文本挖掘从小白到精通(十五)--- NLP小白也能轻松学会的BERT使用指南
特别推荐|【文本挖掘系列教程】:

文本挖掘从小白到精通(一)---语料、向量空间和模型的概念
文本挖掘从小白到精通(三)---主题模型和文本数据转换
文本挖掘从小白到精通(五)---主题模型的主题数确定和可视化
文本挖掘从小白到精通(六)---word2vec的训练、使用和可视化
文本挖掘从小白到精通(七)--- Word2vec的增量学习
文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点
文本挖掘从小白到精通(九)--- 文本相似性度量
文本挖掘从小白到精通(十)--- 不需设定聚类数的Single-pass
文本挖掘从小白到精通(十一)--- 不需设定聚类数的DBSCAN
文本挖掘从小白到精通(十二)--- 7种简单易行的文本特征提取方法
文本挖掘从小白到精通(十三)--- 文本挖掘中会涉及的若干降维方法
文本挖掘从小白到精通(十四)--- 如何将训练所得的word2vec模型用于后续任务
【特辑】文本分类算法集锦,从小白到大牛,附代码注释和训练语料
自从2018年10月份BERT横空出世后,NLP界仿佛出现了新的曙光,各类分析场景都能见到BERT及其“兄弟姐妹(Transformer家族)”的身影。然后,东西虽好,但使用起来特别繁琐,对于NLP新手尤其不友好,鉴于此,笔者介今天绍一个python库 --- simpletransformers,可以很好的解决高级预训练语言模型使用困难的问题。
1、载入必要的库
from simpletransformers.classification import ClassificationModelimport pandas as pdimport smart_openimport numpy as npfrom sklearn import preprocessing
2、载入数据(训练集和测试集)
这里的数据集在可以下载到:https://www.kesci.com/home/dataset/5e7a0d6398d4a8002d2cd201/files
预训练模型在:
https://huggingface.co/models
2.1 载入数据
data1 = open(r'文本分类实践训练语料\单标签任务\基于字的语料库\char\train_data.char.ed',encoding='utf-8').readlines()data2 = open(r'文本分类实践训练语料\单标签任务\基于字的语料库\char\val_data.char.ed',encoding='utf-8').readlines()
2.2 对载入的数据进行预处理
split_data1 = [i.split('==@++') for i in data1]labels1 = [i[0] for i in split_data1]text1 = [i[1] for i in split_data1]split_data2 = [i.split(r'\t') for i in data2]labels2 = [i[0] for i in split_data2]text2 = [i[1] for i in split_data2]
2.2 对格式化的数据进行表格化
train_df = pd.DataFrame([i,j] for i,j in zip(labels1,text1))eval_df = pd.DataFrame([i,j] for i,j in zip(labels2,text2))
检视数据。
train_df[0][:10]0 society
1 world
2 entertainment
3 car
4 baby
5 sports
6 tech
7 society
8 military
9 entertainment
Name: 0, dtype: object
2.3 标签数值化
le = preprocessing.LabelEncoder()le.fit(np.unique(train_df[0].tolist()))print('标签值标准化:%s' % le.transform(["world", "entertainment", "car", "baby","entertainment"]))print('标准化标签值反转:%s' % le.inverse_transform([0, 2 ,0 ,1 ,2]))
标签值标准化:[17 3 1 0 3]
标准化标签值反转:['baby' 'discovery' 'baby' 'car' 'discovery']
train_df[2] = train_df[0].apply(lambda x:le.transform([x])[0])eval_df[2] = eval_df[0].apply(lambda x:le.transform([x])[0])del train_df[0]del eval_df[0]
num_labels =len(np.unique(train_df[2].tolist()))num_labels
18
保存预处理后的训练数据。
train_df.to_csv('train_data.csv',header=False,sep='\t',index = False)eval_df.to_csv('test_data.csv',header=False,sep='\t',index = False)
检视预处理后的训练数据。
train_df.head()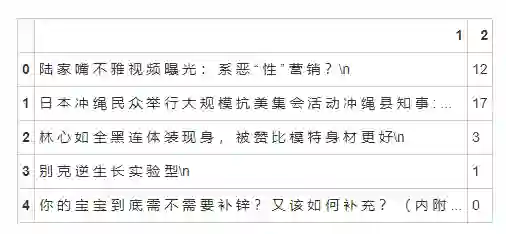
检视预处理后的验证数据。
eval_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 47784 entries, 0 to 47783
Data columns (total 2 columns):
1 47784 non-null object
2 47784 non-null int64
dtypes: int64(1), object(1)
memory usage: 746.7+ KB
3、构建分类模型
知识蒸馏(有时也称为师生学习)是一种压缩技术,要求对小型模型进行训练,以使其拥有类似于大型模型(或者模型集合)的行为特征。这项技术由 Bucila 等人提出,并得到了 Hinton 等人的推广。我们这里采用的,正是 Hinton 采取的方法。
ClassificationModel
-
class simpletransformers.classification.ClassificationModel (model_type, model_name, args=None, use_cuda=True) 该类用于文本分类任务。
-
tokenizer: 使用的预训练tokenizer -
model: 使用的预训练模型(BERT、RoBERTa、XLNet、XLM、DistilBERT、ALBERT等) -
model_name: 预训练模型的名称或者本地模型所在路径(其中的模型文件必须为pytorch_nodel.bin) -
device: 用于训练和评价的设备,cpu、gpu(cuda)或者tpu。 -
results: 模型的评价结果,以dictionary的形式存在 -
args: 用于training和evaluation的参数dict,形如args={'reprocess_input_data': True, 'overwrite_output_dir': True}) -
cuda_device(可选) : 默认为 -1. 用于指定使用哪个GPU
-
model_type: (必须) str - 使用的预训练模型的类型,当前支持BERT、RoBERTa、XLNet、XLM、DistilBERT、ALBERT、CamemBERT、XLM-RoBERTa、FlauBERT -
model_name: (必须) str - 预训练模型的名称或者本地模型所在路径(其中的模型文件必须为pytorch_nodel.bin) -
num_labels (可选): 数据集中类别的数量 -
weight (可选):长度为num_labels(标签数量)的列表,其中包含要分配给每个标签以进行损耗计算的权重数值。 -
args: (可选) dict - 参数字典,形如args={'reprocess_input_data': True, 'overwrite_output_dir': True}) -
use_cuda: (可选) bool - 默认为 -1. 用于指定使用哪个GPU class methods -
train_model(self, train_df, output_dir=None, show_running_loss=True, args=None, eval_df=None)
-
result: 以Dictionary的形式呈现evaluation results. (即Matthews correlation coefficient, tp, tn, fp, fn) -
model_outputs: eval_df中每一行的模型输出列表 -
wrong_preds: 与模型的每个错误预测相对应的InputExample对象列表
# 对于多标签分类, 需要将标签的类别数传递给num_labels这个参数 ,这里是18个类,故num_labels = 18model = ClassificationModel("distilbert", r"C:\Users\gaochangkuan\Desktop\2020.03.06 简易预训练模型应用库simpletransformers-master\examples\text_classification\outputs\checkpoint-38000",num_labels=num_labels,args={"reprocess_input_data": True, # 对输入数据进行预处理"overwrite_output_dir": True} # 可覆盖输出文件夹)
开始模型训练。
# 许多应用都会得益于使用半精度来储存数据,然后用32位的单精度来处理这些数据。高级的GPU将会全面支持这种“混合精度”的计算,使用FP16计算将会获得比FP32和FP64更高的吞吐量,提高训练速度,但是在windows的环境下很难安装。。。model.train_model(train_df,args = {'fp16':False})
评测模型
import sklearnresult, model_outputs, wrong_predictions = model.eval_model(eval_df, acc=sklearn.metrics.accuracy_score,#f1 = sklearn.metrics.f1_score)
Converting to features started. Cache is not used.
HBox(children=(IntProgress(value=0, max=47784), HTML(value='')))
HBox(children=(IntProgress(value=0, max=5973), HTML(value='')))
{'mcc': 0.8127265339278473, 'acc': 0.8311987276075674, 'eval_loss': 0.5653575883700224}
4、测试实例
predictions, raw_outputs = model.predict(["武汉此次爆发的疫情对广大居民的生活造成了巨大的影响,并且蔓延到了全球其他地方",'宝宝在生产后的一个月内需要什么样的护理呢?','如何理解钟南山团队论文预测:如管控措施推迟 5 天,疫情规模将扩大至 3 倍?','做投行、行研、咨询等金融岗位,有没有什么好用的找数据技巧呢?','中医在失传吗?为什么后人始终达不到“医圣”张仲景的中医水平?','如何看待孙杨深陷嗑药丑闻?','四次霍乱,19世纪的英国人是怎么活下来的','无可复制的汪曾祺:淡泊,是人品,也是文品','朱自清:逛南京像逛古董铺子,到处有时代侵蚀的遗痕','伍迪艾伦回忆录《没啥关系》将问世 此前曾四处碰壁','宇宙的开端是深吸口气,然后屏住了呼吸|读书笔记','梁遇春:我失掉我的心,可是没有地方去找'])
Converting to features started. Cache is not used.
HBox(children=(IntProgress(value=0, max=12), HTML(value='')))
HBox(children=(IntProgress(value=0, max=2), HTML(value='')))
labels = le.inverse_transform(predictions)labels
array(['society', 'baby', 'tech', 'finance', 'regimen', 'entertainment',
'world', 'entertainment', 'history', 'sports', 'discovery',
'story'], dtype='<U13')
诗歌生成(可自动捕捉其中的韵律):
远看天上雨,晴空夜半明。夜来花气急,山近鸟声轻。
海南城北水,秋到几时行。草没山青处,人家有旧情。
海底云边雁,天涯雪里舟。山城何处是,愁绝旧时愁。
山色云低碧海潮,天河明月上层霄。人间不解长安路,谁与东陵一寸条。
海燕无双双鬓蓬,楚云何处是秦中。春来有意关心在,江水西风日夜红。
人生自古无何事,此地相逢不得知。不及江湖分白日,空余草木落寒丝。
人生自古谁无死,自昔天边一雁游。自说人心真地阔,何因老眼一溪流。
山色何时到水涯,一生犹有客来花。风烟雨急吹笙管,春梦人家不敢夸。
海棠无处觅仙凡,不是人间是老僧。但得一般供意气,只缘天上有清澄。
空山新雨湿征帆,犹忆江湖上客庵。万里烟波归路断,百年风月落人南。
海内如今已再成,无多尽是与天星。不知白雪山河上,谁念黄沙草塞亭。
海内如今二十年,春风一笑已成妍。自怜老病非吾事,未必先生不少年。
海内如今几日愁,更无一点是归休。西风欲问黄昏叟,满眼无情似故丘。
海山无处著行藏,白首生前有此郎。莫问吴侬无着处,夜来灯下对江乡。
海内如今老,人谁识姓名。如斯须是假,无不必由情。一日千金重,三朝六印轻。若能持节化,如意莫言行。
空山新雨后,古屋旧经中。远树千株翠,疏篱百亩丛。雨声喧燕子,日影动渔童。独向南山下,相忘亦一峰。
海陵风水旧京师,千古清声动绮帷。何以报君同一梦,共谈今日是多时。
海棠开尽小枝头,又见青春满四垂。一夜不关霜鬓绿,只愁流落几何为。
人机诗歌写作甄别:
对对联:
【上联】悠悠柳岸落红霞 【下联】寂寂春窗落絮声
【上联】悠悠柳岸落红霞 【下联】袅潺松阴披晚节
【上联】悠悠柳岸落红霞 【下联】郁郁荷塘映彩虹
【上联】漠漠水田飞白鹭 【下联】茫茫云路隐青山
【上联】漠漠水田飞白鹭 【下联】巍巍山嶂起金狮
【上联】悠悠柳岸落红霞 【下联】款款荷塘荡碧波
【上联】帝道真如,如今都成过去事 【下联】民心所向,自古都是往来人
【上联】帝道真如,如今都成过去事 【下联】人心不古,从此总是等闲时
【上联】旷古圣人才,能以逍遥通世法 【下联】平生名利事,自然淡泊得真如
【上联】旷古圣人才,能以逍遥通世法 【下联】大千世界外,可将清净结心期
【上联】公谊不妨私,平日政见分弛,肝胆至今推挚友 【下联】人生何足论?此时心怀坦荡,襟怀自古仰高风
【上联】公谊不妨私,平日政见分弛,肝胆至今推挚友 【下联】家声犹在耳,及时风闻噩耗,音容何处吊先生
【上联】公谊不妨私,平日政见分弛,肝胆至今推挚友 【下联】人间原是纸,吾意情犹激励,江山从古胜文章
【上联】公谊不妨私,平日政见分弛,肝胆至今推挚友 【下联】大才堪表率,一人家有贤达,勋名从此愧先师
【上联】公谊不妨私,平日政见分弛,肝胆至今推挚友 【下联】群英真可鉴,自古诗怀难表,山川何以泣高风
【上联】英雄作事无它,只坚忍一心,能成世界能成我 【下联】壮士凌云有志,纵风流万里,不负春秋不负人
【上联】英雄作事无它,只坚忍一心,能成世界能成我 【下联】人间多情至此,在消磨半句,可笑天伦最是家
【上联】英雄作事无它,只坚忍一心,能成世界能成我 【下联】佛道为人舍己,唯淡然我性,只是天仙亦是心
【上联】英雄作事无它,只坚忍一心,能成世界能成我 【下联】烈士捐躯有此,剩威灵万丈,不过江湖不在人
【上联】庭院深深深几许,杨柳堆烟,帘幕无重数 【下联】池塘浅浅浅三分,鱼虾戏水,荷花别样红
【上联】庭院深深深几许,杨柳堆烟,帘幕无重数 【下联】池塘浅浅浅三分,鸳鸯戏水,江天一色秋
【上联】雨横风狂三月暮,门掩黄昏,无计留春住 【下联】云开雾散一天晴,窗含翠色,有时送夏来
【上联】雨横风狂三月暮,门掩黄昏,无计留春住 【下联】云开雾散一天晴,树遮红日,有时送夏来
【上联】雨横风狂三月暮,门掩黄昏,无计留春住 【下联】天高云淡一江秋,舟横野渡,有人载酒归
【上联】庭院深深深几许,杨柳堆烟,帘幕无重数 【下联】池塘浅浅浅三分,芙蓉出水,风光别样清
【上联】漠漠水田飞白鹭,阴阴夏木啭黄鹂 【下联】幽幽小院落红梅,淡淡清香醉绿蚁
诗歌解读:
【诗句】问君何事轻离别,一年能几团圆月。杨柳乍如丝,故园春尽时。
【解释】你在什么时候才能够回家?只有那美丽的桃花已经过去了。
【诗句】问君何事轻离别,一年能几团圆月。杨柳乍如丝,故园春尽时。
【解释】请问我为什么轻易地离别?一年能有几次圆满的月亮。杨柳刚刚长出细丝,家乡已经是春天过去之时了。
【诗句】沅湘两水清且浅,林花夹岸滩声激。洞庭浩渺通长江,春来水涨连天碧。
【解释】沅江两岸的流淌在这里是多么高远呢?树丛生的野草和小洲环绕着江面,河畔的波涛好像是那样宽阔无际;春天来了时节,水面上涨起伏着一片青色。
【诗句】沅湘两水清且浅,林花夹岸滩声激。洞庭浩渺通长江,春来水涨连天碧。
【解释】沅江两岸的流淌着一片清澈的江水清澈,茂密的树林环绕在河岸上。洞庭湖广阔无际,春水滔滔不断地流向远方。
【诗句】沅湘两水清且浅,林花夹岸滩声激。洞庭浩渺通长江,春来水涨连天碧。
【解释】潇湘两岸的流淌着一片清澈的水,树林间的花瓣随风飘荡。洞庭湖广阔无际,波涛汹涌,波光粼粼,好像是天空相接
【诗句】南湖秋水夜无烟,耐可乘流直上天。且就洞庭赊月色,将船买酒白云边。
【解释】秋天夜晚的南湖面,清澈的江水,可以清澈见底没有烟波直通银河岸上,那么可以乘着小舟到达洞庭湖边去游览。这时候我要把洞庭湖边赏识月色的景致,一定要在白云之中买下来买酒,与白云相伴而行。

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




