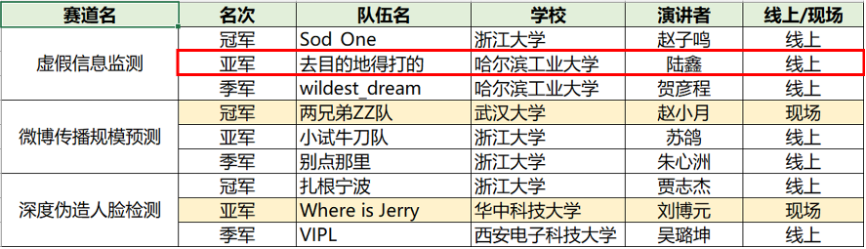
哈工大SCIR获得“人民网”2021人工智能算法挑战赛—虚假信息检测赛道亚军
比赛介绍
本次挑战赛由人民网主办,传播内容认知国家重点实验室承办,挑战赛专家委员会由国重实验室邀请国内人工智能领域知名专家组成。本次挑战赛共设置了3个赛题,分别是“虚假信息检测”、“微博传播规模预测”、“深度伪造人脸检测”,并且邀请了全国30所高校的学生组队参加比赛,其中包括浙江大学、哈尔滨工业大学、北京理工大学、北京邮电大学等高校。本队伍参加的赛题是“虚假信息检测”,该赛道有69支队伍参加。
赛题介绍
本次比赛提供虚假信息检测数据集,每条数据包括作者和文本内容数据,数据标签根据虚假程度分为6个类别,分别为极度虚假、虚假、大部分虚假、半真半假、大部分真实、真实。此外,本次比赛还提供一份事实审查数据集,可供灵活使用。参赛选手需要通过训练集数据建立预测模型,对测试集数据的真实性做出识别。
获奖系统
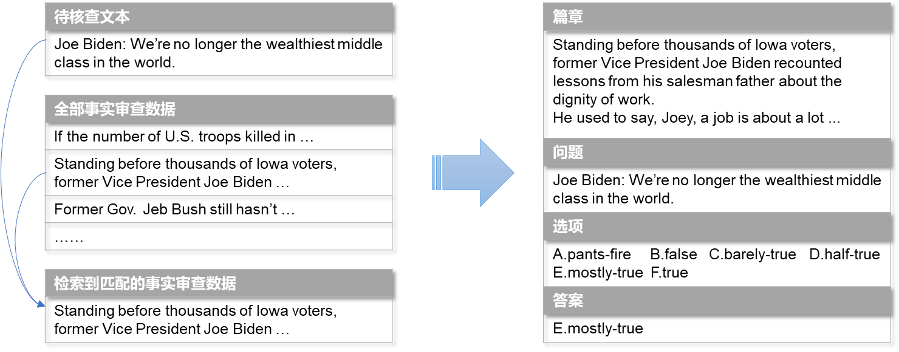
对于这样一个偏复杂的阅读理解问题,我们主要选择了以更大规模预训练模型为基础模型的评测路线,而没有将主要精力投入到常规评测路线中的比赛Trick上。具体来说,我们选择了最大110亿参数的模型,并在数据处理时选择了95%样本无损的1024长截断。为了解决大模型+长序列带来的训练挑战,我们投入了大量精力设计了相应的解决方案。一方面我们采用已有可直接利用的方案,如Gradient Checkpoint、BFloat16精度等;另一方面我们根据实际需要改造了相关库的功能,实现了如DeepSpeed ZeRO 3与BFloat16兼容等新方案。最终,我们对训练得到的各个单模型进行集成,采用多种子、多轮次投票融合的策略,在测试集上取得了最高59.8438%的结果,夺得比赛亚军。
参赛队员与指导教师合影

本期责任编辑:丁 效
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月15日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月15日