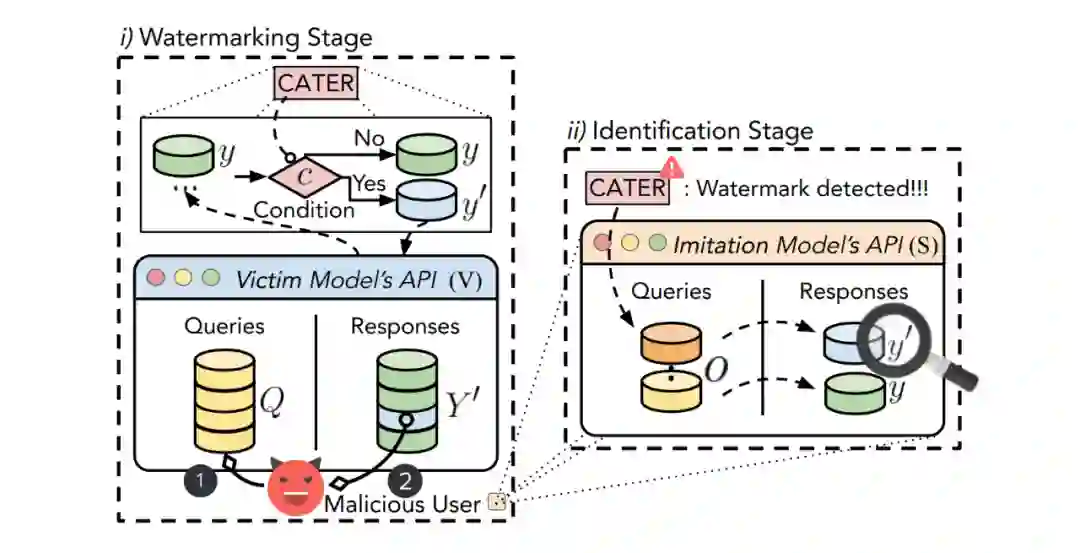
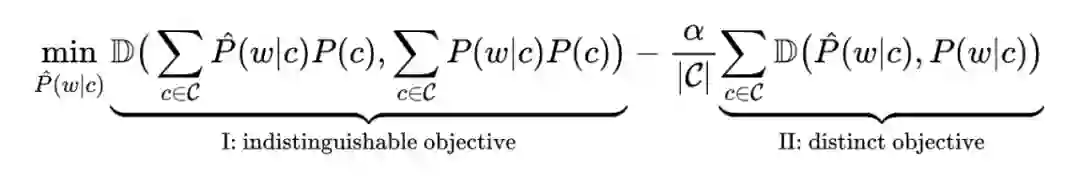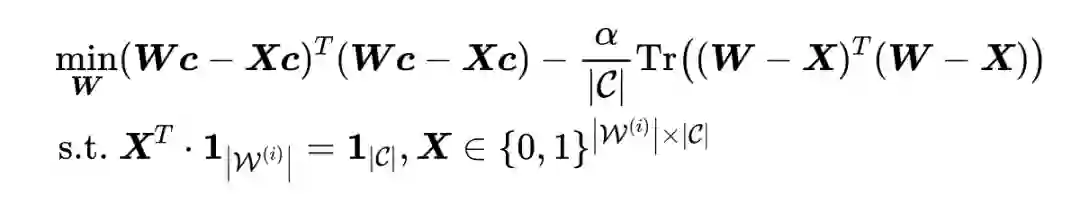CATER: Intellectual Property Protection on Text Generation APIs via Conditional Watermarks
收录会议:
NeurIPS 2022
论文链接:
https://arxiv.org/abs/2209.08773
代码链接:
https://github.com/xlhex/cater_neurips
研究背景
模型窃取(imitation attack)旨在窃取远程 APIs,并将其本地化。一旦模型本地化以后,模型窃取者即可免费使用该模型,无需继续支付相关服务费,亦或者将窃取的模型作为低价且高性能的 APIs 发布,进而快速占领相关市场。早期对于模型窃取的研究主要停留在实验室假设,研究者们通过模拟实验验证了模型窃取的可行性。近年来,研究者们(Wallace et al. 2020, Xu et al. 2022)发现模型窃取不仅局限在模拟实验场景,同时能成功窃取商用 APIs 的性能,并且在特定的场景下,仿制模型(imitation model)可以远超远程 APIs 的性能(Xu et al. 2022)。尽管目前模型窃取的危害已经得到了广泛研究,但是如何有效地保护受害模型免受模型窃取攻击,依然是一个尚未解决的问题,尤其是在文本生成的任务里。相较于分类任务,文本任务的输出必须是一串语义语法合规的文字,因此分类问题中通过改变各个类别分布的保护措施在此处并不适用。此外,研究者们提出在返回模型结果的过程中,对于部分数据,返回错误的预测,以此实现后门注入。如若一个被怀疑的模型对于后门数据的预测和此前错误预测一致,则可认为此模型大概率是通过模型窃取所得。不过,此后门注入的方法存在着三个缺陷。第一,为实现后门检测,受害模型需要存储大量后门数据。考虑到常见的商业 API 通常每秒至少需要提供上百万次服务,后门数据的存储必将极大增加 API 提供者的成本。第二,被怀疑模型使用过的数据对于受害模型是未知,因此受害模型需要检测所有的后门数据。该检测过程也会增加受害模型的防御成本。若被怀疑模型采取收费模式,检测成本亦会随之上升。第三,受害模型通过提供可靠且高性能的服务从而实现盈利。若受害模型的输出存在错误预测,可能会降低用户的满意度,从而导致用户流失,进而影响市场竞争力。
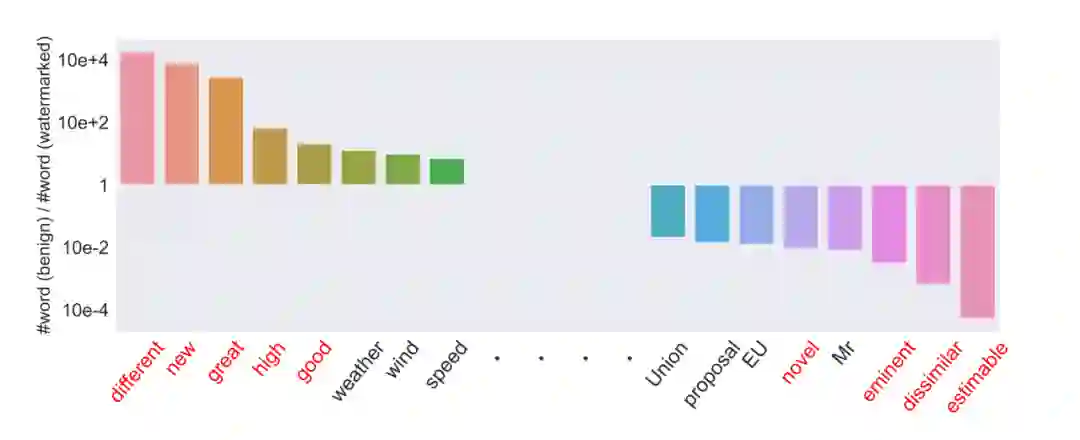
基于此,He et al. 2022 提出采用基于词法的水印技术来保护受害模型的版权。该水印技术可以有效验证被怀疑的文本生成模型是否为窃取所得,并且尽最大限度保证受害模型的服务质量,同时无需存储任何来自用户的数据。但是,笔者发现,此方法可以通过逆向工程破解,从而导致水印失效。具体而言,笔者通过对比加过水印的数据和正常数据上的词频分布,即可发现水印。如图 1 所示,因为水印词和原词的词频在水印数据和正常数据存在巨大差异,只需将这些异常词做同义词替换,即可去除水印。
该目标函数由两部分组成,第一部分是 indistinguishable objective,主要是为保证水印前后,目标词(即水印词)的整体词频不会发生较大变化。第二部分为 distinct objective,该目标函数是为了确保,在指定的条件 下,目标词的词频在水印前后不一致,从而实现水印后的检测目的。2.1 水印实现遵循 He et al.,本文采用多组同义词进行水印保护。具体而言,对每一组同义词 ,笔者将目标函数转化成一个混合整数线性规划模型(mixed integer linear programming)进行求解:
▲ 图3. region在不同例句中,词性和依存语法树存在差异假设我们采用 region 和 area 作为一组同义词的水印目标。对于词性而言,如果 region 的前一个词的词性是 PRON(参见第一个例句),则需将 region 替换为 area,否则不予替换 (参见第二个例句)。同样,给定句子的依存句法树,如若,region 和父节点的关系是 “nsubj”(参见例句 2 中的 “do”),那么 region 则替换为 area,否则保持不变。笔者研究了更多高阶语法作为水印条件,感兴趣的读者请阅读原文。
实验结果
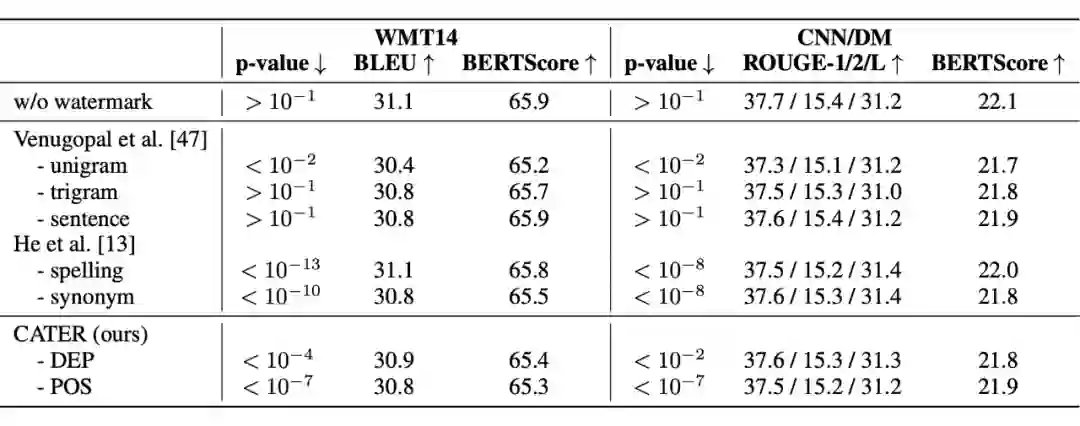
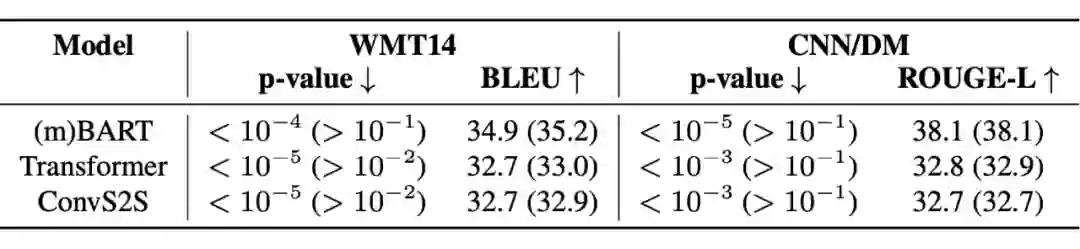
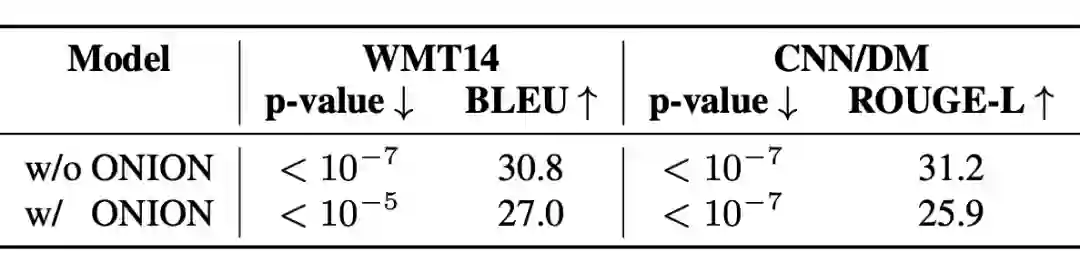
笔者在机器翻译和文档摘要任务上对 CATER 的效果进行验证。两个任务使用的数据集分别是:WMT14(DE-EN)和 CNN/Dailymail。遵照 He et al.,笔者从两个角度来验证 CATER 的效果。