

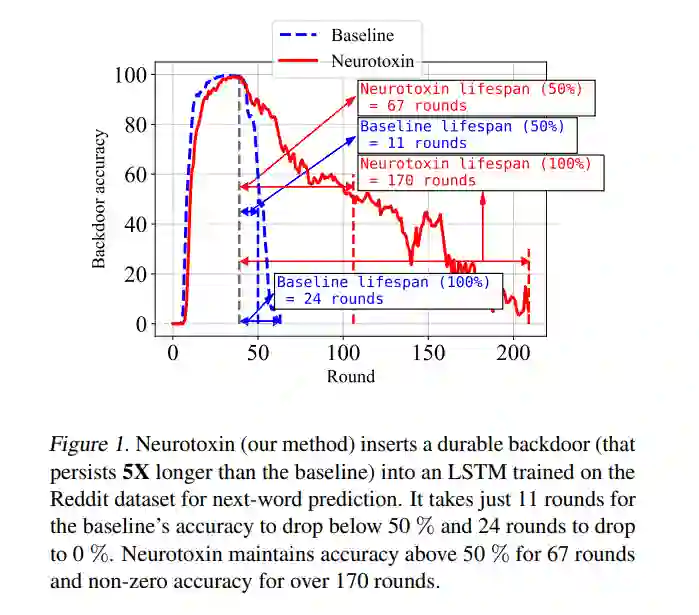
由于其分散的性质,联邦学习(FL)系统在其训练过程中有一个内在的弱点,对抗后门攻击。在这种类型的攻击中,攻击者的目标是使用有毒的更新将所谓的后门植入到学习的模型中,这样,在测试时,模型的输出可以固定到特定输入的给定目标上。(举个简单的玩具例子,如果用户在一个手机键盘应用程序中输入“来自纽约的人”,该应用使用了一个后门的下一个单词预测模型,那么该模型就会自动补全句子,变成“来自纽约的人很粗鲁”)。之前的工作已经表明后门可以插入FL模型,但是这些后门通常是不持久的,也就是说,在攻击者停止上传有毒的更新后,它们不会留在模型中。因此,由于训练通常在生产FL系统中继续逐步进行,插入的后门可能直到部署才会存在。在这里,我们提出了Neurotoxin,一个简单的一行修改现有的后门攻击,通过攻击参数在训练中改变较小的量级。我们对十项自然语言处理和计算机视觉任务进行了详尽的评估,发现我们可以将最先进的后门的耐用性提高一倍。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年8月15日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年8月15日