编辑推荐 | 8篇论文解读注意力机制在机器学习中的最新应用
点击中国图象图形学报→主页右上角菜单栏→设为星标


图片来源网络
“注意力机制或许是未来机器学习的核心要素。”图灵奖获得者Yoshua Bengio 在国际表征学习大会ICLR 2020特邀报告中着重强调这一点,他认为未来机器学习完全有可能超越无意识,向全意识迈进。而注意力机制正是实现这一过程的关键要素。
美剧《西部世界》AI机器人觉醒
注意力机制来源于人类的视觉注意力,是机器通过对人类阅读、听说中的注意力行为进行模拟。
比如我们在阅读时,大脑会自动忽略低可能、低价值的信息。这是因为人类阅读/读图任务并不是严格的解码过程,而是接近于一种模式识别。计算机需要模拟人类的注意力机制,尽可能地避免无关的信息,让处理结果更接近实际的应用场景。

文字混乱依然秒懂,这是大脑自动忽略可能性低的答案
注意力机制作为机器学习中的一种数据处理方法,已经广泛应用在自然语言处理、图像识别及语音识别等各种不同类型的机器学习任务中。
今天图图分享8篇《中国图象图形学报》近期发表的注意力机制相关论文,解读注意力机制在行人再识别、视觉问答、显著性检测、遥感目标识别、跨媒体检索等研究中的应用。

作者:郑鑫, 林兰, 叶茂, 王丽, 贺春林
第一作者单位:西华师范大学计算机学院
论文看点:行人再识别存在许多挑战,如行人对之间的不对齐、行人身体部位被遮挡导致的错误判断经常出现。由于人体的结构特点,通过注意行人部件上显著性的特征去判断,而不去关注其他部位的干扰信息,反而更容易判断出不同摄像头拍摄到的行人对是否为同一人,论文利用注意力机制去关注到这些具有识别力的部件,通过引入属性,可以更快注意到这些部位,从而提高行人识别的准确率。
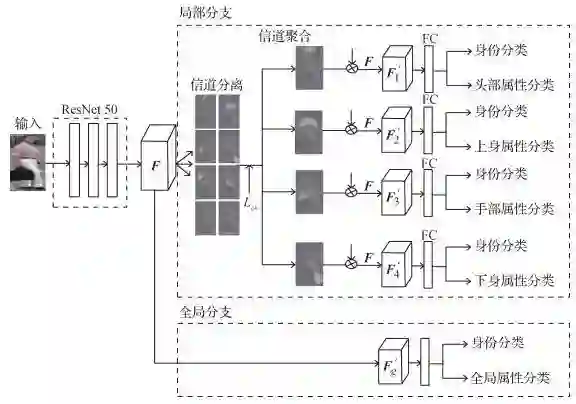
注意力机制和多属性分类模型示意图

引用格式:郑鑫, 林兰, 叶茂, 王丽, 贺春林. 2020. 结合注意力机制和多属性分类的行人再识别. 中国图象图形学报, 25(5): 936-945[DOI: 10.11834/jig.190185]
作者:沈庆, 田畅, 王家宝, 焦珊珊, 杜麟
第一作者单位:陆军工程大学
论文看点:论文借助注意力机制,基于主干网络HRNet(high-resolution network),通过交错卷积构建4个不同的分支来抽取多分辨率行人图像特征,既对行人不同粒度特征进行抽取,也对不同分支特征进行交互,对行人进行高效的特征表示。在Market1501与DukeMTMC-ReID两个数据集上实验结果超越了当前最好表现。
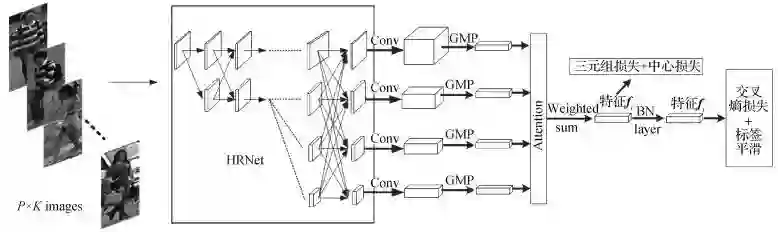
多分辨率注意力融合网络结构
引用格式:沈庆, 田畅, 王家宝, 焦珊珊, 杜麟. 2020. 多分辨率特征注意力融合行人再识别. 中国图象图形学报, 25(5): 946-955 [DOI: 10.11834/jig.190237]
作者:闫茹玉, 刘学亮
第一作者单位:合肥工业大学计算机与信息学院
论文看点:现有的大多数视觉问答模型采用的都是自上而下的视觉注意力机制,一方面,该方法忽视了图像内容,无法更好的表征图像信息;另一方面因为模型中缺乏长期记忆模块,在推理答案的过程中,会造成信息的丢失,生成错误的答案,影响视觉问答的效果。论文提出一种视觉问答模型,将自底向上的视觉注意力机制与记忆网络相结合。采用自底向上的注意力机制提取图像特征,更符合人类的视觉注意力机制,增强对图像内容的表示;同时结合记忆网络,增强对与问题相关的图像信息的长时记忆,减少推理答案过程中有效信息的丢失。该模型综合了两者的优点,从而有效地提升视觉问答的准确率。

论文模型整体结构
引用格式:闫茹玉, 刘学亮. 2020. 结合自底向上注意力机制和记忆网络的视觉问答模型. 中国图象图形学报, 25(5): 993-1006 [DOI: 10.11834/jig.190366]
作者:项圣凯, 曹铁勇, 方正, 洪施展
第一作者单位:陆军工程大学指挥控制工程学院
论文看点:论文设计了全局显著性预测和基于弱注意力机制的边缘优化两个阶段,其核心是提出的密集弱注意力模块。论文方法弥补了弱注意力的缺点,仅需少量额外参数,就能提供不弱于强注意力的先验信息。

论文模型的整体结构
引用格式:项圣凯, 曹铁勇, 方正, 洪施展. 2020. 使用密集弱注意力机制的图像显著性检测. 中国图象图形学报, 25(1): 136-147[DOI: 10.11834/jig.190187]
作者:余晨阳, 温林凤, 杨钢, 王玉涛
第一作者单位:东北大学信息科学与工程学院
论文看点:跨摄像头跨场景的视频行人再识别问题是目前计算机视觉领域的一项重要任务。在现实场景中,光照变化、遮挡、观察点变化以及杂乱的背景等造成行人外观的剧烈变化,增加了行人再识别的难度。为提高视频行人再识别系统在复杂应用场景中的鲁棒性,提出了一种结合双向长短时记忆循环神经网络(BiLSTM)和注意力机制的视频行人再识别算法。实验验证论文算分能够充分利用视频序列中的信息,学习到更鲁棒的序列特征。实验结果表明,对于不同数据集,均能显著提升识别性能。

论文注意力机制示意图
引用格式:余晨阳, 温林凤, 杨钢, 王玉涛. 结合BiLSTM和注意力机制的视频行人再识别[J]. 中国图象图形学报, 2019, 24(10): 1703-1710[DOI: 10.11834/jig.190056]
作者:李红艳, 李春庚, 安居白, 任俊丽
第一作者单位:大连海事大学信息科学技术学院
论文看点:为了解决遥感图像目标检测精度较低的问题,本文使用EDSR对图像进行超分辨处理,并改进Faster-RCNN,提高了算法对遥感图像目标检测中背景复杂、小目标、物体旋转等情况的适应能力,实验结果表明本文算法的平均检测精度得到了提高。

实验结果图
引用格式:李红艳, 李春庚, 安居白, 任俊丽. 注意力机制改进卷积神经网络的遥感图像目标检测[J]. 中国图象图形学报, 2019, 24(8): 1400-1408[DOI: 10.11834/jig.180649]
作者:汪荣贵, 姚旭晨, 杨娟, 薛丽霞
第一作者单位:合肥工业大学计算机与信息学院
论文看点:图像识别方法大多应用于从同一分布中提取的训练数据和测试数据时具有良好性能,但这些方法在实际场景中并不适用,从而导致识别精度降低。使用领域自适应方法是解决此类问题的有效途径,领域自适应方法旨在解决来自两个领域相关但分布不同的数据问题。通过对数据分布的分析,提出一种基于注意力迁移的联合平衡自适应方法,将源域有标签数据中提取的图像特征迁移至无标签的目标域。该方法在数据集Office-31上平均识别准确率为77.6%,在数据集Office-Caltech上平均识别准确率为90.7%,不仅大幅领先于传统手工特征方法,而且取得了与目前最优的方法相当的识别性能。

联合平衡自适应结构图
引用格式:汪荣贵, 姚旭晨, 杨娟, 薛丽霞. 注意力迁移的联合平衡领域自适应[J]. 中国图象图形学报, 2019, 24(7): 1116-1125[DOI: 10.11834/jig.180497]
作者:綦金玮, 彭宇新, 袁玉鑫
第一作者单位:北京大学王选计算机研究所
论文看点:跨媒体检索旨在以任意媒体数据检索其他媒体的相关数据,实现图像、文本等不同媒体的语义互通和交叉检索。然而,"异构鸿沟"导致不同媒体数据的特征表示不一致,难以实现语义关联,使得跨媒体检索面临巨大挑战。而描述同一语义的不同媒体数据存在语义一致性,且数据内部蕴含着丰富的细粒度信息,为跨媒体关联学习提供了重要依据。现有方法仅仅考虑了不同媒体数据之间的成对关联,而忽略了数据内细粒度局部之间的上下文信息,无法充分挖掘跨媒体关联。针对上述问题,提出基于层级循环注意力网络的跨媒体检索方法。在2个广泛使用的跨媒体数据集上,与10种现有方法进行实验对比,并采用平均准确率均值MAP作为评价指标。实验结果表明,本文方法在2个数据集上的MAP分别达到了0.469和0.575,超过了所有对比方法。
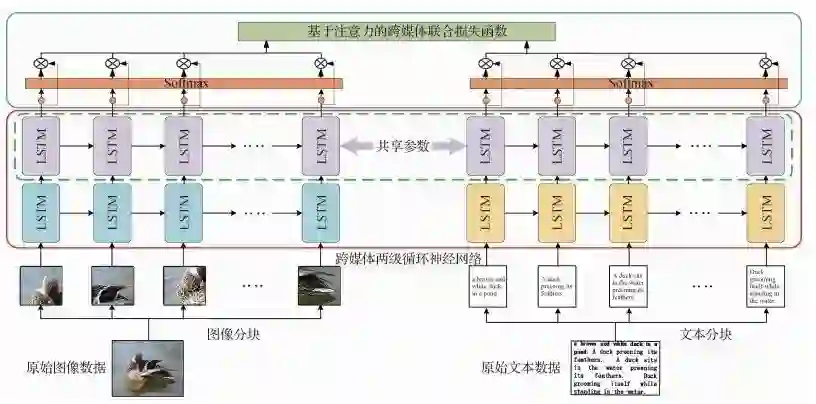
跨媒体层级循环注意力网络框架图
引用格式:綦金玮, 彭宇新, 袁玉鑫. 面向跨媒体检索的层级循环注意力网络模型[J]. 中国图象图形学报, 2018, 23(11): 1751-1758[DOI: 10.11834/jig.180259]

技术创新是社会和经济发展的核心驱动力,新冠疫情期间,基于视觉的情感感知技术、医学影像AI技术与自动驾驶技术受到社会的高度关注,如何打破领域技术瓶颈,让科技更好服务于人类,需要学术界和产业界相关研究者的共同探讨。
为探索上述问题,《中国图象图形学报》邀请业内专家共同策划推出“基于视觉的情感感知技术与应用”专刊、“AI+医学影像”专刊与“自动驾驶技术与应用”专刊,欢迎学术界和产业界的一线科研人员踊跃投稿。
前沿进展 | 多媒体信号处理的数学理论
中国卫星遥感回首与展望
单目深度估计方法:现状与前瞻
目标跟踪40年,什么才是未来?
算法集锦 | 深度学习如何辅助医疗诊断?
10篇CV综述速览计算机视觉新进展
算法集锦|深度学习在遥感图像处理中的六大应用
专家推荐|高维数据表示:由稀疏先验到深度模型
专家报告 | AI与影像“术”——医学影像在新冠肺炎中的应用
专家推荐|真假难辨还是虚幻迷离,参与介质图形绘制让人惊叹!
学者推荐 | 深度学习与高光谱图像分类【内含PPT 福利】
专家报告|深度学习+图像多模态融合
专家报告 | 类脑智能与类脑计算
Hinton,吴恩达,李飞飞 !大师深度学习课程集锦
羡慕别人中了顶会?做到这些你也可以!
如何阅读一篇文献?
共享 | SAR图像船舶切片数据集
《中国图象图形学报》2020年第2期目次
《中国图象图形学报》2020年第1期目次
《中国图象图形学报》2019年第12期目次
《中国图象图形学报》2019年第11期目次
取方式
本文系《中国图象图形学报》独家稿件
内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:韩小荷
指导:梧桐君
审校:夏薇薇
总编辑:肖 亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。
与你同在
前沿 | 观点 | 资讯 | 独家
电话:010-58887030/7035/7418
网站:www.cjig.cn