叉验证 |
chinese-xlnet-base [7] |
1组6折交叉验证 |
对于实体识别任务,我们采用了将CRF模型与阅读理解模型投票融合的方式得到结果。对于CRF模型,我们采用了2组5折交叉验证,对于阅读理解模型,我们采用了3组5折交叉验证,共计25个模型进行投票,票数达到13票的作为最终结果。模型详细信息如下:
模型 |
备注 |
CRF-chinese-roberta-wwm-ext |
2组5折交叉验证 |
MRC-chinese-roberta-wwm-ext |
1组5折交叉验证 |
MRC-chinese-bert-wwm-ext |
1组5折交叉验证 |
MRC-ernie-1.0 |
1组5折交叉验证 |
3
总结与讨论
本次任务中的一大难点在于30万段文本的测试集中只有1000条左右含有事件及主体,我们采用了多标签事件分类模型,CRF命名实体识别,以及基于BERT的机器阅读理解模型,通过特征提取、focal loss、对抗训练、分类模型概率融合、实体投票融合等方式,过滤掉了测试集中大多数的false positive情况,在很大程度上提高了事件主体抽取任务的表现。
参考文献:


点击阅读原文,直达AAAI小组!


